最近在一个项目中接触到了卡尔曼滤波,并且对此进行了学习,发现其是一个很有意思的信息融合的算法,可以结合多种传感器的信息(存在噪声),得到更为理想的估计,因此在此进行笔记和心得纪录。本人不是从事控制相关专业工作,可能在短暂的自学过程中对此存在误解,若有谬误,望联系指出,谢谢。
前言
最近在一个项目中接触到了卡尔曼滤波,并且对此进行了学习,发现其是一个很有意思的信息融合的算法,可以结合多种传感器的信息(存在噪声),得到更为理想的估计,因此在此进行笔记和心得纪录。本人不是从事控制相关专业工作,可能在短暂的自学过程中对此存在误解,若有谬误,望联系指出,谢谢。(文章主要参考了[1])
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

从传感器的测量谈起
在正式讨论卡尔曼滤波前,我们先讨论对物理量的测量。我们会发现是和卡尔曼滤波紧密相关的。 我们知道,如果需要对自然界的某个物理量,比如温度,气压,速度等进行测量,我们需要用各种传感器进行测量。但是,因为器件的工艺不可能达到完美,或者其他不能被人为预测到或者控制到的因素和噪声等存在,传感器对物理量的预测不可能是完全准确的。因此,我们与其把传感器的测量结果当成是一个确定值,不如把它看成是一个随机变量
如下图所示,如果直接观察传感器数据,那么其可能是会存在很大的抖动,而不是平滑的,原因可能是观察噪声的影响。
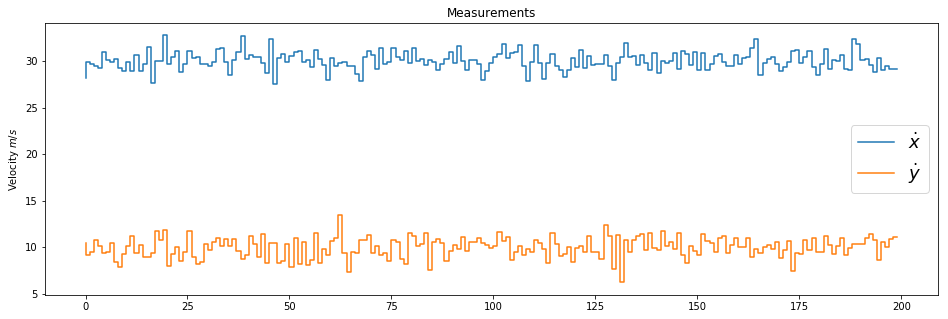
我们这个时候就想到,如果一次观察是抖动的,有着
- 我们前面谈到了不确定度
是可能时变的,简单相加不能最好地消除不确定性。 - 时间上滑动窗口进行多次测量的求和,会导致延迟。
对此,我们进行一个小改进,就是用多个相同的传感器去同时测量一个物理量,然后求和或者根据可靠程度去求加权平均和,我们假设多个传感器的采样值
这个时候简单的求和就容易造成结果的偏移,我们不妨根据方差的大小,进行加权平均求和,在此之前,我们需要几个假设:
- 不同传感器的测量都是一个随机变量,其均值
相同。 - 不同传感器的测量之间是无关的,也就是说知道了
不能对知道其他策略 提供任何信息,但是也不会影响到观测 的均值,即是 。
接下来,我们用这两个假设,进行简单的传感器间的数据融合以提高测量效果。Let's move on!
简单版本,多传感器数据融合
为了简单起见,假设我们用两个相同的传感器进行测量,那么最后数据融合结果应该是:
为了最小化
这里讨论的只是两个传感器的情况,可以简单地推导到多个传感器的情况和当观测值是一个向量时候的情况,以及为了计算有效性,采用迭代计算的方法,具体可以参考文献[3]。其中,为了以后讨论的方便,这里给出当观测值是一个向量,并且只有两个传感器时的公式(2.4):
卡尔曼滤波,开始征程
接下来我们开始正式讨论卡尔曼滤波(Kalman Filter)。我们之前讨论的传感器之间其实都是无关(uncorrelated)的,但是,其实经常我们知道了某个测量量,是可以确定或者为确定另一个测量量提供信息量的,比如我们现在需要测量车辆的位置和速度,那么知道了速度,通常可以为下一步知道位置提供一定的信息。在这种前提下,我们便能够通过更为合理的数据融合手段,得到更为精确的估计结果。
定位问题[1]
考虑一个例子,我们的机器人需要定位,通常使用的是GPS进行定位,得到车辆的状态量之一的位置:
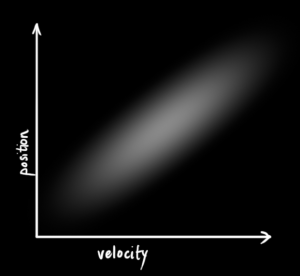
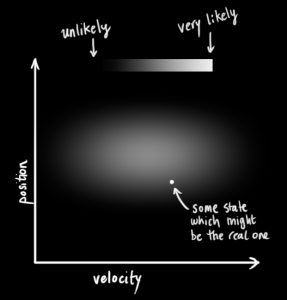
这个时候,观测的不确定性体现在方差
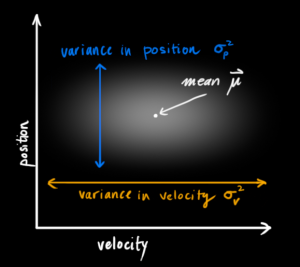
状态预测方程
这个时候,如果我们的观测是准确的,那么会出现什么情况呢?我们根据牛顿力学,可以对位置-速度的过程进行建模,我们会有:
用矩阵形式表达就是:
其中,
我们称
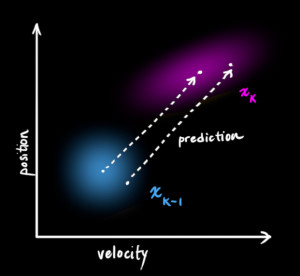
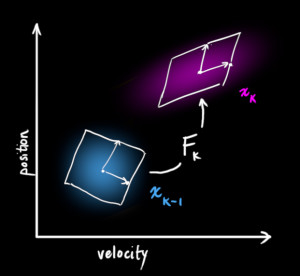
那么此时,预测的状态量
考虑施加外力的情况,添加控制项
在控制理论问题中,我们怎么能忘记添加控制项呢?毕竟我们都希望整个系统是可控制的,而不是任其随意发展的。
让我们继续扩展我们上面的那个例子。考虑到机器人本身有油门,可以进行一定的加速行驶,也可以按照一定的加速度制动,让我们假设这个加速度为
然而,因为一系列的误差存在,我们的预测不可能是完全准确的。那么我们的误差或者是不确定性主要在哪里存在呢?
导致预测或者观察不确定性的因素
有以下四种因素可能导致我们的状态预测或者观察存在不确定性[2],我们对此进行简单描述:
- 参数的不确定性:参数不确定性指的是在对预测进行建模时,比如
,这个模型通过参数 进行建模,然而对这个参数的观察不可能是百分百精确的,这个参数的误差就会导致整个模型的误差,因此状态预测这个时候更新为:
- 控制器的不确定性:实际生活中,我们的控制器同样不可能完美,这个误差可以建模为:
- 模型的不确定性:实际中,我们通过简单的线性建模不一定能很好地表达模型预测,因此要引入一个残差项,表示模型的不完美,建模为:
- 观测不确定性:就像我们之前谈到的,我们的观测也是不完美的。
描述不确定性
正如上一节我们谈到的,有一些影响状态的因素,比如风,地面情况,轮胎打滑或者其他各种小情况我们是没法完全考虑到的,也就没法建模出来,这个时候,状态预测结果就存在不确定性,如Fig 7所示:
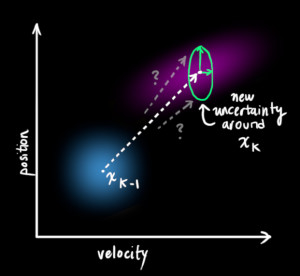
这个影响导致了我们式子(3.4)中的协方差发生了变化,但是其均值不变,公式如:
根据观测结果对估计进行调整
预测和观测~同父异母的兄弟
实际系统中,我们可能有多个传感器给予我们关于系统状态的信息,我们这里不在乎其测量的量到底是什么,我们只要知道,每个传感器都间接地告诉了我们状态量。注意到我们预测状态量的尺度和单位和观测结果的尺度和单位可能是不一样的,这个时候就需要用线性变换把他们变成一样尺度和单位的。你可能猜到了,我们还是引入一个矩阵
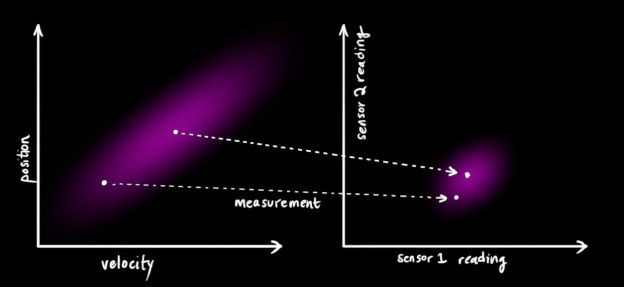
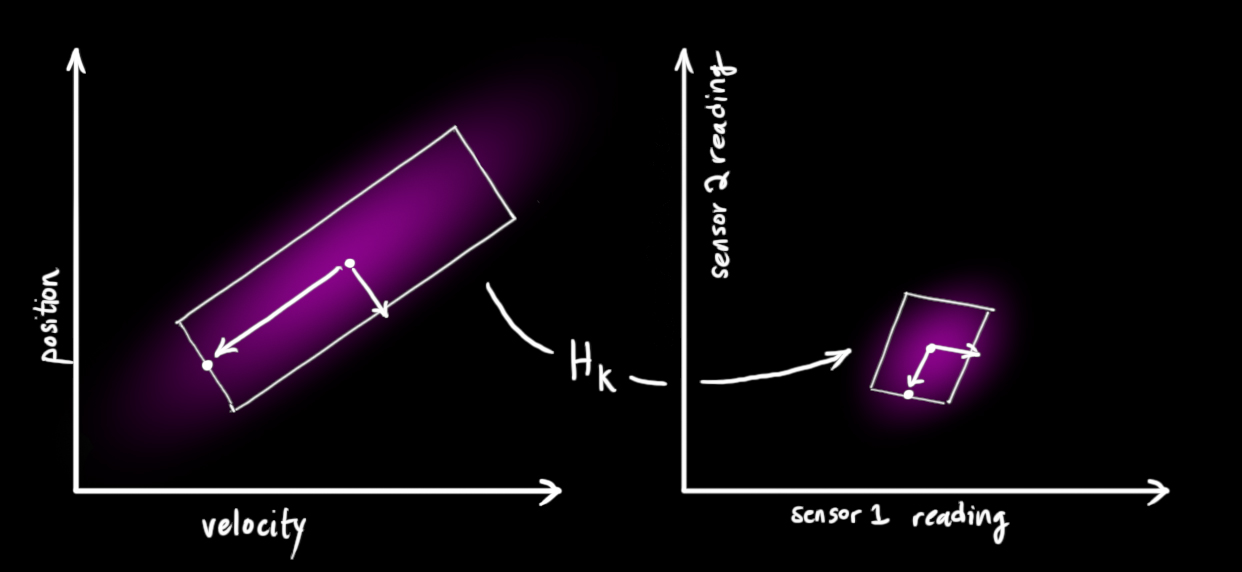
那么,公式有:
老问题,因为传感器存在噪声,我们的观测结果至少在某种程度上是不可靠的,在原来估计的情况下的结果可能对应了一个范围的传感器观测值。
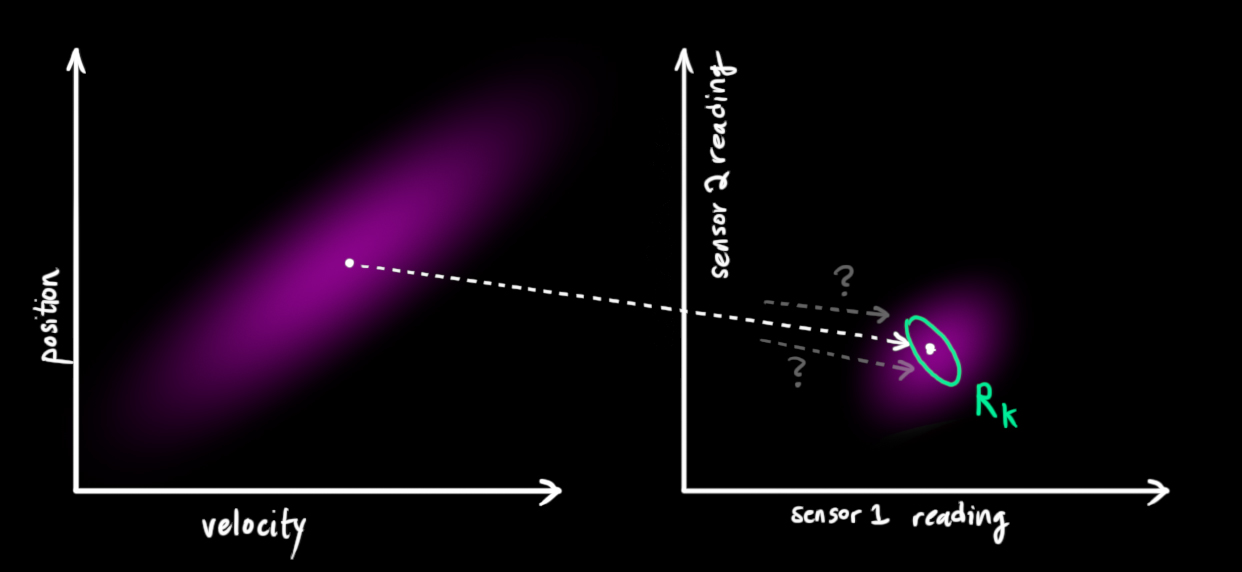
到现在为止,我们有了两个高斯分布:
一个是通过线性变换
将预测结果转化为理论观察值的分布 。 另一个是实际的观察值的分布
,其均值为 。
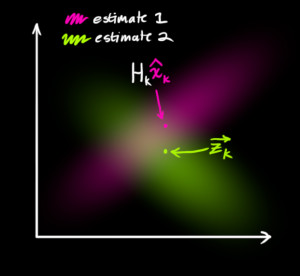
为了得到这个交集分布的表达形式,我们需要将两个高斯分布进行相乘即可,我们知道高斯分布的乘积也是高斯分布[4]。
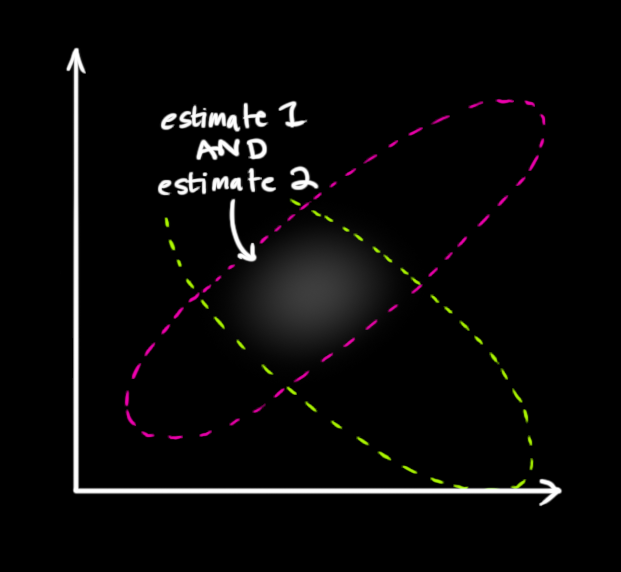
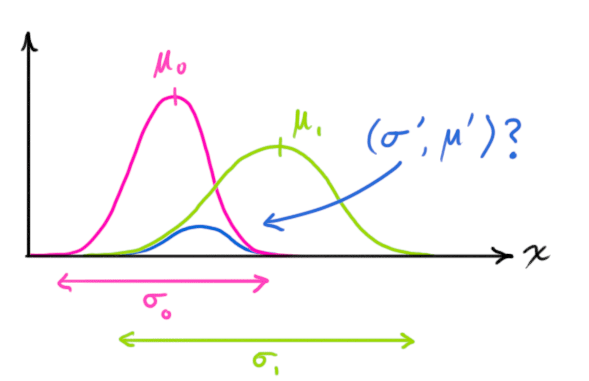
根据[1,4]的推导,我们知道相乘后的结果为:
结合起来吧~状态更新
我们现在有两个分布了:
- 预测分布:
- 观测分布:
将(3.12) (3.13)代入(3.11),我们有:
注意到(3.14)的
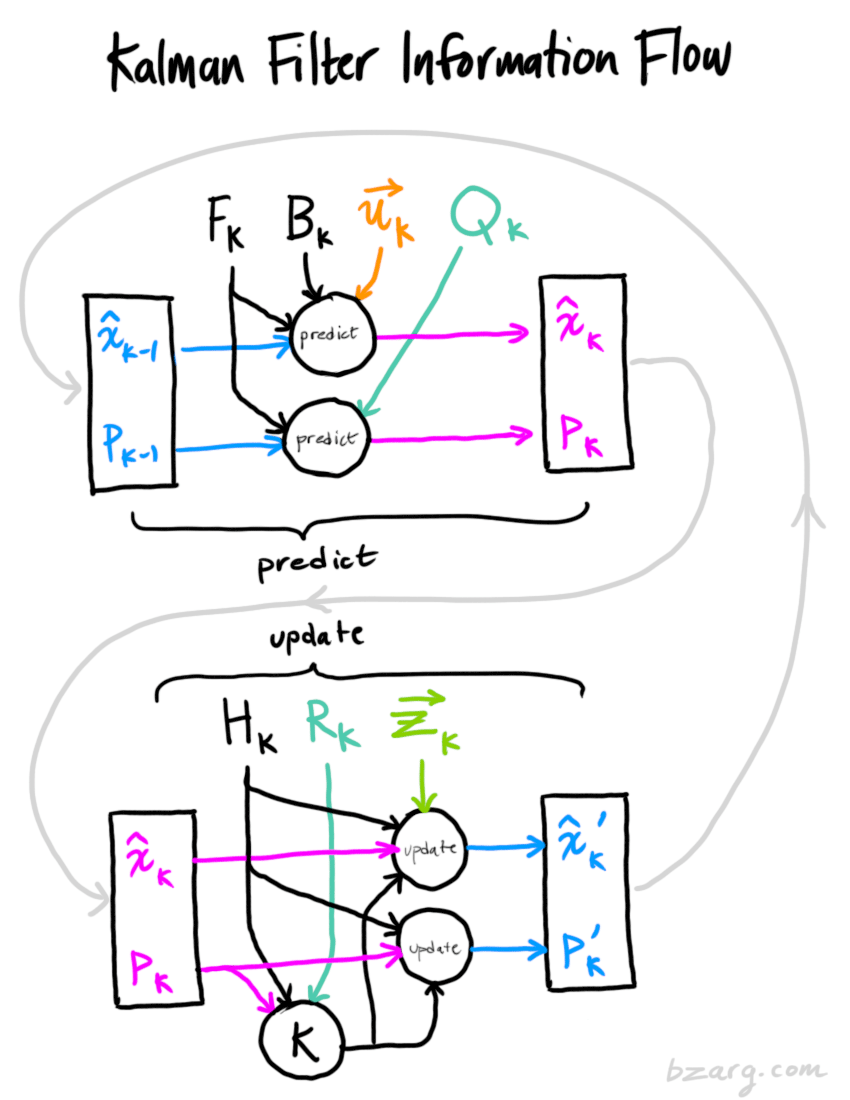
Reference
[1]. https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
[2]. https://towardsdatascience.com/kalman-filter-intuition-and-discrete-case-derivation-2188f789ec3a
[3]. Pei Y, Biswas S, Fussell D S, et al. An elementary introduction to kalman filtering[J]. arXiv preprint arXiv:1710.04055, 2017.
[4]. http://www.tina-vision.net/docs/memos/2003-003.pdf