本文讲解hinge loss高效的一种实现方法。
hinge loss是一种常用损失[1],常用于度量学习和表征学习。对于一个模型pointwise形式的监督学习,通过交叉熵损失进行模型训练,也即是如式子(1-1)所示。
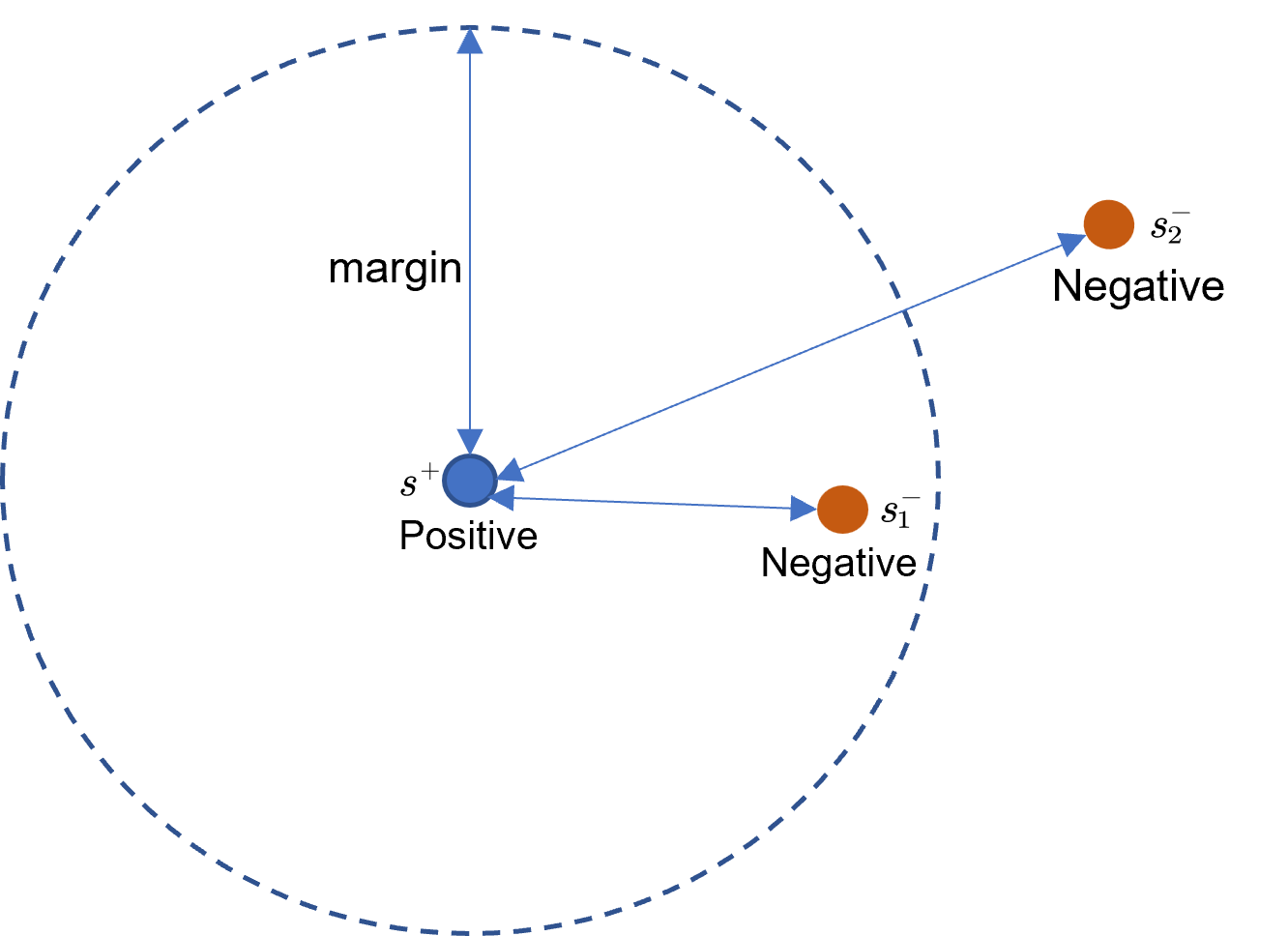
从实现的角度出发,我们通常可以采用下面的方式实现,我们简单介绍下其实现逻辑。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import torch
import torch.nn.functional as F
margin = 0.3
for data in dataloader():
inputs, labels = data
score_orig = model(inputs) # score_orig shape (N, 1)
N = score_orig.shape[0]
score_1 = score_orig.expand(1, N) # score_1 shape (N, N)
score_2 = torch.transpose(score_1, 1, 0)
label_1 = label.expand(1, N) # label_1 shape (N, N)
label_2 = label_1.transpose(label_1, 1, 0)
label_diff = F.relu(label_1 - label_2)
score_diff = F.relu(score_2 - score_1 + margin)
hinge_loss = score_diff * label_diff
...
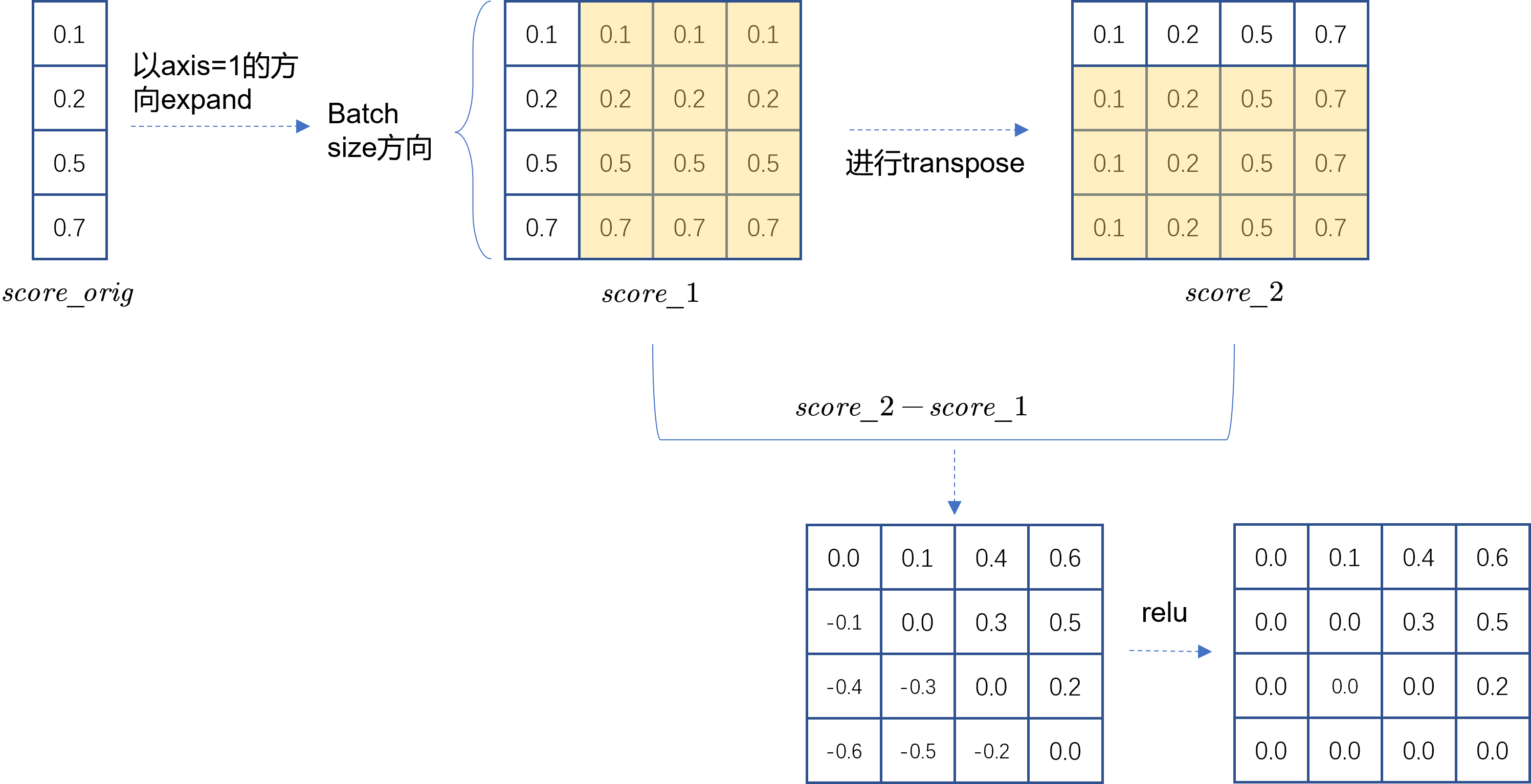
为了实现充分利用一个batch内的样本,我们希望对batch内的所有样本都进行组pair,也就是说当batch size为expand和transpose这两个操作,如Fig 2.所示,通过这两个操作产出的score_1和score_2之差就是batch内所有样本之间的打分差,也就可以认为是batch内两两均组了pair。
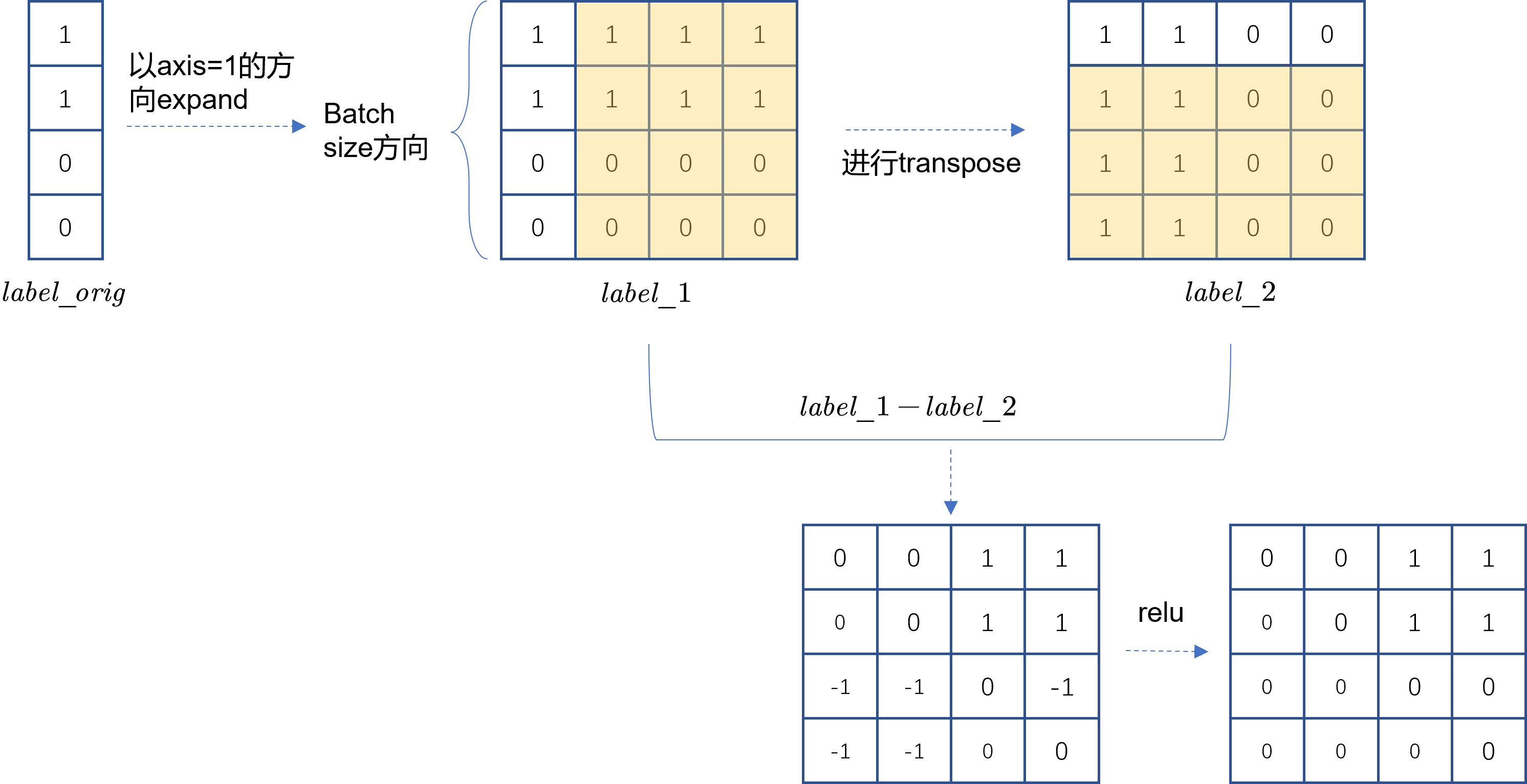
与此相似的,如Fig 3.所示,我们也对label进行类似的处理,但是考虑到偏序已经预测对了的pair不需要产生loss,而只有偏序错误的pair需要产出loss,因此是label_1-label_2产出label_diff。通过F.relu()我们替代max()的操作,将不产出loss的pair进行屏蔽,将score_diff和label_diff相乘就产出了hinge loss。
即便我们的label不是0/1标签,而是分档标签,比如相关性中的0/1/2/3四个分档,只要具有高档位大于低档位的这种物理含义(而不是分类标签),同样也可以采用相同的方法进行组pair,不过此时label_1-label_2产出的label_diff中会出现大于1的item,可视为是对某组pair的loss加权,此时需要进行标准化,代码将会改成如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import torch
import torch.nn.functional as F
margin = 0.3
epsilon = 1e-6
for data in dataloader():
inputs, labels = data
score_orig = model(inputs) # score_orig shape (N, 1)
N = score_orig.shape[0]
score_1 = score_orig.expand(1, N) # score_1 shape (N, N)
score_2 = torch.transpose(score_1, 1, 0)
label_1 = label.expand(1, N) # label_1 shape (N, N)
label_2 = label_1.transpose(label_1, 1, 0)
label_diff = F.relu(label_1 - label_2)
score_diff = F.relu(score_2 - score_1 + margin)
hinge_loss = torch.sum(score_diff * label_diff) / (torch.sum(label_diff) + epsilon) # 标准化处理,加上epsilon防止溢出
...
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/103995962, 《一文理解Ranking Loss/Contrastive Loss/Margin Loss/Triplet Loss/Hinge Loss》