之前在博文[2-4]中介绍了一些图文多模态语义对齐相关的模型,分别是WenLan 1.0, WenLan 2.0和CLIP等,这些模型都是双塔结构模型,然而在实际的应用场景中,我们会有使用单塔模型的需求,笔者在本文将介绍一篇论文[1]的思路,将单塔模型和双塔模型结合在一起进行图文多模态语义融合和对齐。
前言
之前在博文[2-4]中介绍了一些图文多模态语义对齐相关的模型,分别是WenLan 1.0, WenLan 2.0和CLIP等,这些模型都是双塔结构模型,然而在实际的应用场景中,我们会有使用单塔模型的需求,笔者在本文将介绍一篇论文[1]的思路,将单塔模型和双塔模型结合在一起进行图文多模态语义融合和对齐。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

双塔多模态模型的优势与缺陷
之前在博文[2-4]中曾经简单介绍过一些图文多模态模型,分别是WenLan 1.0 [5]和WenLan 2.0 [6]以及CLIP [7],这些多模态模型在不同的模态上,都有着各自模态各自的编码器。如Fig 1.1所示,CLIP中的图片编码器和文本编码器共同组成了一个双塔结构模型进行损失计算。双塔模型在很多业务场景有着广泛应用,比如在图文信息检索场景中,我们要衡量用户Query和图片之间的图文相关性。假如图片编码器是
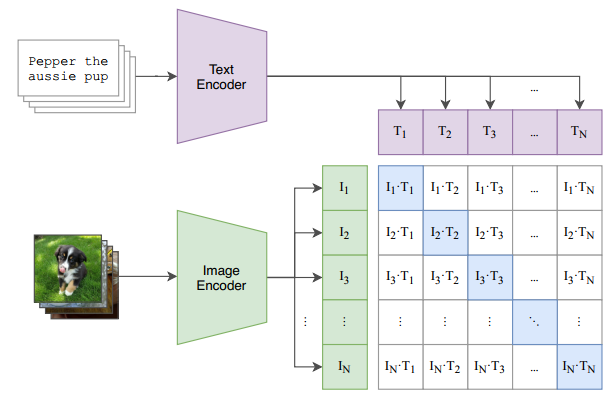
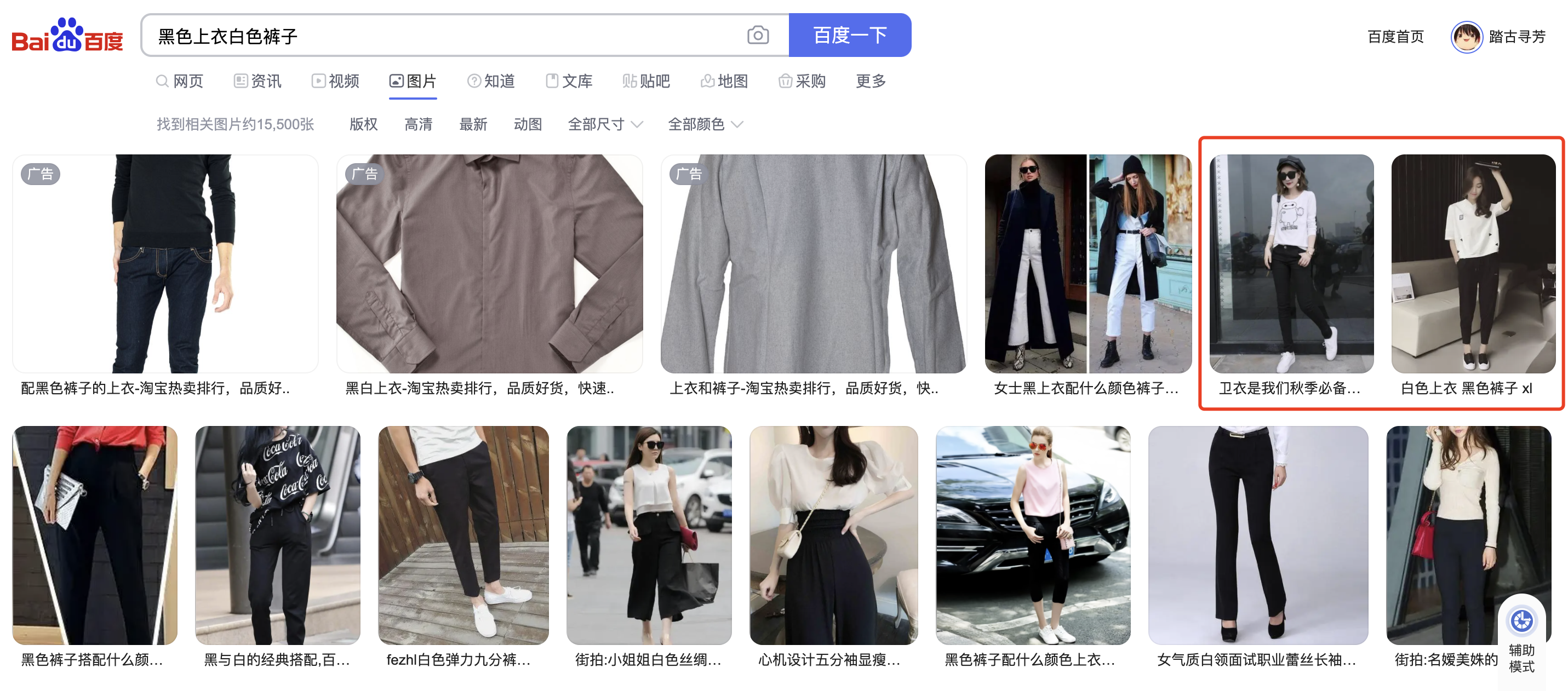
这个世界没有银弹,双塔模型中的图片和文本信息不能在线交互的特性决定了其对一些细致的图文匹配需求无法满足。举个例子,比如去搜索『黑色上衣白色裤子』,那么百度返回的结果如图Fig 1.2所示,除去开始三个广告不计,用红色框框出来的Top3结果中有俩结果都是『白色上衣黑色裤子』,显然搜索结果并没有理解到『黑色上衣』和『白色裤子』这两个概念,而是单独对『黑色』『白色』和『上衣』『裤子』这两个属性进行了组合,因此才会得到『白色上衣黑色裤子』被排到Top20结果的情况。
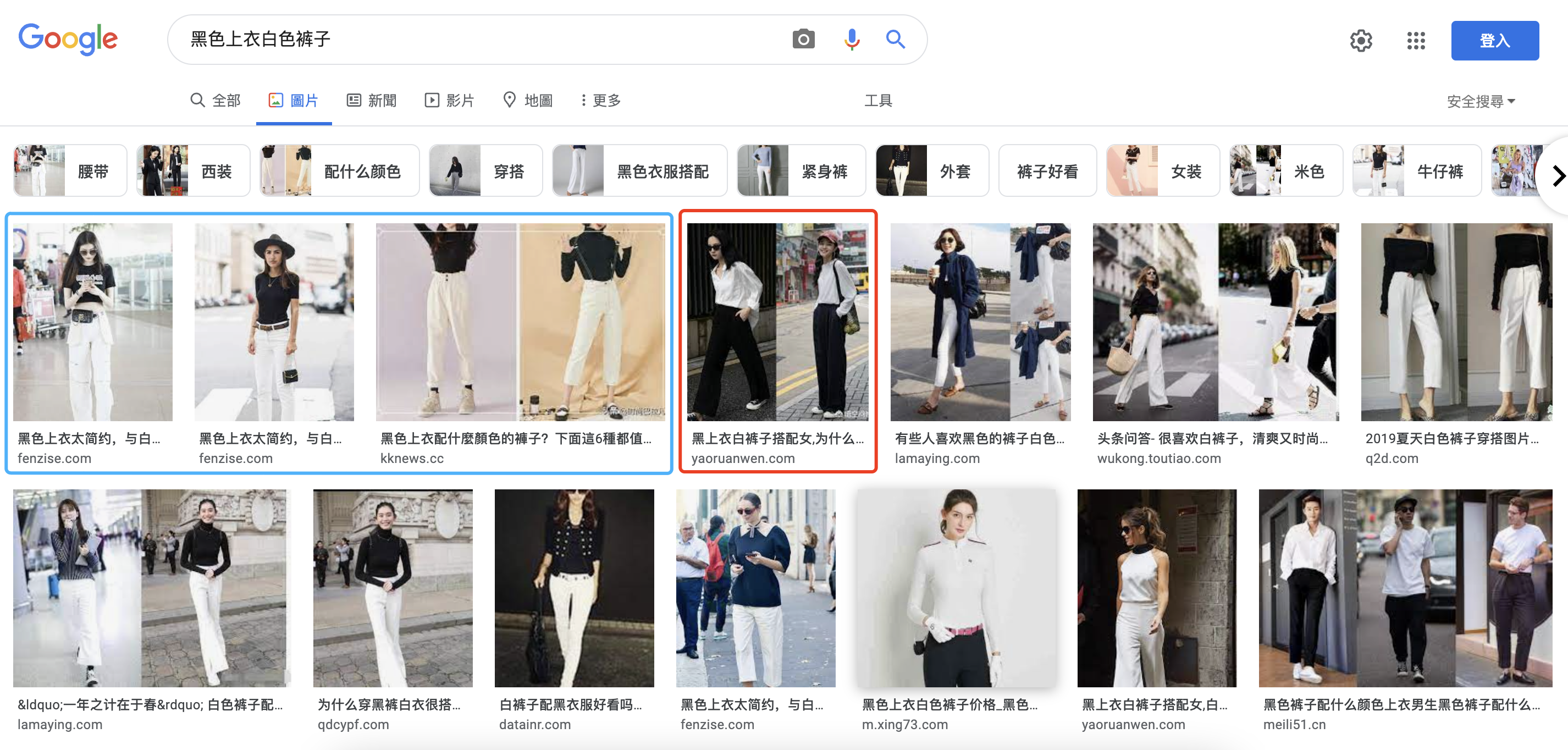
当然读者可能觉得百度搜索可能不够可靠,笔者在google图搜上也进行了测试,如Fig 1.3所示,的确大部分结果都是正确的(如蓝色框所示),但是也有少量的『白色上衣黑色裤子』被排上了Top20结果(如红框所示),即便只有几个误排,也说明业界中对于这种细粒度的多模态搜索仍然是需要继续探索的(读者可以试试『红色杯子』这类型的Query,排到Top20的都是很准确的)。
这种多模态匹配细粒度结果不尽人意的原因,很大程度上是双塔模型中的图片编码器和文本编码器无法在线进行交互导致的。可以想象到,我们的图片编码器由于是预先对所有图片提特征进行建库的,那么就无法对所有属性的组合都进行考虑,必然的就会对一些稀疏的组合进行忽略,而倾向于高频的属性组合,因此长尾的属性组合就无法很好地建模。双塔模型这种特点,不仅仅会使得多属性的Query的检索结果倾向于高频组合,而且还会倾向于图片中的一些大尺寸物体,比如Fig 1.4中的小黄人尺寸较小,在进行特征提取的时候,其在整张图片中的重要性就有可能被其他大尺寸物体(比如键盘和显示屏等)掩盖。

单塔模型进行在线交互
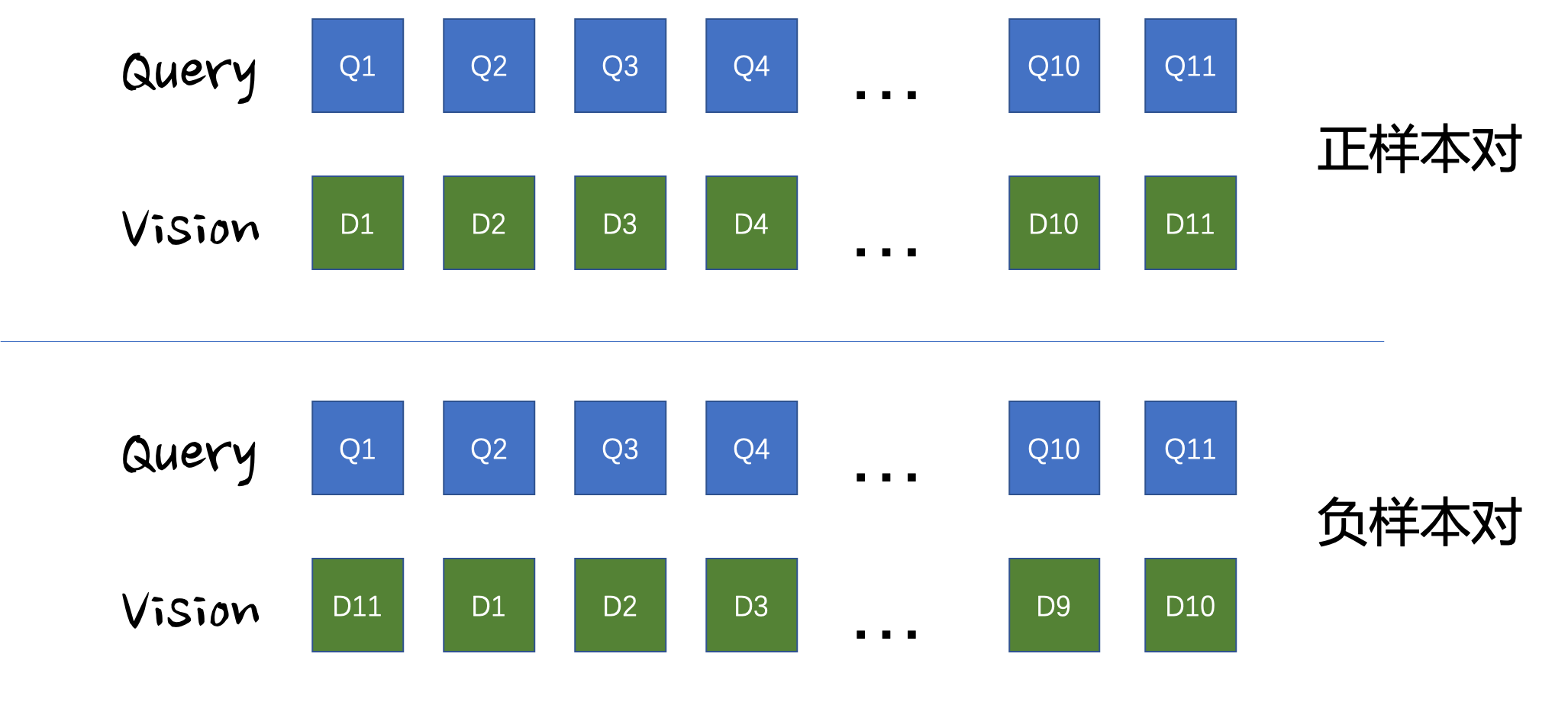
双塔模型有以上的一些天然的劣势,此时就需要用单塔交互模型对用户Query和图片进行在线的交互(当然此时模型计算由于是在线的,受限于计算资源就只能对粗排的Top20/40等结果进行打分精排了),通过在线交互,细粒度的图文匹配能取得更好的结果,稀疏的属性组合也能通过在线交互得到合理的打分,而不至于被高频组合给『吃掉』。双塔模型一般可以通过大规模对比学习,从诸多负例中挑选出最难的负例,通过将正例和最难负例进行对比损失优化,从而学习出表征。但是单塔模型无法像双塔模型一般进行对比学习去挑选难负样本,因为双塔模型可以通过打分矩阵将
多模态语义融合前的语义对齐
由此来看,单塔模型擅长的往往是语义融合(Semantic Fusion),而非语义对齐(Semantic Alignment),我们可以考虑用大规模对比学习去进行语义对齐,而基于良好的语义对齐用单塔模型去进行语义融合。如Fig 3.1所示,语义对齐尝试找到不同文本实体(Query Entity)与视觉实体(Vision Entity)之间的关联关系,而语义融合尝试找到复合实体的组合关系。
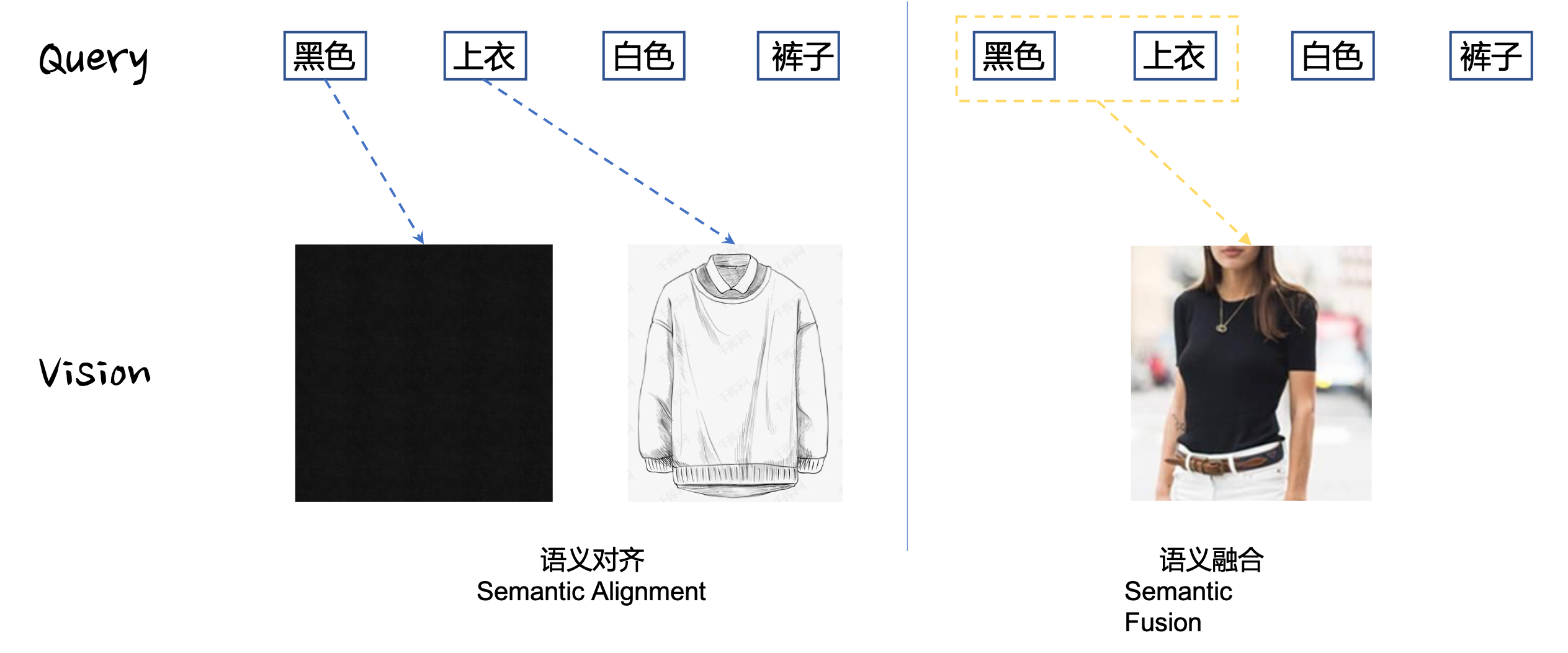
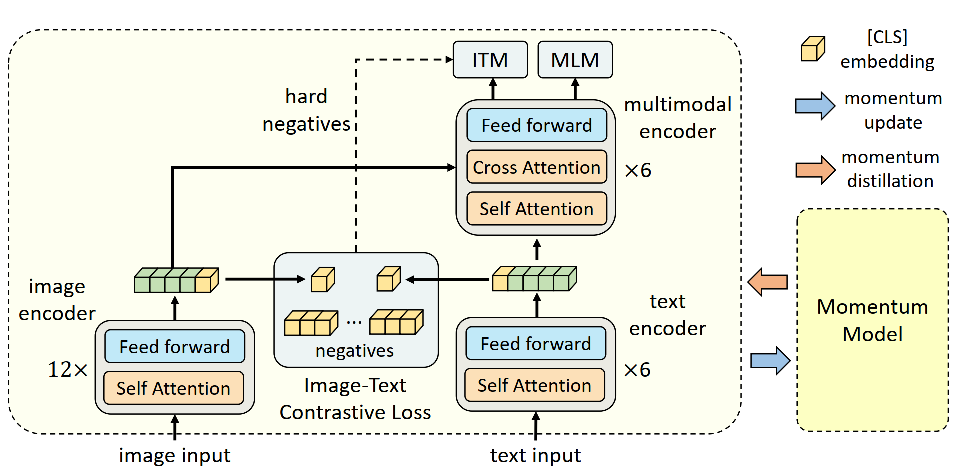
文章[1]提出了ALBEF模型(ALign BEfore Fuse,ALBEF),尝试通过将双塔模型和单塔模型结合在一起,通过用双塔模型去进行语义对齐,并且通过双塔模型进行难负样本挑选,以备送给单塔模型进行更好的语义融合,这个思路理论上可以融合单塔模型和双塔模型的优点,而不至于带来太多的计算负担。如Fig 3.1所示,ALBEF整个模型主要由BERT组成,其编码器分为单模态(Unimodal)编码器和多模态(multimodal)编码器,单模态编码器主要由图像编码器和文本编码器组成,其图像编码器采用了12层的ViT-B/16模型,而文本编码器和多模态编码器都采用的是6层的
- 语义对齐: 通过单模态编码器(其实就是双塔模型)进行图文对比学习(Image-Text Contrastive Learning)进行图文语义对齐
- 语义融合:将语义对齐后的图/文特征在多模态编码器中进行跨模态交互,通过Masked Language Model(MLM)和图文匹配(Image-Text Matching)任务进行图文语义融合。
语义对齐
语义对齐可以通过双塔模型的大规模对比学习进行,其目标是让图片-文本对的相似度尽可能的高,也就是[CLS]的线性映射,其将[CLS]特征维度映射到了多模态共同特征子空间。类似于MoCo [8,9],在ALBEF模型中,作者同样采用了两个图片/文本样本队列和动量图片/文本编码器,这两个队列维护了最近的动量编码器的batch size(这一点是代码实现,和论文有些偏差[10])
语义融合
ALBEF模型的底层是双塔语义对齐,其上层是单塔语义融合,为了实现语义融合,论文中采用了Masked Language Model(MLM)损失进行建模。作者以[MASK],令
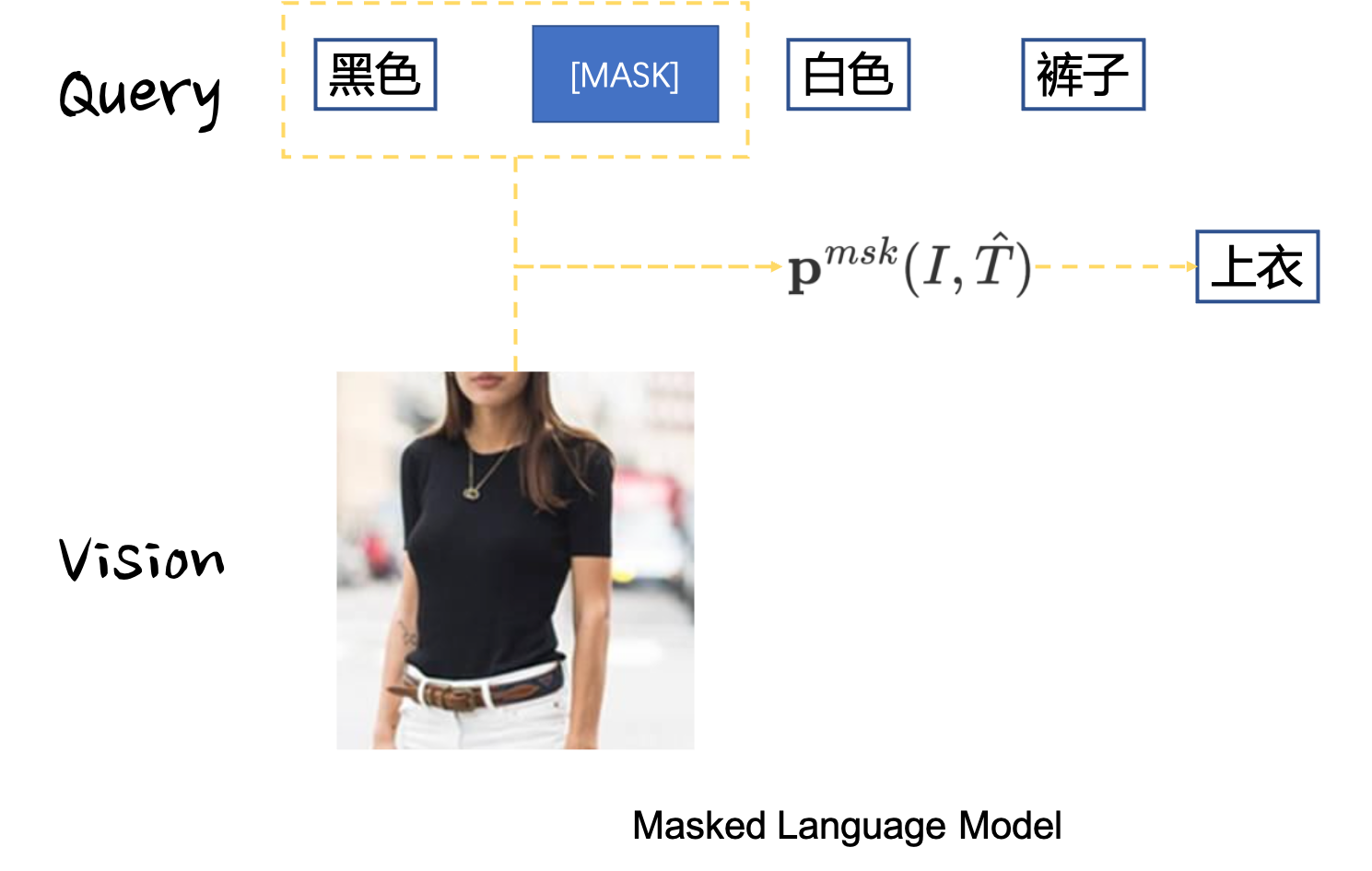
除了MLM损失,文章中还通过图文匹配损失(Image-Text Matching,ITM)对难负样本进行匹配学习,从而期望模型能够对难负样本有着更好的区分能力,从而弥补单塔模型无法进行难负样本选取的缺点,以提升多模态模型的语义对齐和语义融合能力。作者挑选难负样本的依据是根据双塔模型的打分,从式子(3-2)中可以挑选出同一个Query下面最为难的Image(打分最高,但却是预测错误的),也可以挑选出同个Image下最难的Query(论文中是根据打分大小设置概率进行采样得到的)。由此可以得到
最后的预训练阶段损失由以上三个损失构成,如式子(3-6)所示:
动量蒸馏(Momentum Distillation, MoD)
用于预训练的图文数据大多来自于互联网 [3],通常都是所谓的弱标注数据集,文本中可能有些词语和图片的实体是毫无关系的,图片也可能包含有文本中完全没提到的东西。对于ITC损失而言,一个图片的负样本文本也有可能能够匹配上这个图片(特别是如果该图文对数据来自于用户点击数据);对于MLM损失而言,被掩膜掉的令牌也许被其他令牌替代也能对图像进行描述(甚至可能更合适)。作者认为,在ITC和MLM任务中采用one-hot标签进行训练会对所有的负例进行打压,而不考虑这些负例倒底是不是真正的『负例』。为了解决这个问题,作者提出动量编码器可以看成是单模态/多模态编码器的一种指数滑动平均版本(exponential-moving-average),可以通过动量编码器去生成ITC和MLM任务的『伪标签』,笔者并没有特别理解为什么可以通过动量编码器去生成伪标签,可能这样做能使得标签更为平滑,而不像one-hot标签一样吧。总而言之,通过动量编码器,我们有动量编码器打分:
读后感
这篇文章比较复杂,最近笔者比较忙看了好久才大致看懂些,有些细节猜不透的去看了下代码,发现代码实现好像有些和论文有差别,后续有空再补充下代码实现的阅读笔记可能会更好些。总体来看,这篇文章结合了双塔模型可以进行大规模对比学习,和单塔模型可以进行细粒度交互的优势,提出了ALBEF模型对多模态数据进行语义对齐+语义融合,其思路是值得在业界进行尝试的。
Reference
[1]. Li, Junnan, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. "Align before fuse: Vision and language representation learning with momentum distillation." Advances in Neural Information Processing Systems 34 (2021).
[2]. https://blog.csdn.net/LoseInVain/article/details/121699533
[3]. https://blog.csdn.net/LoseInVain/article/details/120364242
[4]. https://fesian.blog.csdn.net/article/details/119516894
[5]. Huo, Yuqi, Manli Zhang, Guangzhen Liu, Haoyu Lu, Yizhao Gao, Guoxing Yang, Jingyuan Wen et al. "WenLan: Bridging vision and language by large-scale multi-modal pre-training." arXiv preprint arXiv:2103.06561 (2021).
[6]. Fei, Nanyi, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu et al. "WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model." arXiv preprint arXiv:2110.14378 (2021).
[7]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.
[8]. https://fesian.blog.csdn.net/article/details/119515146
[9]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738).
[10]. https://github.com/salesforce/ALBEF/issues/22