本文主要作为笔者在分布式集群中训练深度学习模型,特别是一些大规模模型和在海量数据下的训练的经验,本文实践以paddle 2.1为例,包括paddle 动态图和静态图的使用等。
前言
本文主要作为笔者在分布式集群中训练深度学习模型,特别是一些大规模模型和在海量数据下的训练的经验,本文实践以paddle 2.1为例,包括paddle 动态图和静态图的使用等。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

分布式数据读取器
我们之前在数据量少(比如几百个GB),并且训练节点少(比如8个GPU以内)的时候,通常我们的数据都可以全部放到训练节点进行储存和读取。但是当数据量达到数以亿计的时候,数据规模就会达到几百个TB,此时单个训练节点将无法再能储存所有数据。此时,我们的数据势必用大规模的集群进行储存管理和读取,因此此时的分布式数据读取器设计将会和单节点的数据读取器设计有所不同,如Fig 1.1所示。
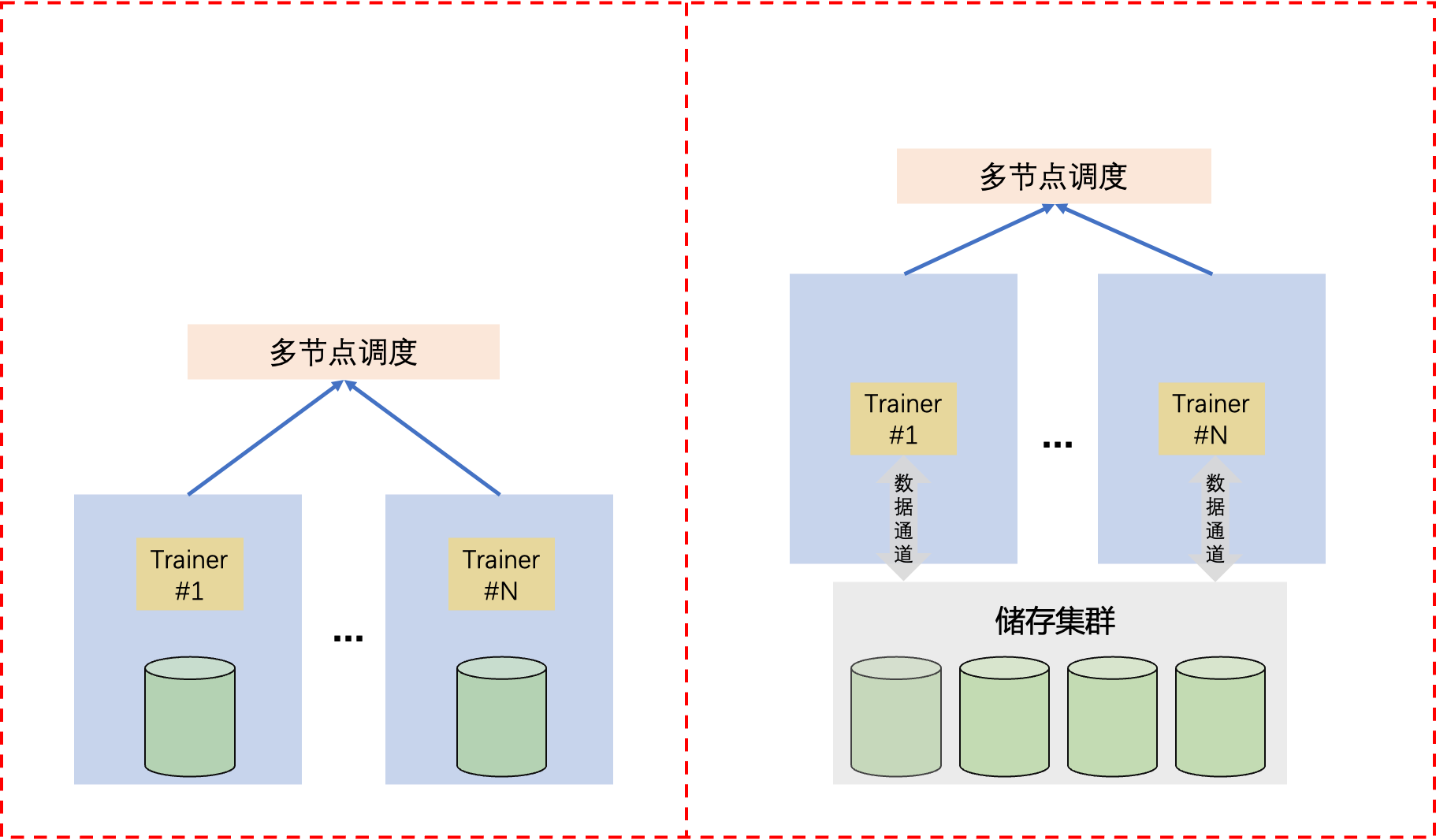
为了以下说明方便,假设我们现在有2个节点,每个节点上有8张GPU卡作为trainer,那么我们的程序将会把整个训练过程切分成16个进程,每个节点上8个训练进程,分别对应每个节点上的每个GPU卡,也即是每张卡都会有一个训练进程占用。我们把这每个进程称之为trainer,其分别有独立的标识符trainer_id用于表示不同的trainer。在集群中,我们的数据将会被均分为若干个part,其中每个part的大小可能达到10到20GB,假设我们现在一共有16000个part,其中每个part的大小为16GB,总数据量为250 TB。为了对其中的每个part进行索引,那么需要有这些part的filename_list,我们的trainer在加载新的part数据时候,将会从各自的filename_list中取得下一个待加载的数据。filename_list如以下所示:1
2
3
4
5./data/train_data/part-00001
./data/train_data/part-00002
./data/train_data/part-00003
...
./data/train_data/part-16000
我们使用的时候通常需要首先对filename_list进行打乱。以采用动态图情况下作为示例,笔者认为一个比较好的实践是,首先通过$RANDOM生成一个范围在0~32767的随机数,将其作为所有trainer的初始化随机数,用于保证每个trainer中对filename_list打乱的结果是一致的,读者可能会有疑问了,那么这样每个trainer岂不是都在加载同一份数据? 是的,如果止步于此那么每个trainer都在对同一份数据进行训练了,这样不仅仅是无意义的而且是对整个任务有害处的,我们后续讨论为什么这样是有害处的。回到原先的讨论,我们现在能确保每个trainer上都是相同的打乱后的filename_list了,为了保证每个trainer上的取到的数据part是互斥且完备的,我们可以用当前filename_list的index对trainer_num取余,如果取余结果等于当前的trainer_id,那么就把这个file当成是本trainer应该训练的有效part,如下所示:1
2
3global_rng = np.random.RandomState(random_seed)
global_rng.shuffle(filename_list)
trainer_filename_list = [filename, index, filename for enumerate(filename_list) if index % trainer_num == trainer_id]
其中对某个trainer_id和trainer_num的获取取决框架,在paddle中可以用以下代码获取1
2trainer_num = paddle.distributed.get_world_size()
trainer_id = paddle.distributed.get_rank()
通过这种根据trainer_id划分数据集的策略,可以使得每个trainer上的数据是互斥且完备的。
回想到我们之前用动态图组织数据读取的时候,因为数据量通常不大,经常是只需要在Dataset类初始化的时候加载所有数据到内存,或者数据量略大(比如几百个GB),但是单机磁盘储存没问题,也可以用__getitem__时动态读取的方式,如以下伪代码的DatasetFromMemory和DatasetFromDisk所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class DatasetFromMemory(nn.modules.Dataset):
def __init__(self):
self.data_pool = []
self.loading_whole_data(self.data_pool) # 此处将会把所有数据加载到data_pool中,通过index索引可以在__getitem__中进行检索
def __getitem__(self, index):
data = self.data_pool(index)
return self._preprocess(data)
class DatasetFromDisk(nn.modules.Dataset):
def __init__(self, disk_path):
self.disk_path = disk_path
def __getitem__(self, index):
data = self.loading_from_disk(index)
return self._preprocess(data)
dataset = DatasetFromMemory()
# dataset = DatasetFromDisk(...)
dataloader = Dataloader(dataset, num_workers=16, ...)
model = Model(args, ...)
optim = Adam(args, ...)
for datapack in dataloader:
data, label = datapack
logit = model(data)
loss = loss_fn(logit, label)
loss.backward()
optim.step()
optim.clear_grad()
但是显然,当数据量达到250个TB时候,以上做法是无法实现的,我们需要手动进行新的数据的下载和加载,再考虑到之前提到的数据划分模式,整个分布式数据读取器设计如以下伪代码所示。其和之前的实践最大的区别在于只会为当前训练需要的数据part进行加载,一旦用完了需要手动调用dataset.loading_next_part()触发加载。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class DatasetFromCluster(nn.modules.Dataset):
def __init__(self, filename_list, random_seed=0):
global_rng = np.random.RandomState(random_seed)
global_rng.shuffle(filename_list)
self.trainer_filename_list = [filename, index, filename for enumerate(filename_list) if index % trainer_num == trainer_id]
self.data_pool = []
self.loading_next_part()
def __getitem__(self, index):
data = self.data_pool(index)
return self._preprocess(data)
def loading_next_part(self):
'''
从集群中加载新的数据part,并且用其对self.data_pool进行更新
'''
pass
step = 0
max_train_step = 100
model = Model(args, ...)
optim = Adam(args, ...)
dataset = DatasetFromCluster()
while step < max_train_step:
dataloader = Dataloader(dataset, num_workers=16, ...)
for datapack in dataloader:
step += 1
...
dataset.loading_next_part() # 手动触发加载下一个数据part,并且进行新的part的训练。
这样能实现大规模集群数据的分布式加载,并且能保证加载过程的正确性和效率。但是这个实现仍然不是最佳的,如Fig 1.2所示,目前paddle的数据读取器是不支持preloading机制的。在手动加载完了当前的part数据之后,就会对该part进行训练,在这个训练过程中不会进行下一个数据的预加载,这意味着一旦训练结束,就会停止训练进行新数据的加载,这意味着这部分的计算资源闲置了。而且随着trainer数量的增多,其计算资源闲置的情况越严重,如Fig 1.2所示,在最理想的情况下,计算资源闲置率是:
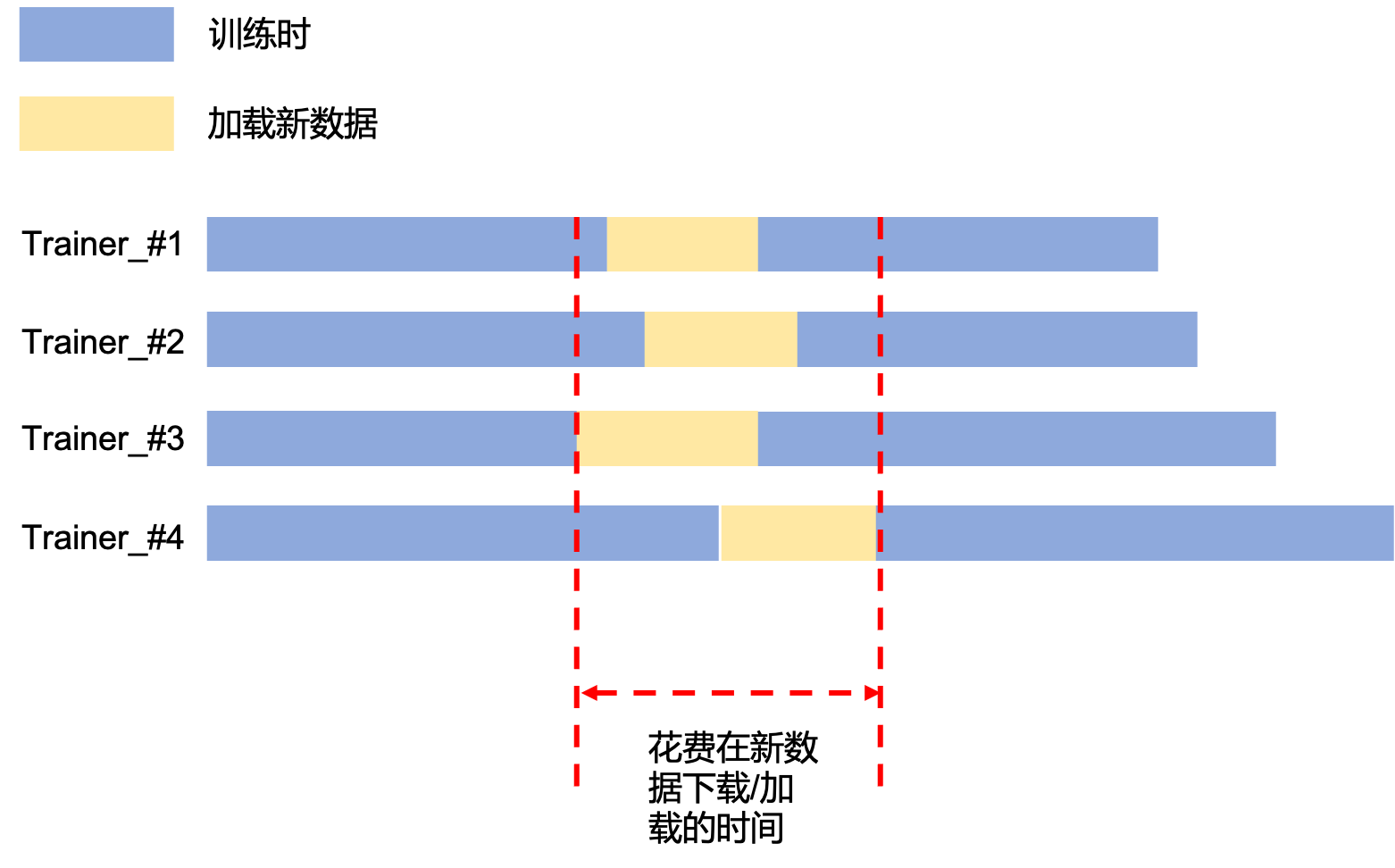
其实以上的估计还是太过于乐观了,因为在分布式多卡训练过程中,特别是如果采用了all_gather机制[1]的代码(比如paddle.distributed.all_gather),那么在某个trainer耗尽了数据,进行新数据读取的时候,其实其他卡也是被阻塞掉的(即便其他trainer上还有数据没消耗完),因为整个分布式训练必须依赖于所有trainer的参与,考虑到这个实际情况,那么实际的时间线如Fig 1.3所示,此时计算闲置率会比理想情况下更高,此时类似于计算机处理器里面的流水线断流了。我们可以简单预估下此时的计算闲置率:
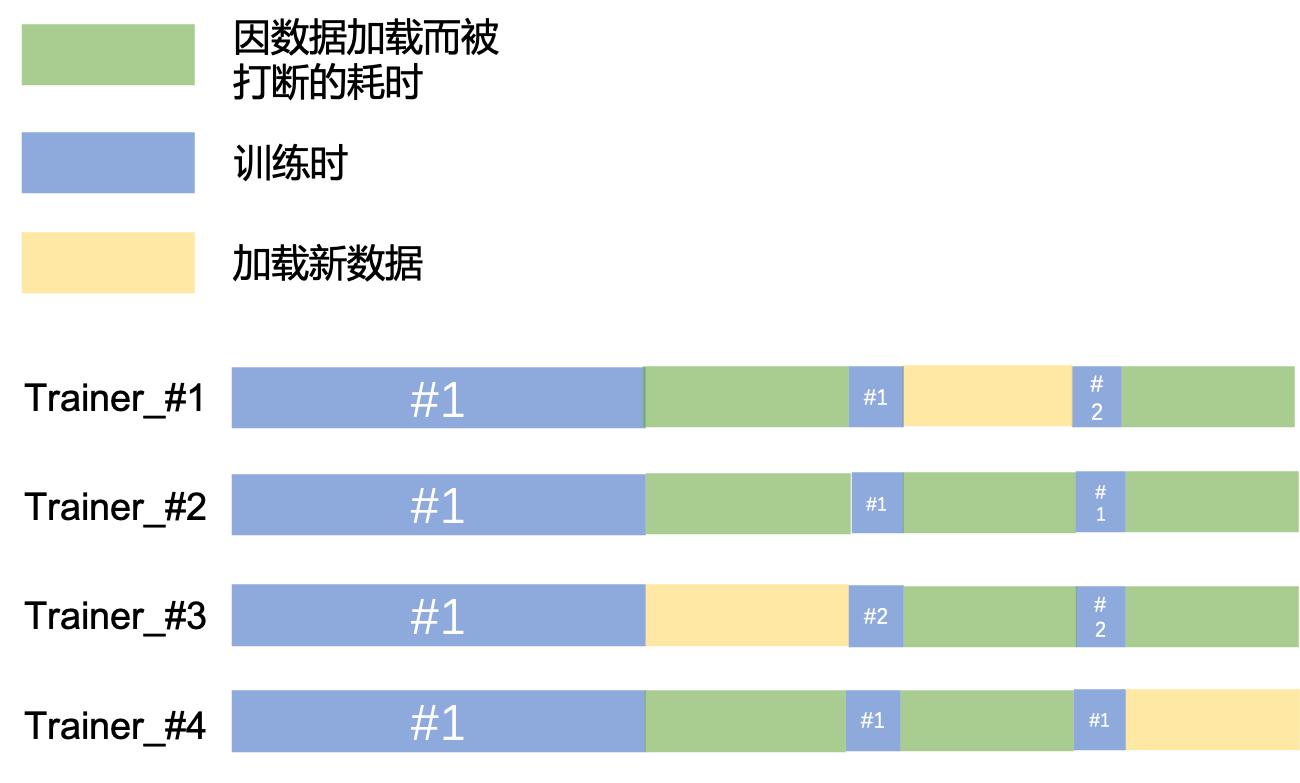
Reference
[1]. https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/distributed/all_gather_cn.html