支持向量机是常用的,泛化性能佳的,而且可以应用核技巧的机器学习算法,在深度学习流行前是最被广泛使用的机器学习算法之一,就算是深度学习流行的现在,支持向量机也由于其高性能,较低的计算复杂度而被人们广泛应用。这里结合李航博士的《统计学习方法》一书的推导和林轩田老师在《机器学习技法》中的讲解,谈谈自己的认识。
前言
支持向量机是常用的,泛化性能佳的,而且可以应用核技巧的机器学习算法,在深度学习流行前是最被广泛使用的机器学习算法之一,就算是深度学习流行的现在,支持向量机也由于其高性能,较低的计算复杂度而被人们广泛应用。这里结合李航博士的《统计学习方法》一书的推导和林轩田老师在《机器学习技法》中的讲解,谈谈自己的认识。 如有谬误,请联系指正。转载请注明出处。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

SVM的起源
支持向量机(Support Vector Machine, SVM)是一种被广泛使用的机器学习算法,自从被Vapnik等人提出来之后便被广泛使用和发展。传统的支持向量机一般是二类分类器,其基本出发点很简单,就是找到一个策略,能够让线性分类器的分类超平面能够最大程度的把两类的样本最好地分割开,这里我们讨论下什么叫做最好地分割开,和实现这个对整个分类器的意义。
最好地分割数据
在进行接下来的讨论之前,为了简化我们的讨论从而直面问题所在,我们进行以下假设:
1) 我们现在的两类数据是线性可分的, 也就是总是存在一个超平面
可以将数据完美的分开。 2) 我们的数据维度是二维的,也就是特征维只有两个,类标签用+1, -1表示,这样方便我们绘制图像。
我在前篇博文《机器学习系列之 感知器模型》中已经介绍到了感知器这一简单的线性分类器。感知器很原始,只能对线性可分的数据进行准确分割,而且由于其激活函数选用的是阶跃函数,因此不能通过梯度的方法进行参数更新,而是只能采用错误驱动的策略进行参数更新,这样我们的超平面其实是不确定的,因为其取决于具体随机到的是哪个样本点进行更新,这是一个不稳定的结果。而且,由于采用了这种参数更新策略,感知器的超平面即使是能够将线性数据完美地分割开,也经常会出现超平面非常接近某一个类的样本,而偏离另一个类的样本的这种情况,特别是在真实情况下的数据是叠加了噪声的情况下。 如下图所示,其中绿线是感知器的运行结果,因为其算法的不稳定性,所以每次的结果都可能不同,选中的这一次我们可以看出来虽然绿线将两类数据完美地分割开了,但是和蓝色样本很接近,如果新来的测试样本叠加一个噪声,这个超平面就很容易将它分类错误,而最佳分类面粉色线则对噪声有着更好地容忍。 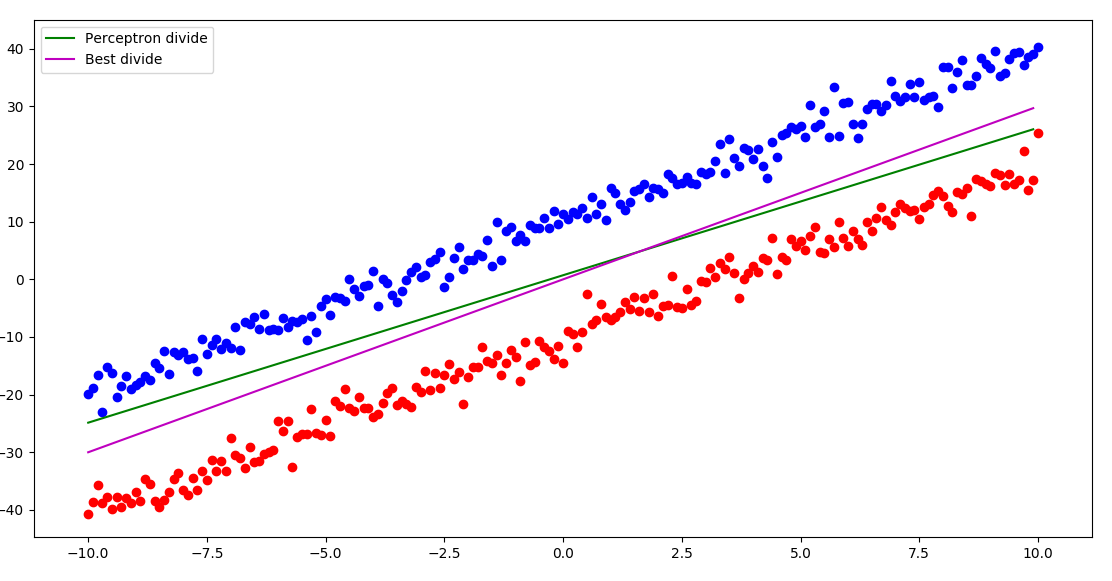
样本噪声
刚才我们谈到了样本集上叠加的噪声,噪声广泛存在于真实数据集中,无法避免,因此我们的分类超平面要能够对噪声进行一定的容忍。一般我们假设噪声为高斯噪声,如下图所示:
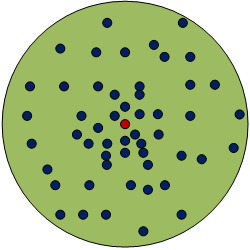
其中红点为实际的采样到的样本位置
最佳分类超平面
也就是说我们根据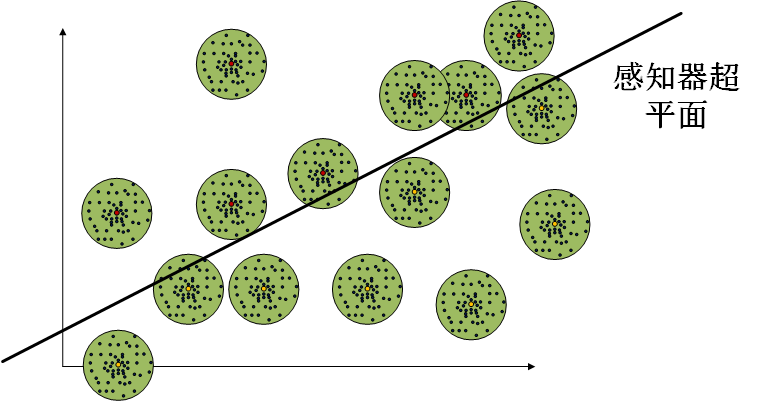
Figure 1, 感知器分类超平面能将线性可分的样本完美分割,但是由于样本叠加了高斯噪声
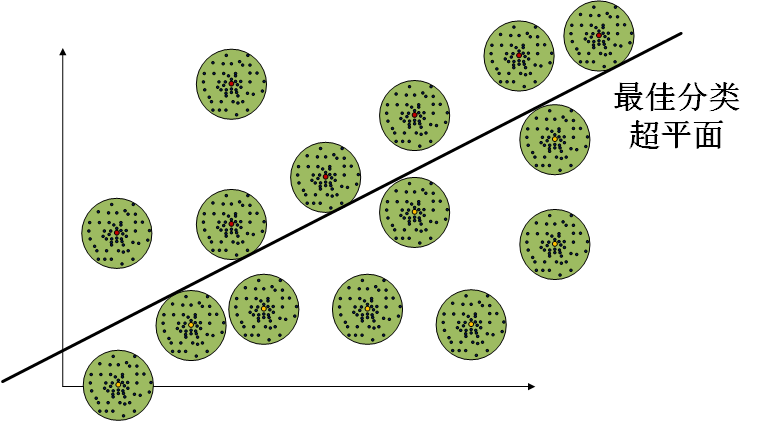
Figure 2,假设我们的样本集都是独立同分布采样的,那么其叠加的高斯噪声
SVM提出
我们在上面谈到了最佳分类超平面应能够使得支持向量距离超平面的距离最大,这个就是支持向量机的基本机制的最优化的目标,我们需要解决这个问题就必须要先数学形式化我们这个目的,只有这样才能进行最优化和求解。
数学形式化表述
我们这里对SVM问题进行数学上的形式化表述,以便于求解,这里主要讨论SVM的原问题,实际上,SVM通常转化为对偶问题进行求解,我们将在下一篇文章里讨论SVM的对偶问题。
函数间隔和几何间隔
我们刚才的表述中,我们知道了SVM的关键就是:使得支持向量距离分类超平面的距离之和最小,这里涉及到了“距离”这个概念,因此我们就必须要定义这个“距离”。这个距离可以定义为函数间隔(functional margin)和几何间隔(geometric margin)。我们分别来观察下这两个间隔。
函数间隔
我们表征一个样本点
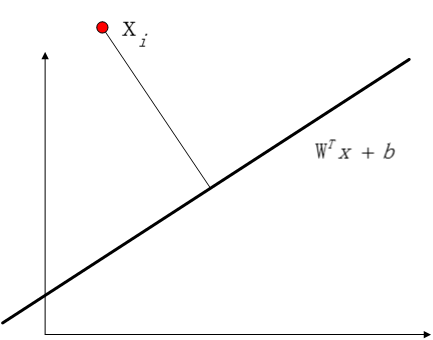
几何间隔
函数间隔可以在一定程度上表征距离,但是存在一个问题,就是在
最大化最小距离
定义了几何间隔和函数间隔之后,我们就需要最大化最小距离了,这个听起来挺绕口的,其实意思很简单,就是求得一组
这个就是最小几何间隔距离,我们现在最大化它,有:
容易看出其中的
这里我们要想一下:
此时最大化问题转化为最小化问题:
至此,我们得到了SVM的标准原问题表达。注意到这个式子里的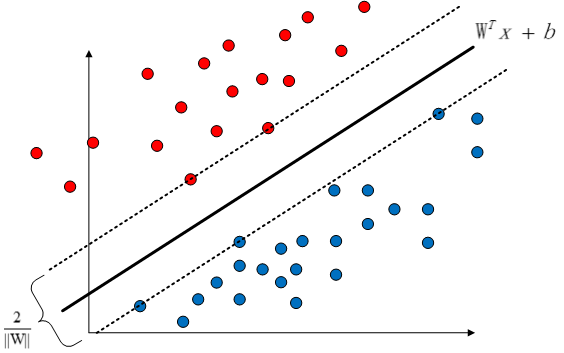
我们接下来将会讨论SVM原问题拉格朗日函数形式以及其对偶问题,以便于更好地解决这个最优化问题。