之前在[1]中曾经讨论过在集群中分布式训练大型模型需要一些特别的分布式数据加载器设计,文章最后还讨论了由于分布式多机多卡训练过程中,某个trainer由于数据读取,将会导致其他所有trainer阻塞等待,造成了很大的计算资源浪费的情况。本文针对这种情况,提出一种基于多进程的解法。
前言
之前在[1]中曾经讨论过在集群中分布式训练大型模型需要一些特别的分布式数据加载器设计,文章最后还讨论了由于分布式多机多卡训练过程中,某个trainer由于数据读取,将会导致其他所有trainer阻塞等待,造成了很大的计算资源浪费的情况。本文针对这种情况,提出一种基于多进程的解法。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

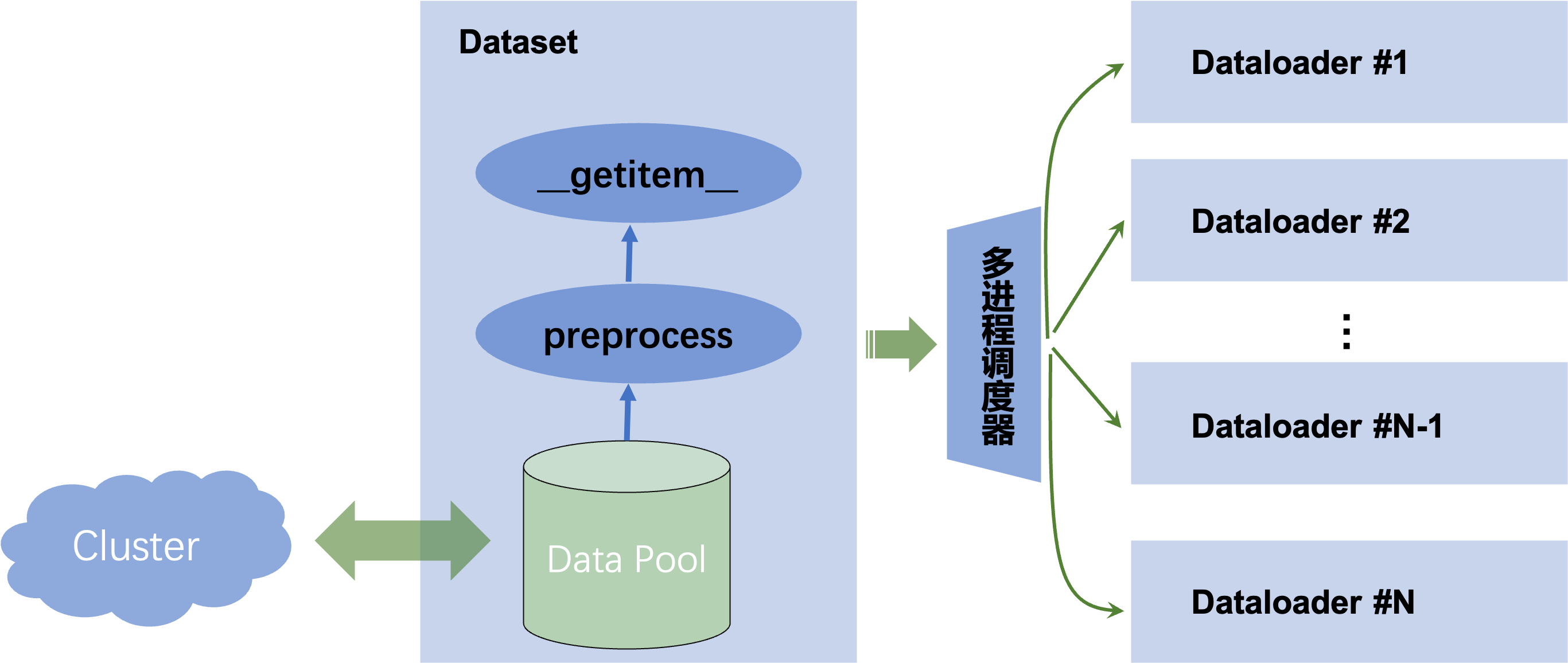
在[1]中最后提出的分布式数据读取方案其实可以看成是某种同步的方案,伪代码如下所示。在当某个trainer耗尽了数据之后,就需要触发dataset.loading_next_part()从而加载下一个part的数据,与此同时,其他所有trainer则会阻塞,导致了大量的计算资源浪费,在笔者实验过程中,某些场景中甚至可能导致1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class DatasetFromCluster(nn.modules.Dataset):
def __init__(self, filename_list, random_seed=0):
global_rng = np.random.RandomState(random_seed)
global_rng.shuffle(filename_list)
self.trainer_filename_list = [filename, index, filename for enumerate(filename_list) if index % trainer_num == trainer_id]
self.data_pool = []
self.loading_next_part()
def __getitem__(self, index):
data = self.data_pool(index)
return self._preprocess(data)
def loading_next_part(self):
'''
从集群中加载新的数据part,并且用其对self.data_pool进行更新
'''
pass
step = 0
max_train_step = 100
model = Model(args, ...)
optim = Adam(args, ...)
dataset = DatasetFromCluster()
while step < max_train_step:
dataloader = Dataloader(dataset, num_workers=16, ...)
for datapack in dataloader:
step += 1
...
dataset.loading_next_part() # 手动触发加载下一个数据part,并且进行新的part的训练。
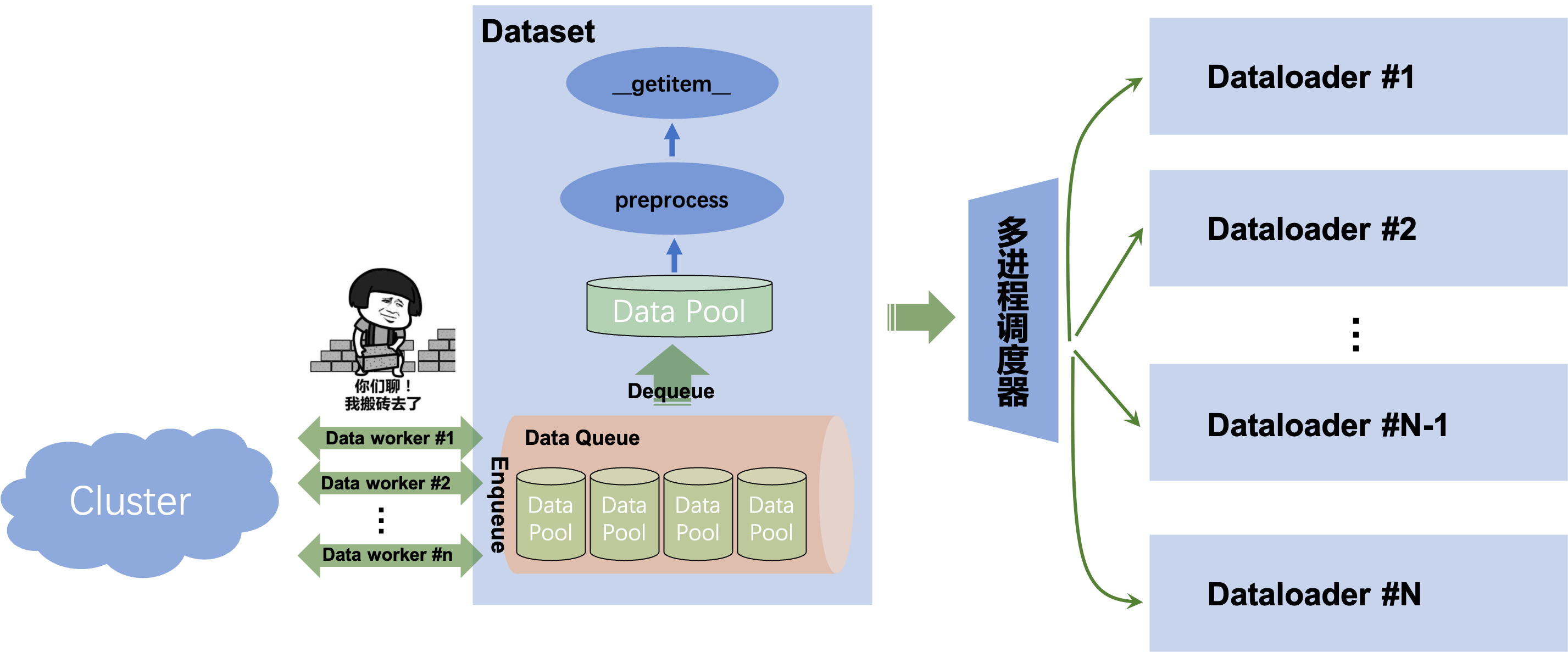
解决该问题的关键点在于,之前的同步方案中,整个Dataset只有一个进程,该进程不仅需要负责管理数据池(data_pool)包括将数据从集群上下载和解析,还得负责预处理和__getitem__取值等,一旦某个过程收到阻塞(比如从集群上下载数据),那么整个程序就会被阻塞掉。我们回想到Dataloader的设计中,通过多进程切分了多个worker,去将数据从Dataset中进行拉取和预处理,通过多个进程的并发可以掩盖了某个进程的大量耗时。那么此时,我们也可以在Dataset中设计两类进程,一个进程就是Dataset本身,用于管理数据和封装数据接口,方便Dataloader接入和取值,我们称该进程为data_manager;还有另一类进程负责从集群中拉取数据和解析,并且将数据入队列(Enqueue),我们称该进程为data_worker。该队列(Data Queue)用于管理所有数据,其中每个数据单元item就是之前方案中所说的data_pool,也就是集群里面的一个part。这个方案可以视为是异步Dataset数据读取器,同步和异步数据读取的差别可见Fig 1.和Fig 2.所示,后者的Data worker的功能可由多个进程或者线程承载。一旦Data queue状态不为满(Full)的时候,就由一个或者多个data worker从集群中加载数据并且进行入队,如果状态为满,那么就阻塞当前所有的data worker。当某个trainer的数据消耗完后,如果Data queue状态为空(Empty),那么就阻塞trainer,发起data worker从集群中拉取新的数据,如果不为空就从Data Queue中出队(Dequeue)一个新的数据作为Data Pool用于训练。
考虑到多进程的data worker读取数据并且入队需要重新对filelist进行互斥切分,并且在实践中一个data worker就足以应对绝大多数情况,我们一般采用一个data worker就足够了。那么以上流程的伪代码可见如下。
1 | from multiprocessing import Queue, Process |
Reference
[1]. https://fesian.blog.csdn.net/article/details/121146854