笔者在百度实习的过程中,从零开始开始学习了一些关于信息搜索系统的知识,觉得受益匪浅,在此笔记,希望对读者有所帮助。
前言
笔者在百度实习的过程中,从零开始开始学习了一些关于信息搜索系统的知识,觉得受益匪浅,在此笔记,希望对读者有所帮助。本文只是科普向,如有谬误请联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

什么是搜索系统
信息之海浩瀚无穷无尽,要想从中有效地搜索出我们需要的信息,需要我们设计一套有效的信息搜索系统(information retrieval system)。我们期望这个系统能够对我们的检索请求进行响应,从海量信息中检索出能够解决我们疑问的,我们需要的信息。作为用户,我们对这个搜索系统的输入通常是一串字符串,我们称之为检索词(Query),而该系统会返回一系列的文档(Doc),这些文档既可以是网页,也可以是视频,音频等等多媒体信息。当然,从直观上说,我们当然希望返回的文档和我们用户潜在的检索意愿越相近越好,此处的相近可以简单理解为Query和Doc的相关性。相关性是信息搜索系统最基础的指标,从最朴素的角度来说,我们搜索系统返回的Doc可以按照相关性降序排序。当然,相关性并不是搜索系统的唯一指标,作为一款合格的商业搜索系统,我们还需要考虑检索出的Doc的时效性,信息具有时效性,我们当然希望检索出来的信息是最新的。同时,我们希望检索出的Doc具有权威性,比如对于一些专业知识领域的检索,医学,法律,电子技术等等,我们希望检索出来的Doc是来自于权威网站或者权威作者的。在一些垂直信息搜索领域,比如图片搜索,视频搜索等,我们还希望搜索出来的结果尽可能是高清的,这些可以归在Doc的质量上。为了公司产品的运营需求,使得搜索结果符合法律法规,我们通常还需要对检索Doc进行违法违规内容打压,比如涉黄涉暴的敏感信息必须得到打压。在基于Query和Doc的诸多考虑之后,我们需要量化这里指标,比如对相关性,权威性,时效性,质量,信息打压等等进行量化,然后用模型进行多指标打分。根据这个打分对所有的Doc进行降序排序,将整个排序结果返回呈现给用户,这就完成了一次检索过程。这个过程并不完整,我们通常还会考虑点击模型,对每个Doc的用户点击数量进行预测,结合这些指标进行上层排序。
当然这是一个极度简化了的信息检索过程,在更为实用的系统中,为了实现检索的准确,全面,高效等,需要更为细致的算法策略设计和架构设计保驾护航。总体来说,大多数信息检索系统可以分为以下几个阶段:
信息爬取:我们通过大规模的爬虫,从各个网站中爬取各种连接,然后将其储存到数据库中,为了保证检索的高效,我们按照爬取网页的质量可以将整个数据库进行分层次排序,将检索流量尽可能的往着最高质量的资源上引导,这样我们就能在保证结果高质量高相关的情况下,又能保证检索过程的高效完成。
Query分析: 为了实现Query和Doc的相关性匹配,首先我们要能够从Query中分析用户的潜在检索需求,这一点和自然语言处理(NLP)密切相关,因为Query通常是以字符串的形式体现的。Query分析包括了很多东西,包括对Query的切词,纠错,补充,需求识别,Query改写等等。
信息召回(information recall):指的是从海量的,数以亿计的数据中找到和Query分析后的结果相关性较为接近的结果。在这个阶段需要控制召回doc的粒度,如果召回doc过多则容易给之后的doc排序造成性能影响;如果召回doc过少,则很容易导致漏掉某些相关的doc,也既是召回不全面。通常我们用召回率和精准率衡量召回结果。
排序(doc rank):在召回了充分的doc之后,就可以对这些doc进行排序了,排序的基本要求就是query-doc相关性,同时需要满足其他各种商业,运营的要求。排序按照排序的粒度,可以分为粗排和精排。
信息爬取
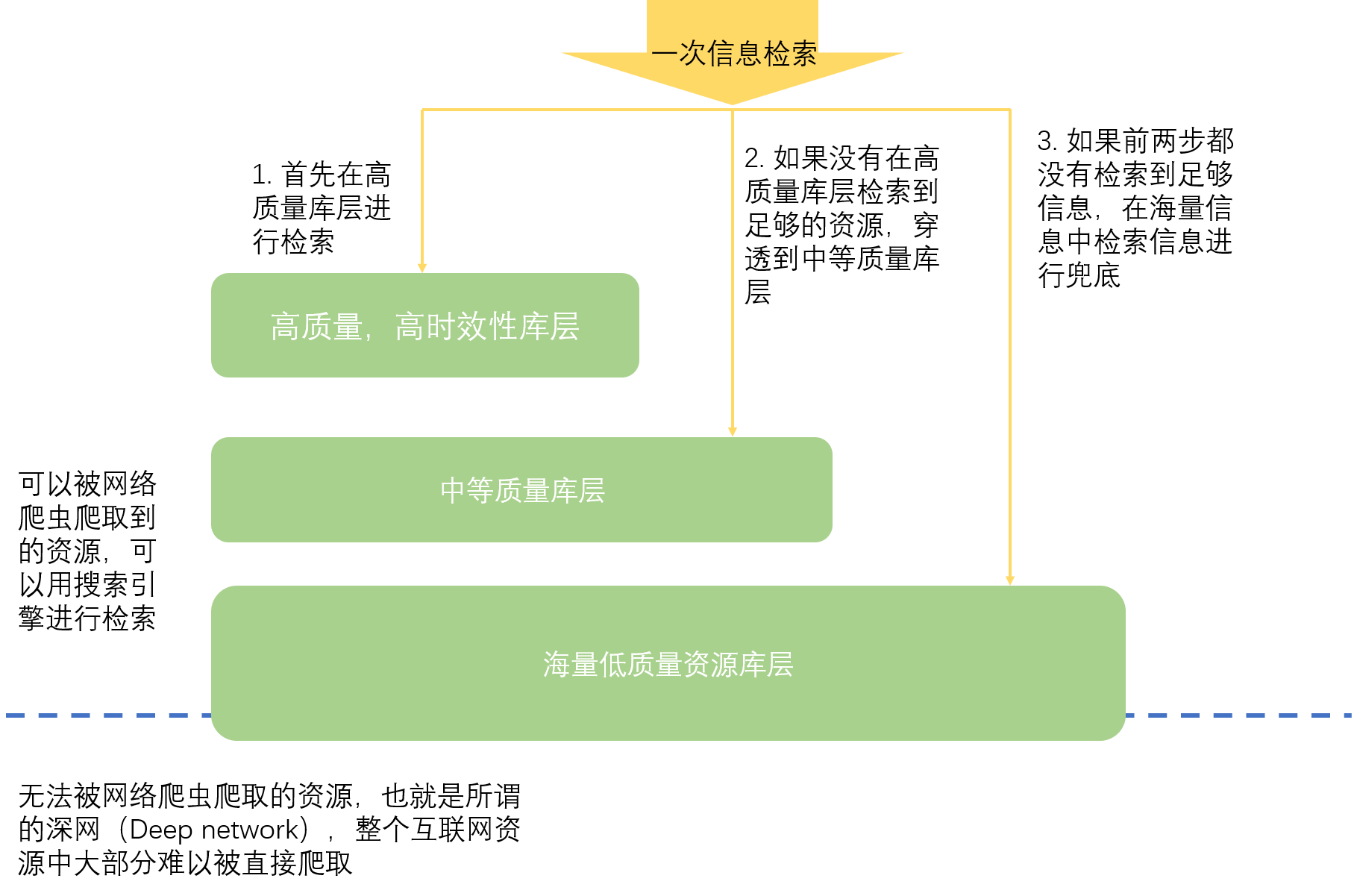
信息爬取通过网络爬虫(Web Spider)在互联网上进行海量的信息搜集。信息搜集是信息检索的基础,如果没有采集到足够的信息资源就谈不上信息检索,因此网络爬虫的高质量运行是信息引擎的基础。通常网络爬虫需要考虑很多问题,比如如何爬取高质量的页面,如何避免重复爬取页面,如何并行地高效爬取页面等等。当然并不是所有资源都是可以爬取的,网站的robots.txt协议从道德的角度规定了该站点信息的可爬取性。笔者对爬虫并不了解,因此就不展开讨论了。一旦爬虫爬取到了足够的信息之后,就为信息检索提供了基石,然而大型商业检索引擎每天都能爬取海量的信息,这些信息中并不是每个都是高质量,强时效性的,意味着我们可以通过信息分层的方法,去组织不同质量的资源,以保证检索质量的同时提高整个信息检索的效率。通常的信息资源分层呈现金字塔型,如Fig 2.1所示,通常会将高质量,高时效性的资源组成一个库层,这个库层通常数量较少,但是却可以满足大部分用户的检索需求。在一次信息检索过程中,首先会在高质量库层中进行信息召回,如果没有召回到足够的资源,那么会穿透到第二层库层,该库层信息资料较低,或者时效性较差,数量级可能是第一层的十倍到百倍。如果前两层都不能检索到足够的资源,那么会穿透到最底下的海量资源库,数量级可能是之前库层的十倍到百倍之间,在海量资源库中检索到的结果将会作为兜底进行传递。
Query分析
检索系统可以分为用户检索端(Query端,Q端)和文档资源端(Doc端,URL端,U端)。在用户检索端一侧,我们要求能够系统能够理解用户的真实检索需求,而用户在信息检索系统中,通常用自然文字去描述其检索需求。这就意味着我们需要让机器去理解用户的自然文字表述,并且从中去挖掘用户的真实检索需求。我们用过百度都知道,在搜索过程中我们会用千奇百怪的方式去表达一个简单的需求,语序,语法句法,错别字,中英文混搭,各种奇怪的情况都可能在用户query中出现。因此在检索系统中,如何对用户query进行分析非常重要,通常query分析分为切词,纠错,扩充,需求识别等等,query分析是一个复杂的技术,通常需要一整个大部门进行技术支持,笔者暂时对该技术没有太多认知,暂且不讨论了。
信息召回
在对Query进行了一定程度的分析之后,我们可以在资源池中对Doc进行召回。根据不同的需求,可能会有着不同的召回队列。其中最为基础的召回方式是根据切词结果进行字符匹配,不同的切词(term)会进行独立的召回,形成一个召回拉链,然后结合多个切词召回拉链,进行拉链归并得到最后的倒排拉链。如Fig 4.1所示。
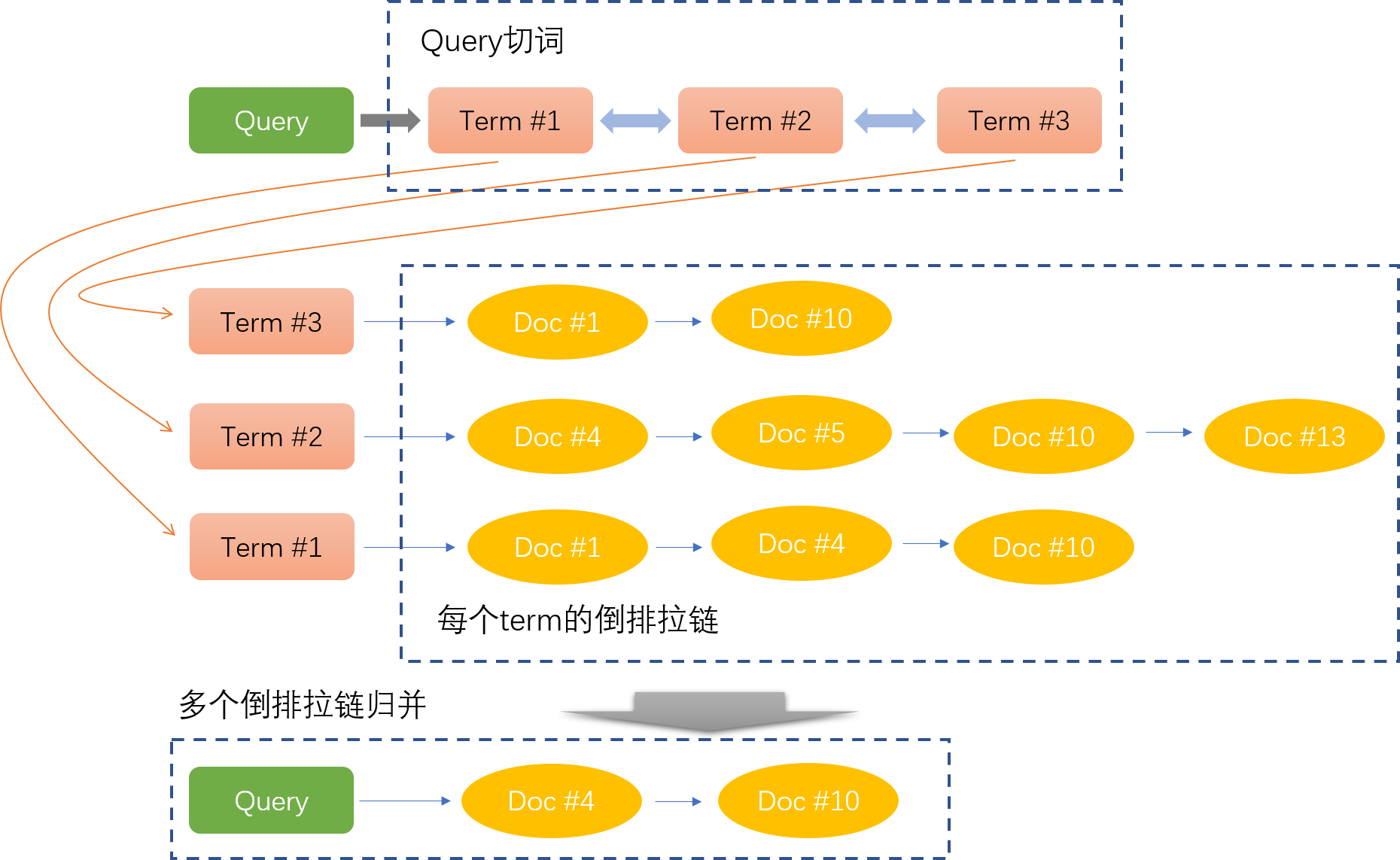
在Query切词足够好的情况下,每个term都可以召回到足够好的Doc,然后多个拉链归并起来就可以得到足够好的检索结果。然而,我们很难保证Query切词的准确性,其次Query存在很多语义相似的情况,这个时候单纯利用切词并且字符匹配很难召回到足够的Doc,需要利用语义相关性进行召回。
相关性
相关性指的是衡量用户Query和检索出的Doc之间的相关程度度量,通常可以划分为若干个档位,比如常见的四个档位:完全相关(3),相关(2),部分相关(1),完全不相干(0)。在一个信息检索系统中,保证Query和Doc之间的强相关性是最基础,也是最根本的技术要求,具有核心的地位。很难想象会有用户,愿意长期对一个检索不到期望的相关文档的搜索引擎买单。然而,评价一个Query和Doc是否相关涉及到了很多技术问题,比如最简单的可能考察Query和Title之间的相关程度,或者更进一步的考虑Query和Content的相关程度,甚至统一地考虑Query,Title和Content之间的相关程度,尽可能地减少由于标题党导致的错误检索。这每一种考虑都可能会涉及到一种特征,而每一种特征可能都可以用不同的模型和数据进行建模。由于不同层级的相关性需要的特征不同,而且这些不同特征的计算算力要求差距很大,因此这些特征通常会在搜索系统的不同阶段生效。比如在召回阶段,由于需要在数以亿计的Doc中进行检索,因此要求相关性模型尽可能的简单高效,这个时候通常会用 基础相关性 对Query-Title的相关程度进行描述,然后召回尽可能多相关的文档。 基础相关性按照笔者的理解,是不包含语义信息的相关性,比如最基础的Query与Title切词后的Term匹配程度,散列命中程度等。基础相关性由于没有考虑到Query与Doc的语义相关,在一些资源缺乏的Query下容易导致召回率低下。第一,与这些Query可能本身密切相关的资源可能就很少,因此期望更好的相关性能够对相似的资源进行检索(也就是即便Title和Query的term匹配并不尽人意,但是其实其语义是相似的),这样就能挖掘到更多的Doc;第二,用户表达需求的手段千差万别,人类的语言表达非常地灵活多变,有些Query的按照字面匹配不能召回的Doc需要通过语义相关性进行召回。目前基于Transformer和Siamese网络的语义相关性模型具有很广泛的应用。
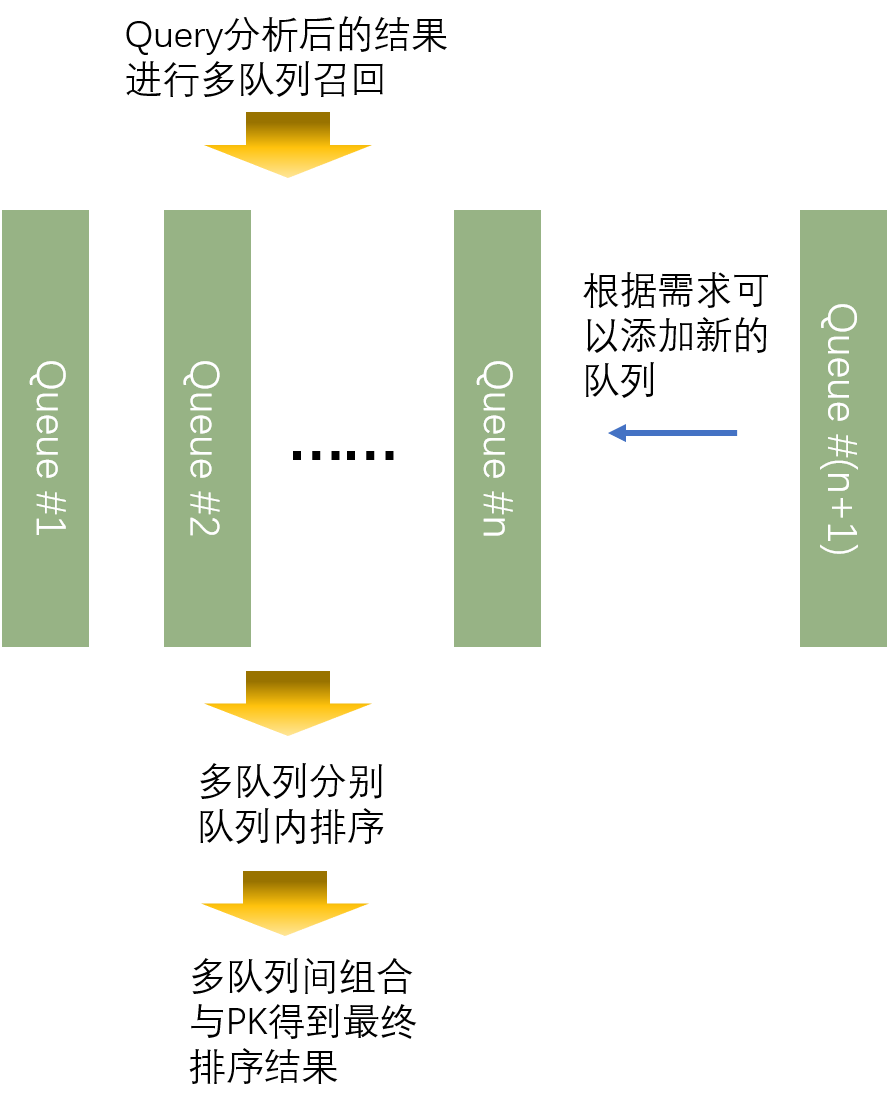
在实际的搜索系统中,可以考虑用不同的队列去组织语义相关性和基础相关性,也即是说语义相关性的召回可能会用独立的队列进行处理。实际上,很多搜索系统因为有其产品设计的定义和商业目的,又或是技术本身的要求,通常都会在召回和排序阶段,用多队列进行。在最后的汇总精排序阶段,再组合不同队列的排序,最后PK得到最终排序结果,这个结果将呈现给用户。采用多队列的方式,能够更加灵活地插入某些特定策略,该策略以特定的队列的形式呈现,而在最后的组合时才会影响到整体的排序结果。如Fig 5.1所示,采用多队列组织任务的方式,可以灵活地根据当前的需求插入或者删去队列,实现系统的迭代更新。
之前谈到的相关性很多都是Query与Title相关的,包括基础相关性和语义相关性等,然而,光从Title很容易出现因为“标题党”导致的检索出来的Doc内容不匹配的问题。解决这种问题的一种思路,很正常地就是要考虑Query与Content的相关性,甚至是Query,Title,Content之间的相关性。对于传统的网页搜索来说,网页内容以文本居多,因此用NLP长文本处理技术可以较好地进行解决。然而在一些垂直搜索领域,特别是多模态搜索中,比如“以文搜图”,“以文搜视频”,“以文搜音乐”等,这些多模态应用中,需要建立文本Query与图片,视频,音频之间的相关性联系,这并不是传统的NLP技术能够解决的。目前有很多相关的多模态模型,可以建立文本与其他模态数据的关系,如[1-4],这些模型大致可以分为两类:交互式模型(以Transformer为代表),双塔模型(以Siamese模型为代表),这两种模型各有优缺点,在实际系统中通常都会在不同模块适当地应用。
信息排序
在召回了足够的相关Doc之后,我们需要对Top K的Doc进行排序,以将最好的,最相关的结果(并且符合上层排序指标)返回给用户。排序过程按照对Doc的影响面和特征数量,特征的“重”与否,大致可以分为粗排和精排。我们注意到,一般排序过程会在各个队列中独立进行,在最后才进行组合。
粗排
在粗排中,通常影响面较大,可能有1000条的级别,也正是因为影响面较大,其特征的计算量不能太大,不然需要非常多的计算资源才能支持得住。在粗排中,通常会采用基于双塔模型的网络进行相关性建模,因为双塔模型可以离线建库,在粗排时候只需要多线程计算相似度即可,非常轻量。
精排
精排通常会考虑前100条进行排序,需要较为精确的特征,经常会考虑Query,Title,Content相关的特征,因为影响面较小,而且相关性要求较高,因此通常会考虑交互式模型。交互式模型基于大数据的预训练,可以实现更好的性能,然而因为需要在线进行交互计算,不能离线建库处理,因此对系统的计算资源要求很高,通常需要用很多工程方法进行优化。
上层排序
在最理想的情况下,对于一个Query来说,系统可以从中查询到最为相关的Top K个Doc返回给用户。然而,商业搜索系统毕竟是要恰饭的,也就是要实现商业价值的,并且考虑到法律法规,某些Doc是不允许返回的(比如涉黄涉暴),对于一些内容过时,虚假,质量低下的Doc更是需要打压。为了实现这些目的,通常需要上层排序对这多个目标进行综合考虑,然后给予最后的排序结果。当然,上层排序的原则是要保证相关性足够强的情况下,对其他因素进行考虑,上层排序也会引入很多类型的特征,这里笔者就不展开了。
Learn To Rank,LTR
在每个Doc都有了足够多的特征之后,我们要如何根据这些特征进行排序呢?这就是Learn To Rank(LTR)所做的事情。LTR可以认为是一个模型
总结
本文笔者对一些搜索系统常见的模块进行了简单科普向介绍,并没有涉及到具体技术本身,希望后续有空继续能深入介绍一些具体细节。
Reference
[1]. Yu, Fei, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. “Ernie-vil: Knowledge enhanced vision-language representations through scene graph.” arXiv preprint arXiv:2006.16934 (2020).
[2]. Sun, C., Myers, A., Vondrick, C., Murphy, K., & Schmid, C. (2019). Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 7464-7473).
[3]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.
[4]. Ramesh, Aditya, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. "Zero-shot text-to-image generation." arXiv preprint arXiv:2102.12092 (2021).