最近有需求对特征进行稀疏编码,看到一篇论文VQ-VAE,简单进行笔记下。
前言
最近有需求对特征进行稀疏编码,看到一篇论文VQ-VAE,简单进行笔记下。如有谬误请联系指出,本文遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢 。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

图片,视频等视觉模态有充足的冗余信息,可以通过稀疏编码进行编码,以减少储存消耗。Vector-Quantised Variational AutoEncoder (VQ-VAE) 就是进行图片稀疏编码的工作[1]。 如Fig 1. 所示,VQ-VAE有三大部分组成,Encoder,Decoder和储存稀疏编码的Embedding Space字典。其中的Embedding space字典的形状为
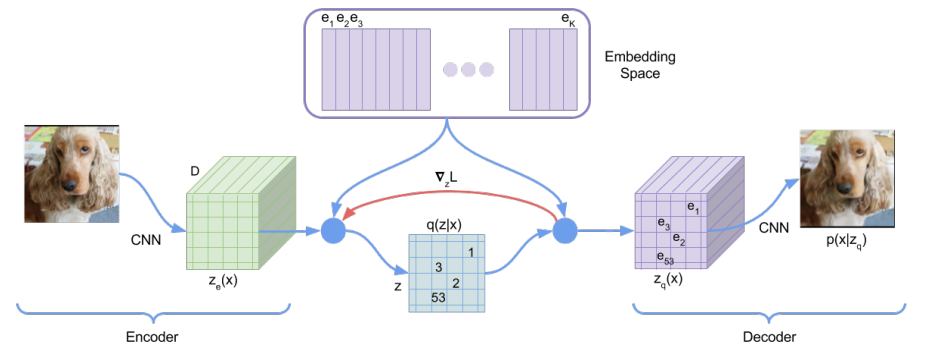
单从稀疏编码的角度看,如Fig 2.所示,整个工作中,将会考虑将中间特征图的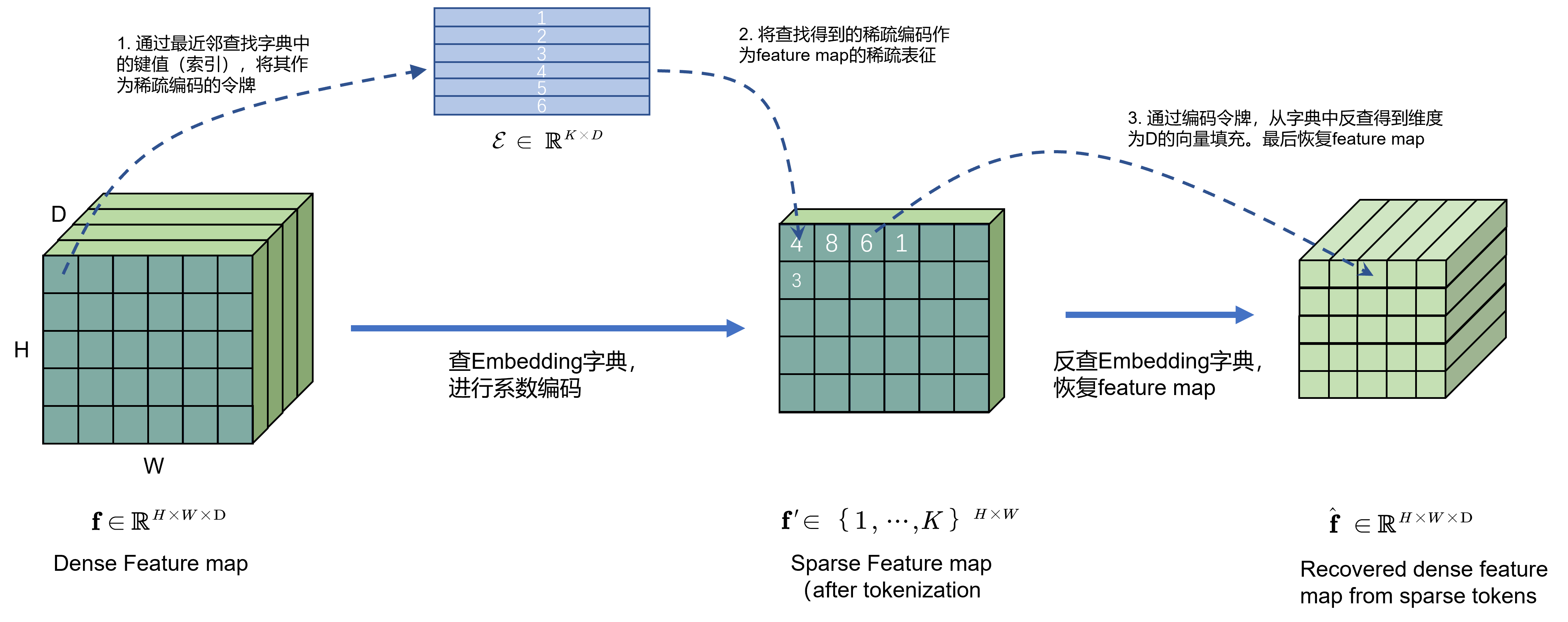
整个框架中有若干参数需要学习,分别是encoder,decoder网络参数和Embedding space字典的参数。然而稀疏编码的过程由于出现了最近邻方法,这个过程显然是无法传递梯度的,为了实现编码器的更新,可以考虑将解码器的梯度直接拷贝到编码器中。假设对于编码后恢复的
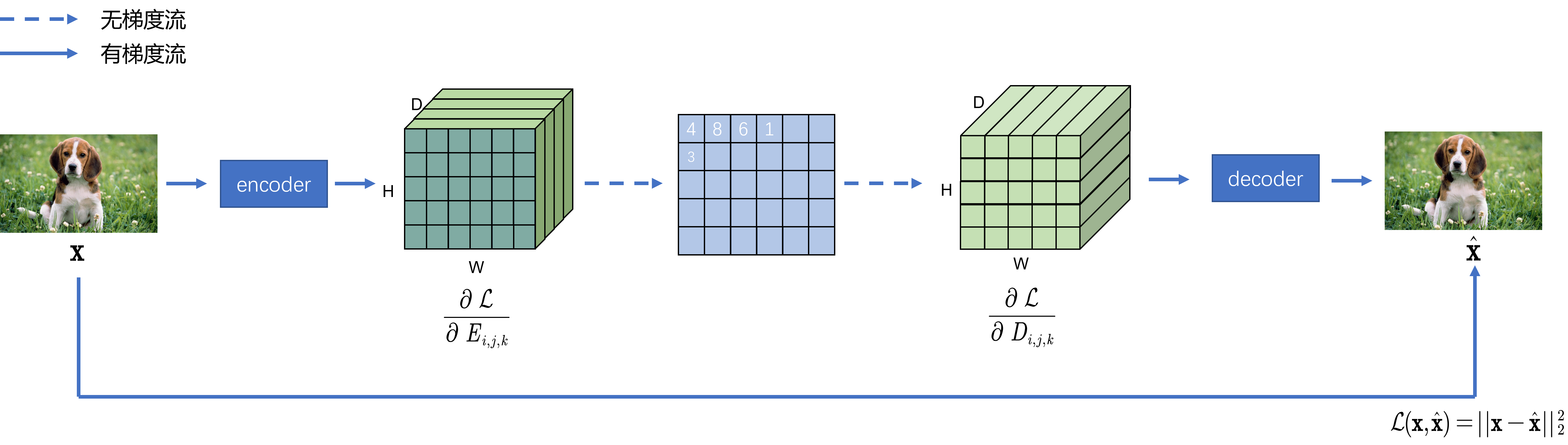
最后的损失函数如(1-3)所示,其中的
作者在原论文中贴了不少图片稀疏编码的结果,如Fig 4.所示,将

Reference
[1]. Van Den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in neural information processing systems 30 (2017).