这次的debug案例来自于朋友的一个问题,Embedding层的前向和反向速度是否会随着token的增多而增加呢?本文对这个问题进行讨论。
前言
这次的debug案例来自于朋友的一个问题,Embedding层的前向和反向速度是否会随着token的增多而增加呢?本文对这个问题进行讨论。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢 。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号: 机器学习杂货铺3号店

前几天土豆收到朋友的一个问题,问题内容如下图所示。这个问题理解起来不难,对于一个Embedding层来说,token的数量会影响前向和反向的速度吗?我们接下来看看土豆的分析和一些试验。

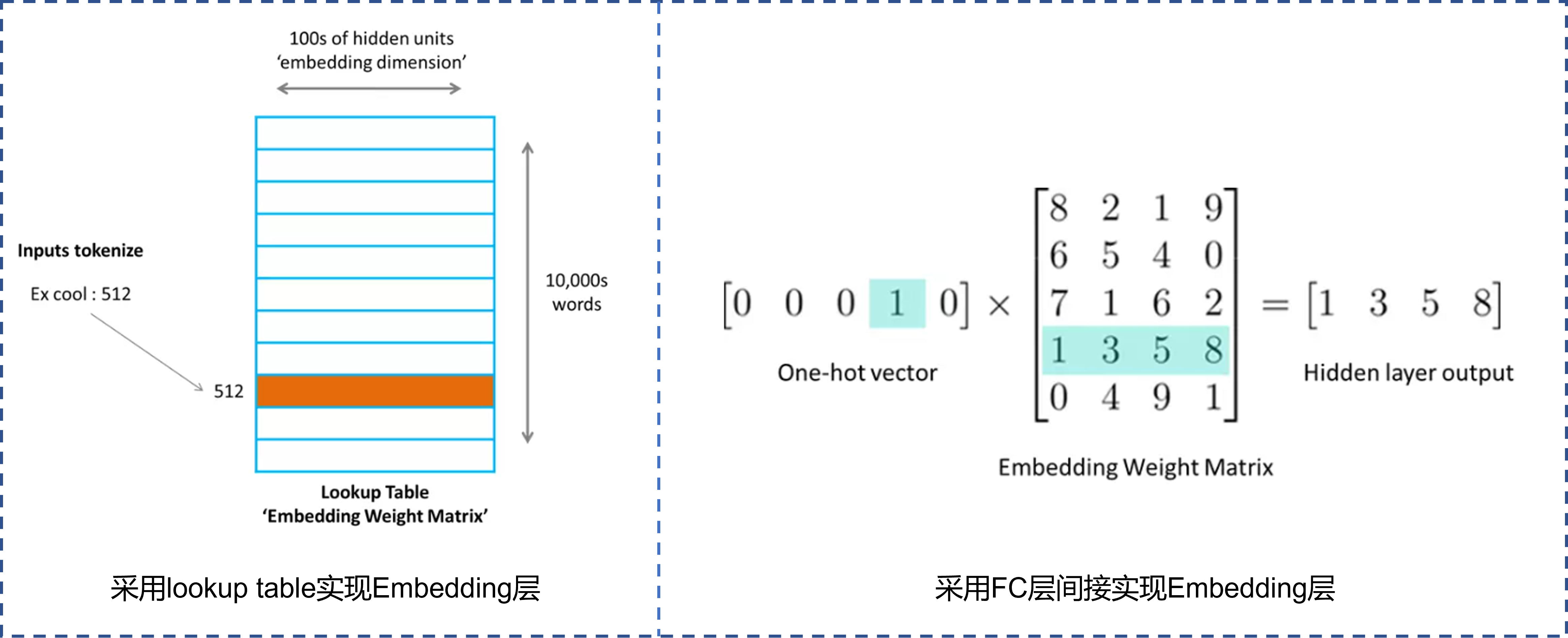
这个问题从直观上看,Embedding层的前向和反向过程是不会收到token数量的影响的,除非token实在太多导致内存占用太大,不断地出现缺页异常导致换页,从而影响访存速度。问题中有1000w个token,按照维度768,float32类型计算,也就30多G内存,对于服务器而言不算太多。而Embedding层我们都知道,可以通过两种方式实现,如Fig 1. 所示,通常来说我们可以考虑采用对Lookup Table查表的方式,将ID对应的某一行取出就得到了该ID的Embedding。还可以将这个ID转化为one-hot编码向量,矩阵乘以Embedding参数矩阵后,也可以得到该ID的Embedding。
对于查表的方式得到的Embedding,由于整个过程只需要对ID对应的某一行进行检索,因此计算复杂度是
- 他采用FC层进行one-hot向量矩阵乘法的方式实现Embedding,但是在这种情况下,前向过程和反向过程应该会同步增加耗时,不会存在“反向过程比前向过程两倍还多”的情况。
- 他采用查表的方式实现Embedding,但是由于某种未知的框架机制,导致了题目中的情况,即计算耗时随着token数量增加而增加,并且反向传播耗时明显比前向传播耗时长。
为了验证这两种假设,我们得进行试验,让我们开始撸代码跑实验吧~
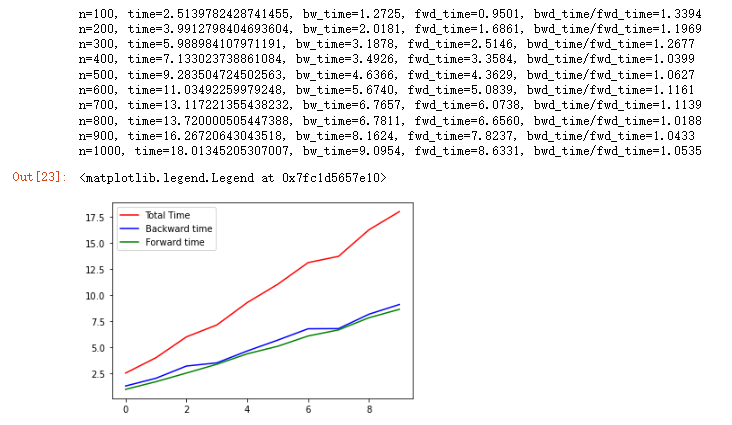
首先,我们采用FC层进行Embedding的耗时试验,代码如Append Code A. 所示,从实验中我们发现,随着token数量n的逐步增加(100 -> 5000),其总耗时time(前向+反向)呈现线性上涨(红色曲线),而前向(fwd_time)和反向(bwd_time)也呈现线性上涨,但是其反向时间/前向时间(bwd_time/fwd_time)的比例基本维持在1,因此并不会出现朋友问题中的那种情况,可以初步排除是采用FC层进行Embedding提取的可能性。
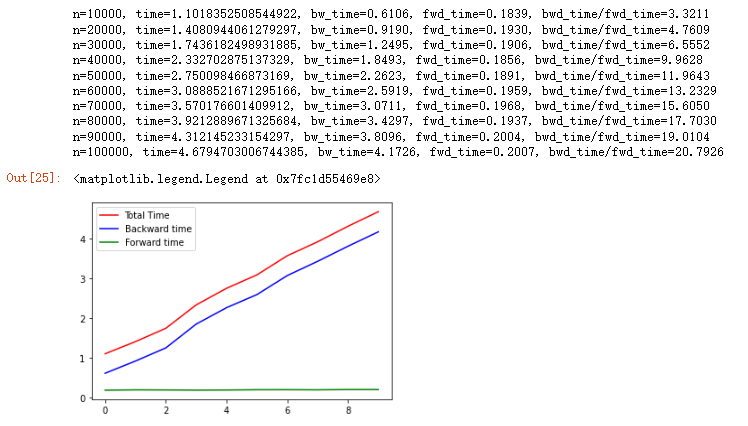
那么可以初步判断朋友是采用查表的方式实现的,我们用Appendix Code B.的代码进行验证。我们可以发现,总耗时同样随着token数量增加而线性上涨,但是前向时间却保持恒定(~0.2s),而反向耗时则随着token数量增加而线性上涨,反向耗时/前向耗时同样呈现线性上涨,这个现象满足朋友的描述。可以断定朋友是采用了类似于Appendix Code B.的代码进行模型训练的。
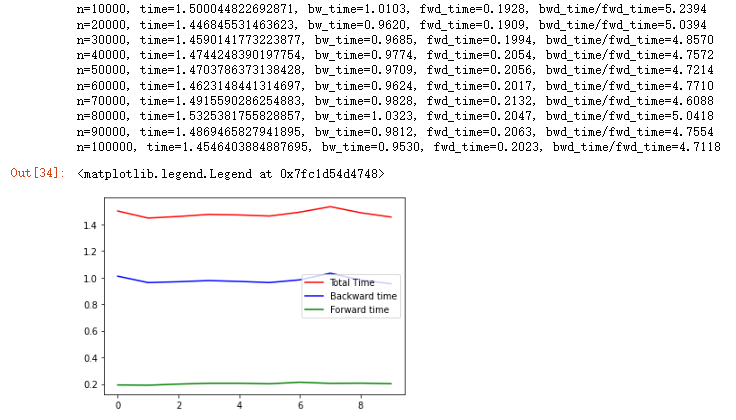
这个和土豆之前的想法有部分矛盾,首先其前向过程的确是计算复杂度为

怎么解决呢?我们看到pytorch的nn.Embedding层中有个叫sparse的参数,这个参数如果指定为真,则表示梯度对于权重矩阵而言,以稀疏矩阵的方式进行,此时梯度是稀疏的,将只考虑有效的ID对应行的权重矩阵的梯度更新,此时那些为0.0的梯度就不会再被参与反向传播计算了,从而将计算量维持在

让我们用Appendix Code C.的代码进行试验,我们发现此时无论是前向耗时,还是反向耗时都是
Appendix
Code A. 采用FC层进行Embedding的耗时试验
1 | import torch |
Code B. 采用查表的方式进行Embedding的耗时试验
1 | import torch |
Code C. 采用稀疏梯度之后的耗时试验
1 | import torch |