公司内部用的LTR(Learning To Rank)平台能够对树模型的特征依赖进行曲线绘制,其中绘制的原理没能从内部文档中找到,只是大概知道这个特征依赖曲线能够反应树模型中每个特征的输入输出响应。后面在和同事的交流中渐渐发现了一些端倪,后经过调研后初步得到一些结论,本文简单笔记之。
前言
公司内部用的LTR(Learning To Rank)平台能够对树模型的特征依赖进行曲线绘制,其中绘制的原理没能从内部文档中找到,只是大概知道这个特征依赖曲线能够反应树模型中每个特征的输入输出响应。后面在和同事的交流中渐渐发现了一些端倪,后经过调研后初步得到一些结论,本文简单笔记之。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店
本文试验代码库: https://github.com/FesianXu/FeatureDependencyAnalysisDemo

特征依赖分析(Feature Dependency Analysis)对于模型分析而言至关重要,对于注重可解释性的工业界应用更是如此。对于一个模型,一般会有多个输入,这些输入对于整个模型输出结果的影响程度是各不相同的,比如对于银行客户违约预测模型而言,可能该用户的历史违约行为输入对于模型输出违约的影响最大。对于某个模型而言,我们希望可以分析出哪些特征对其输出的影响最大,而这种分析是一种全局的模型无关的分析(Global model-agnostic),也就是说
- 全局(Global):意味着这个分析是以整个模型为单位进行的,给定一定数量的目标样本集,我们从样本集的宏观角度,去评估某维特征对于模型的影响。如果期望给定一个样本,然后评估这个样本的某维特征的影响,这是全局分析做不到的。
- 模型无关(Model-Agnostic):意味着这种分析是适用于所有模型的,并不是某个模型(比如树模型)所独有的。
以下介绍几种常用的方法,可用于分析模型的特征依赖。
部分依赖曲线(Partial Dependency Plot)
部分依赖曲线(Partial Dependency Plot, PDP)就是这样一种用以评估某维特征对于模型输出影响的可视化分析方法,而且这种方法也是全局的模型无关的。总体而言,这个方法会对模型输入的
Fundamental Assumption: 模型的输入都是独立无关的。
在满足这个假设的前提下,假如我们已经训练好了某个模型
注意到这个方法描述的是模型在整个数据集的维度,当其他维度特征不变的情况下,待分析特征的平均输入输出响应曲线。笔者准备了一些例子,具体见[5]的partial_dependency_plot_demo.ipynb,这里简单进行说明,在本例子中采用的是sklearn.dataset中的boston房价预测数据集,boston['data']大小为boston['target']是这506个样本的真实房价。一共有13维特征可供部分依赖曲线分析,我们优先选择哪个或者哪些进行呢?我们可以通过特征权重(也称之为特征重要性)进行筛选,特征权重可以通过树模型的分裂增益进行统计,也可以通过改变某个特征的排序,计算指标的diff大小进行统计,具体的方法我们以后博文再聊。如Fig 1.1所示,其中的Feature Importance就是通过分裂增益统计的特征权重排序,而Permutation Importance就是乱序某维特征排序统计出来的特征权重排序。从中我们可以发现,第12和第5维特征是最为重要的特征,我们尝试对这两维特征的PDP进行绘制。

如Fig 1.2所示,笔者在(a)和(b)分别绘制了第12维特征和第5维特征的PDP曲线,同时绘制了联合第12维和第5维的2维PDP曲线,如(c)所示。2维PDP曲线将式子(1-1)中的
- 权重高的特征,其输入对于输出的影响都是较为递增/递减的,整体趋势比较统一。
- 权重高的特征,的输出响应范围大,比如(a)的能从-6到8,峰值差达到了14,(b)的范围从-2到8,峰值差达到了10。
- 权重高低与否,与PDP曲线是递增趋势或者递减趋势无关。
部分依赖曲线的趋势只能代表该特征从平均的角度,给模型的输出带来的影响是正向的亦或是负向的,并不能决定这个权重的重要与否。权重的重要性高低从PDP曲线中,更应该从打分峰值差距中判断,能打出更大峰值差距的特征会倾向于更重要。如Fig 1.2 (a)所示,第12维特征是递减趋势的特征,但是其特征权重确是最高的。我们理解这维特征的时候,应该理解为该特征在对整个模型的输出上有着显著的影响,这体现在对模型的输出能产生更大范围的影响,但是这个影响从预测打分的角度而言是负向的。只要我们将第12维特征取个相反数,如Fig 1.2 (d)所示,我们就能发现第12维特征的趋势会变成递增,但是此时特征权重没有任何变化。同理的,第5维特征也是如此,如Fig 1.2(b)所示,只是该特征对于模型输出而言是正向的,意味着特征值越大,模型输出倾向于越大。

为了继续验证这个观点,我们对其他维度(0,2,6,9,10,11维)的特征进行了PDP曲线绘制,如Fig 1.3 (a)-(f)所示,我们发现这些权重不高的特征,其打分峰值差约为1.4,0.8,2,2,2.5,1.4,的确比第12和第5维的特征打分峰值差低很多。同时,我们也能发现,在以下的PDP曲线中存在很多特征的模型输出趋势是较为动荡的,如(a)、(b)、(d)。这类型的特征对于模型输出来说,通常具备较高的非线性,由于PDP曲线表示的平均值的关系,如果某个区段中平均值之间有着距离的波动,那么很可能其样本中,该特征在这个区段的影响方差也很大,这样在线上很容易导致一些bad case,需要着重分析和考虑。这类型的区段见Fig 1.3中的红线虚框。
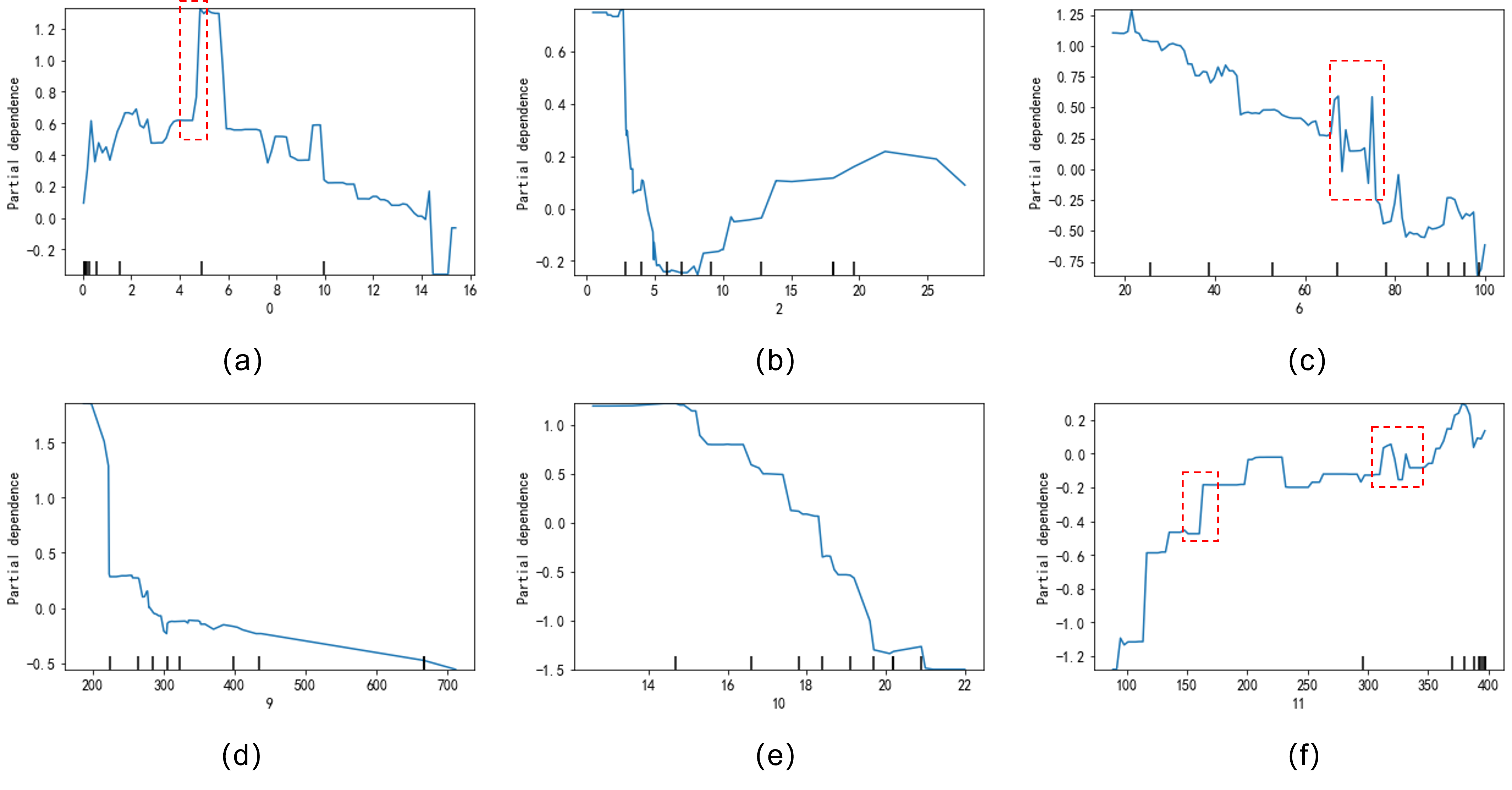
PDP曲线虽然能描述某维模型特征,对于模型输出的全局、模型无关的依赖分析,方法直观而且简单,但是具有以下缺点。
- 1、PDP曲线最多只能分析到2维的联合特征分析。如Fig 1.2(c)所示,PDP通常只能对一维特征和两维特征进行特征依赖分析(因为高于2维将无法进行可视化);
- 2、PDP曲线计算代价高。对于某维特征而言,其中的某个值
的对应 需要进行 次模型打分计算,对于一个具有 中可能取值的特征而言,其模型计算复杂度就是 ,对于 个特征而言就是 ,其复杂度还是很高的。 - 3、PDP曲线依赖于特征间独立无关的假设。通常数据的特征之间都不会是独立无关的,这意味着我们在遍历某特征的可能取值的时候,可能会出现“不合理”的情况。举个例子,假设某个特征
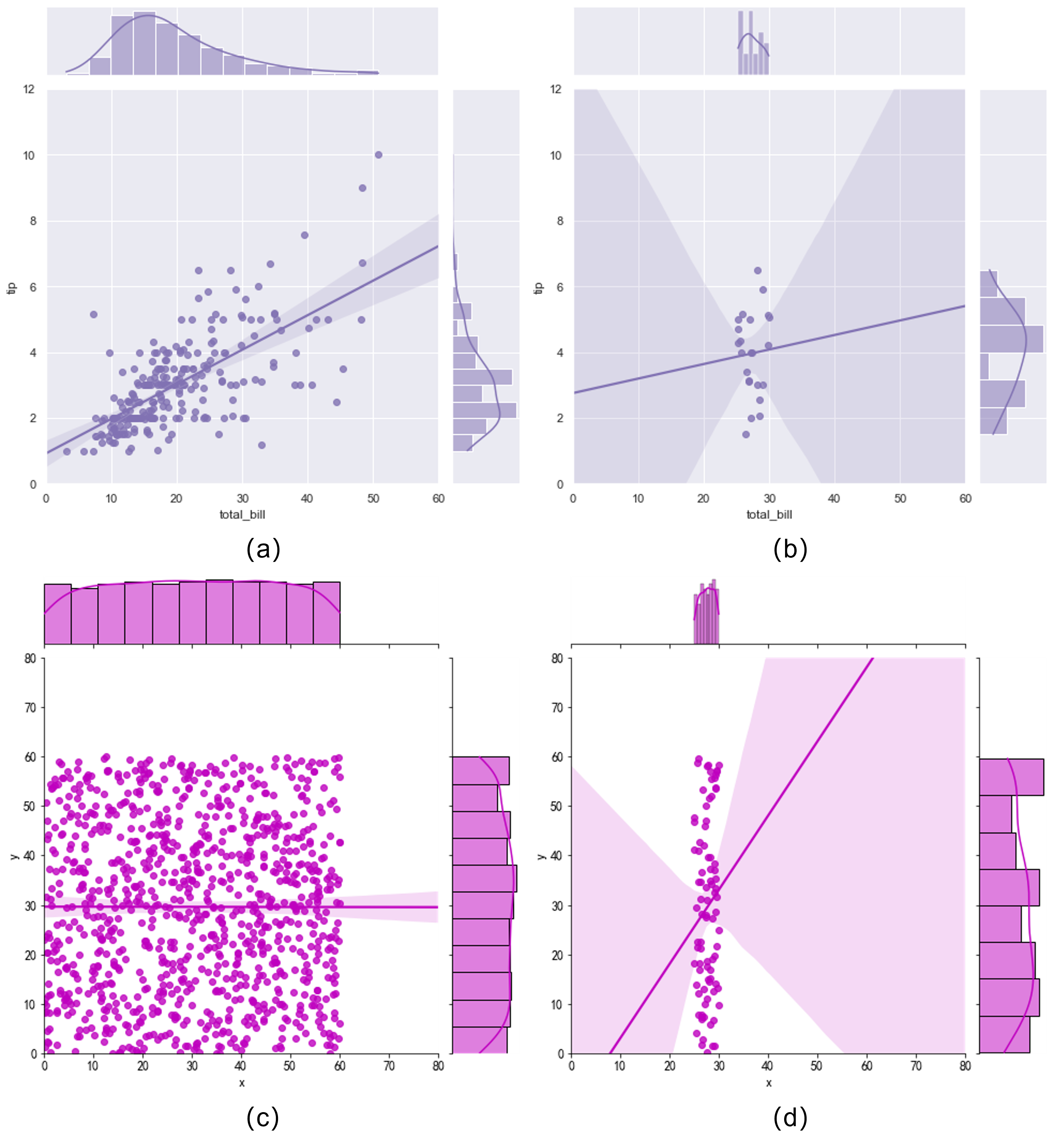
和某个特征 的关系为 ,显然这两个特征是相关的。如果此时对特征 进行PDP绘制,那么会遍历 的所有可能取值范围,比如是 range(0,100,0.5),作为被看成独立无关的特征是需要被固定的,此时会出现个“诡异”的情况,当 遍历到20的时候, 可能为10(因为固定 特征),这违背了 。显然,对于非独立无关的数据而言,PDP的绘制策略将会遍历到一些不可能存在的数据点,这会导致绘制出来的点不置信。 - 4、PDP曲线可能隐藏了数据里面的隐藏模式。由于有PDP曲线只是对平均值进行计算,这种全局方法可能导致一些数据中模式被隐藏。举个例子,假如对于某个特征而言,数据集中有一半数据是模型输出和输入特征正相关,一半数据是模型输出和输入特征负相关,这平均来看,最终PDP的结果可能是绘制出一个直线!显然这不是我们期望的。解决方案是采用独立条件期望曲线(Individual Conditional Expectation curve, ICE)[6]进行分析,这个属于局部模型无关模型,我们以后再聊。
以上的第3点可以用Fig 1.4举例,假设total_bill为随机变量
条件依赖曲线(Marginal Plot)
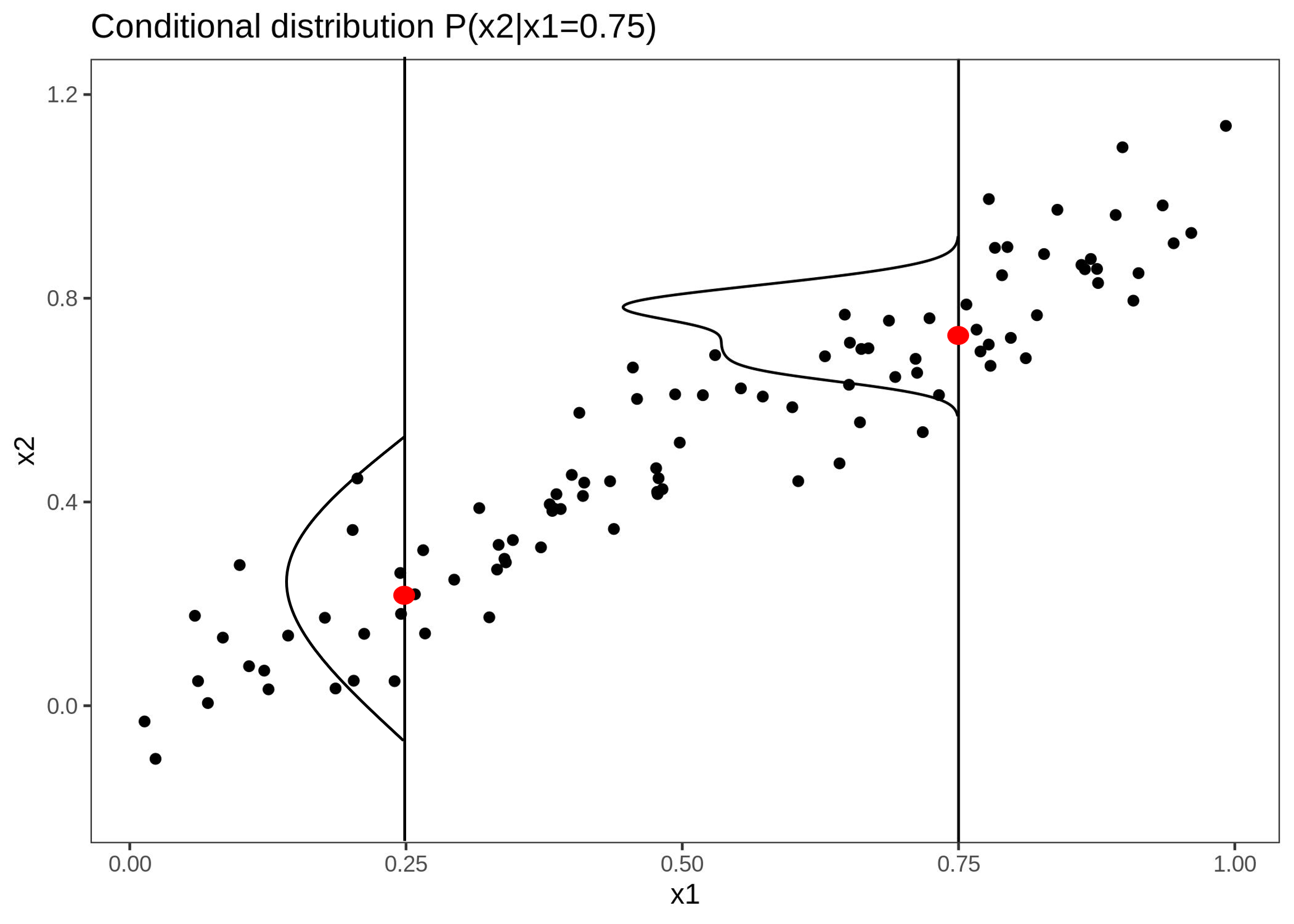
部分依赖曲线强烈依赖于特征之间独立无关的假设,然而现实生活中的模型输入特征间无法保证都是独立无关的,怎么解决这个问题呢?我们可以对条件分布进行求平均,而不是对边缘分布进行求平均,这个方法称之为条件依赖曲线(Marginal-Plot,M-Plot),通过这种方法我们可以避免对现实中不可能存在的数据点进行求平均。当然,在实际中我们通常是对某个区间内的所有数据点进行求平均,用公式表示如式子(2-1)所示。
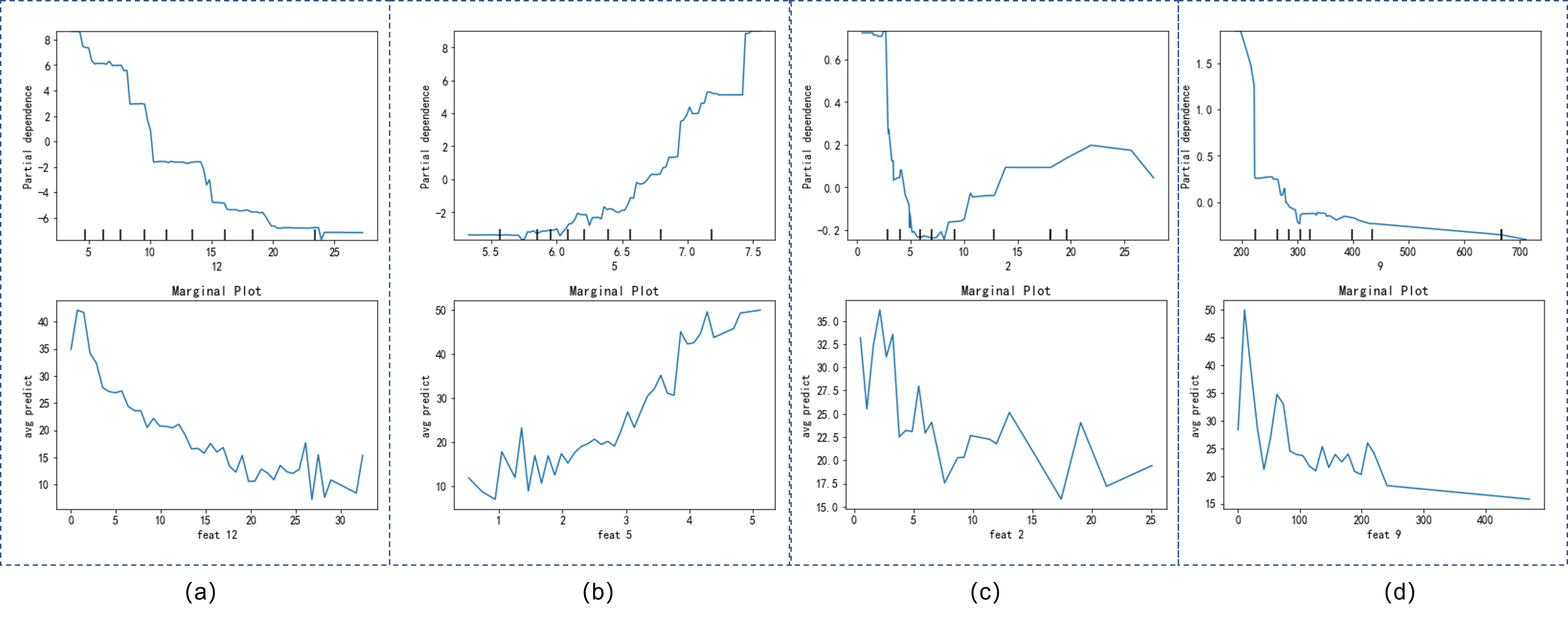
根据本章对Marginal-Plot的介绍,我们尝试对上一章的Partial Dependency Plot的图示进行对应的Marginal-Plot的绘制和对比,采用的代码见Appendix Code C.,绘制结果如Fig 2.2所示。我们可以发现几点区别:
- 对于第12维和5维特征而言,采用Mplot和PDP的方法绘制出来的曲线趋势一致,但是对于第2和9维特征而言则有比较大的区别。
- Mplot和PDP的打分范围差别很大。
这两点很好理解,由于PDP会网格遍历某维特征取值范围内的所有取值,那么就可能会取得一些真实数据中不可能存在的数据点,导致取平均后打分有偏差。这个会导致在PDP曲线中出现一些突变,或者打分范围和真实的打分范围有所偏差。Mplot对比PDP有很多优势,比如其计算速度更快(不需要进行网格遍历),避免对不可能存在的数据点进行求平均导致绘图不置信等等,但是其还是会受到特征之间存在依赖关系导致的“依赖传递”的影响。
为了解决这个问题,我们可以继续探索Accumulate Local Estimate(ALE)累计局部估计,我们后文见。
Reference
[1]. https://christophm.github.io/interpretable-ml-book/pdp.html, Partial Dependence Plot (PDP)
[2]. https://zhuanlan.zhihu.com/p/428466235,
[3]. https://christophm.github.io/interpretable-ml-book/ale.html, Accumulated Local Effects (ALE) Plot
[4]. https://scikit-learn.org/stable/modules/partial_dependence.html, Partial Dependence and Individual Conditional Expectation plots
[5]. https://github.com/FesianXu/FeatureDependencyAnalysisDemo
[6]. https://christophm.github.io/interpretable-ml-book/ice.html#ice,Individual Conditional Expectation (ICE)
Appendix
Code A. 非独立无关下,条件分布和边缘分布的分布差别
1 | import seaborn as sns |
Code B. 独立无关下,条件分布和边缘分布的分布差别
1 | import numpy as np |
Code C. 绘制Marginal-Plot的代码
1 | def draw_marginal_plot(data, feat_axis, num_parts): |