在之前的博文[1,2]中已经说明了在对比学习中提高batch size的巨大作用,然而在大尺度对比学习的训练过程中,被广泛实践证明有效的Batch Norm层则很容易出现过拟合的现象。
前言
在之前的博文[1,2]中已经说明了在对比学习中提高batch size的巨大作用,然而在大尺度对比学习的训练过程中,被广泛实践证明有效的Batch Norm层则很容易出现过拟合的现象。笔者在本文对该现象进行笔记,并且纪录其解决方案。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

在大尺度的对比学习训练过程中,Batch Norm层所造成的过拟合现象被众多公开论文所报道过,比如MoCo[3], SimCLR[4]和其他一些工作[5]。之前笔者在MoCo的笔记中也简单谈到过这个问题[1],然而当时尚未深究,现在在工作中实际遇到了这个问题,就权当笔记将其纪录。
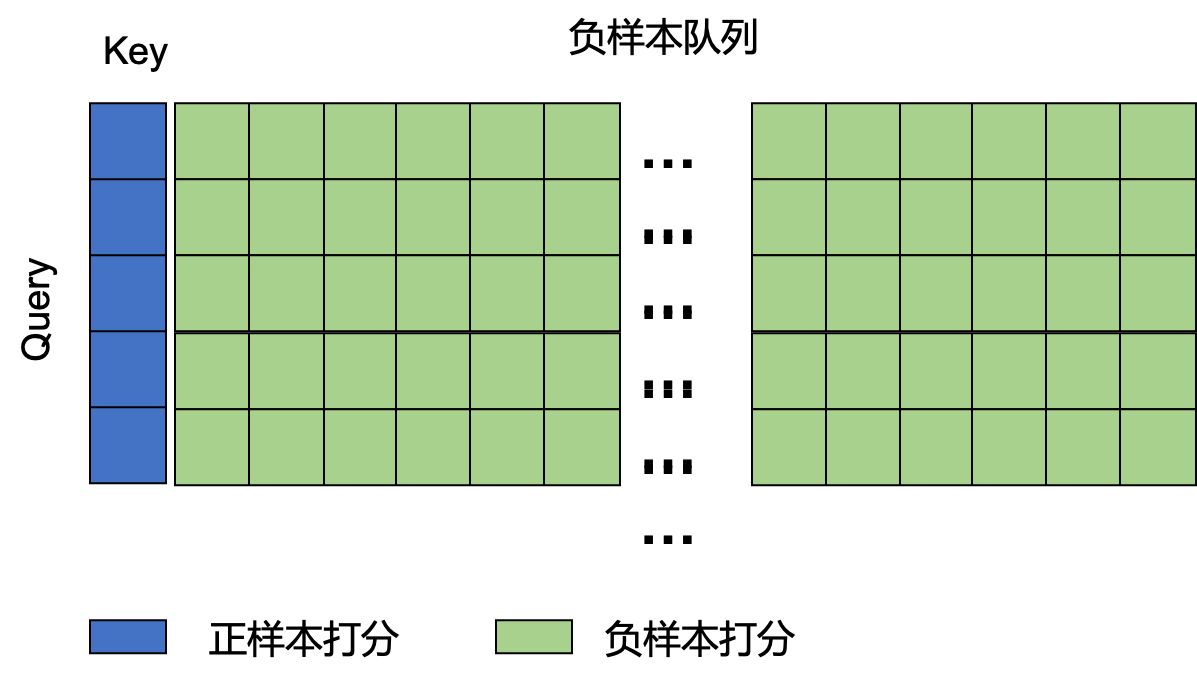
在大尺度的对比学习中,一种常见的实践是:设置一个较大的batch size,比如4096,显然一张GPU卡很难塞下,特别是在多模态模型中,因此通过数据并行将大batch size均分到不同卡上,比如16张卡。在双塔模型中,我们需要对两个塔输出的特征进行计算得到打分矩阵,如Fig 1所示。然而分布在不同卡上的双塔特征
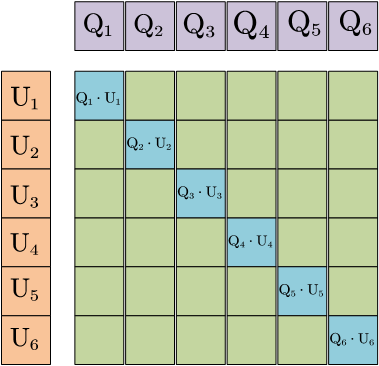
一种实现这种方式的实践是通过各个深度学习框架提供的all_gather机制,比如pytorch中的torch.distributed.all_gather() [6]或者paddle中的paddle.distributed.all_gather() [7]。这些函数可以从所有的GPU中汇聚某个矩阵,比如特征矩阵
然而,这只是大尺度对比学习的第一步,我们发现在汇聚特征之前,特征的计算都是在各自的GPU中进行计算的,假如模型中具有Batch Norm层,那么其统计参数all_gather机制,会导致在大尺度对比学习训练过程中的严重过拟合现象。然而BN的统计参数导致的过拟合问题并不只在存在all_gather机制的对比学习模型中存在,注意到MoCo看成是维护了一个负样本队列[1],因此可以视为不采用all_gather机制,也可在单卡上进行超大batch size的训练。然而MoCo也会遇到BN层的统计参数泄露信息的问题。且让笔者慢慢道来。
一般来说,提高负样本数量的方法有以下几种:
- 端到端,此时通过
all_gather机制可以扩大batch size,进而扩大负样本数量。 在这种方式下,负样本数量和batch size耦合。 - MoCo,这种方法通过负样本队列和动量更新保证了Query-Key编码器的状态一致性和足够大的负样本词表。 在这种方式下,负样本数量和batch size解耦。
- Memory Bank [10],此时通过维护一个负样本数据库,称之为memory bank进行,然而此时的Query-Key编码器不是一致状态的,Key编码器永远落后于Query编码器。
| 提高batch size的方式 | 提高负样本数量的方式 | batch size和负样本数量是否耦合 | Query-Key编码器状态一致性 | 正样本对中QK编码器是否状态一致 | 是否会遇到BN层统计参数泄露 | |
|---|---|---|---|---|---|---|
| 端到端 | all_gather | 通过提高batch size | 是 | 一致更新 | 一致更新 | 是 |
| MoCo | 一般无需提高batch size | 通过维护负样本队列 | 否 | 一致更新 | 一致更新 | 否 |
| Memory Bank | 一般无需提高batch size | 通过维护负样本队列 | 否 | 不一致,Key永远落后于Query | 不一致, | 否 |
我们留意到,并不是所有方法都会收到BN层信息泄露问题的,只有在(正样本对)Query-Key编码器一致更新的模型中才会遇到,而在Memory Bank中就不会遇到。其中,我们先讨论端到端的形式中的BN层信息泄露。注意,我们这里说的状态一致,或者一致更新,并不是指的数值上的一致,而是假使存在一个训练状态,这两者是同步的。
端到端模式的对比学习
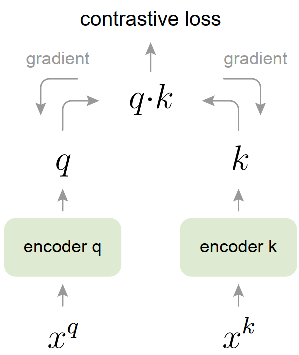
在端到端模式的对比学习过程中,Query-Key编码器是一致更新的,简单来说就是两个塔的参数在同个step中进行更新。此时如果采用了多卡进行all_gather,并且采用的BN层是异步BN(也就是每张卡的统计参数all_gather之后,其形成的打分矩阵如Fig 3所示。Fig 3中的不同颜色块表示来自于不同GPU上的正样本Query-Key对,省略号表示的是通过不同卡汇聚得到的特征进行打分。我们注意到由于异步BN的原因,不同颜色块上的统计参数是不相同的,而正样本显然又位于打分矩阵的对角线上,正样本都由同一个GPU进行计算,此时由gather得到的诸多负样本的统计参数会和同一个GPU下的正样本的统计参数存在明显差别。由BN的计算公式(1)可知,不仅通过学习表征,通过『学习』统计参数也可以『等价』于学习表征,让模型『预测』正样本的位置。然而,这种『等价』并不是真正的等价,而『预测』也不是通过真正学习表征得到的,因此表现为过拟合,严重影响模型的表征性能,这个情况笔者称之为BN层统计参数泄露。在这种情况下,由于统计参数泄露了『正样本所在于对角线』这个秘密,导致表征学习以失败告终。 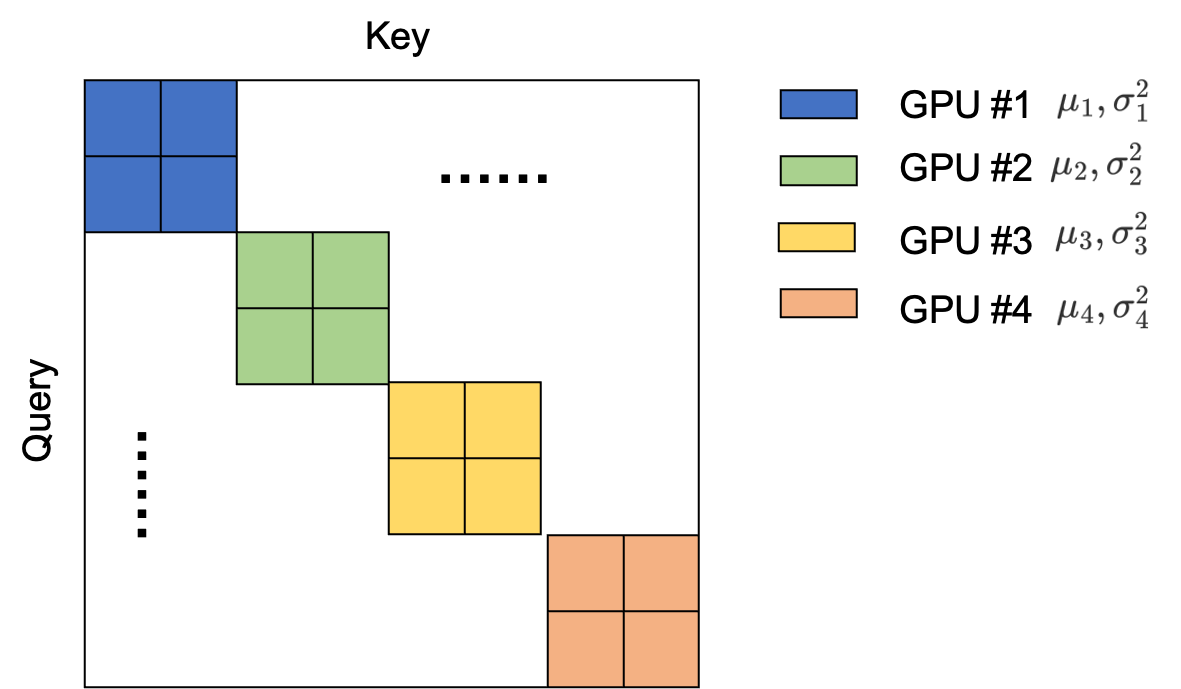
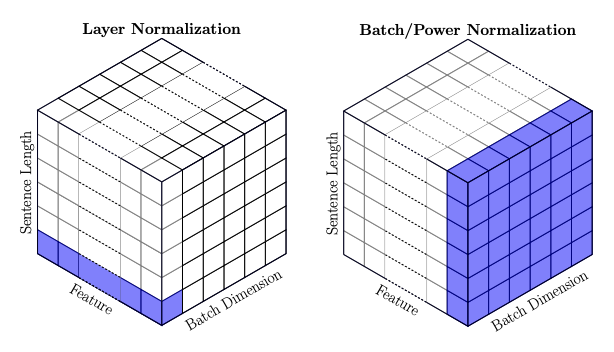
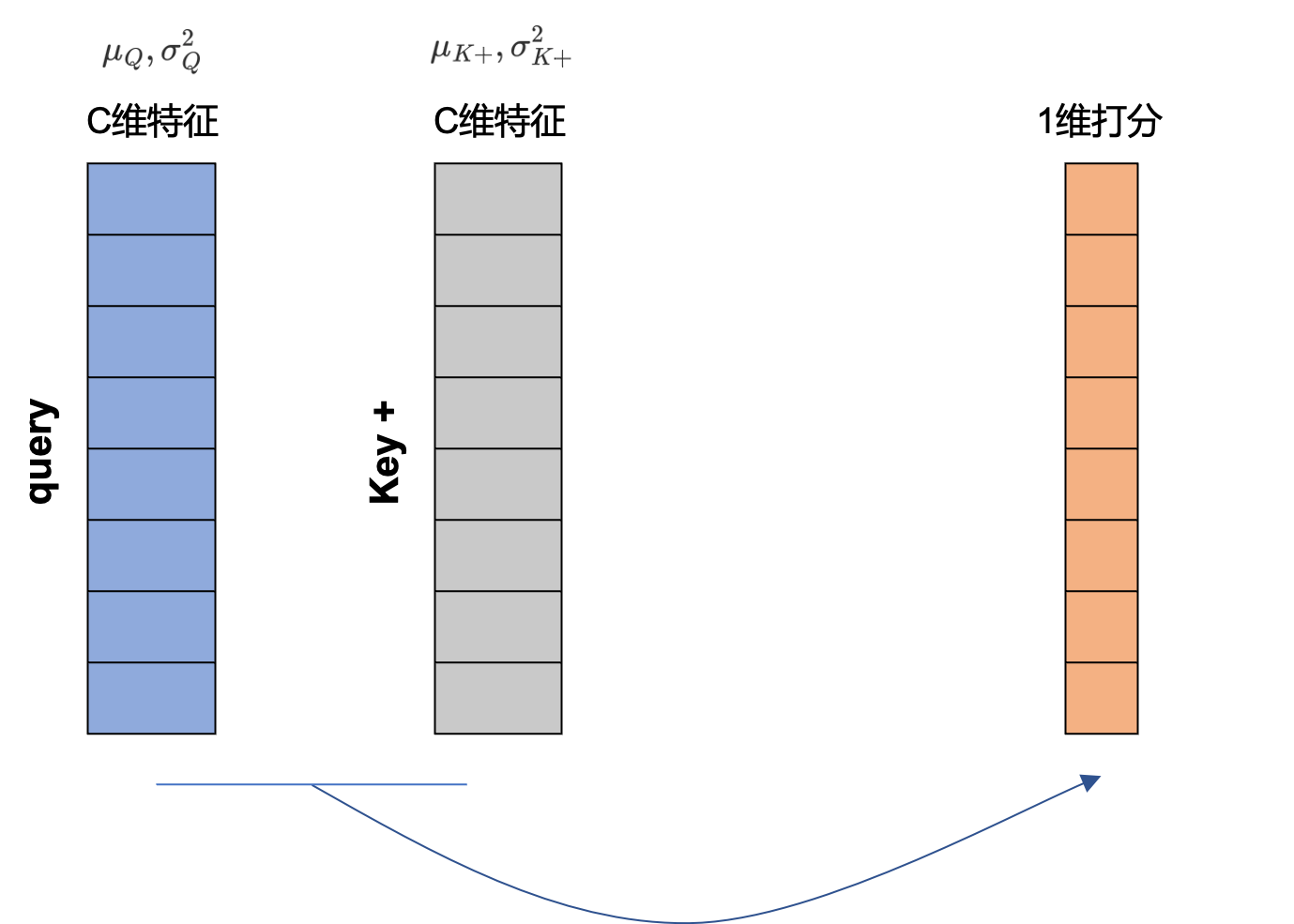
从以上的分析来看,在端到端模式下导致统计参数泄露的本质还是在于统计参数都是在各自的GPU中进行计算的,那么解决方案自然要从这里着手。在simCLR[4]中,作者提出的方案是采用所谓的Global BN,其方法就是同样gather不同GPU上的统计参数,然后计算出一个新的统计参数后分发到所有GPU上,此时所有GPU的统计参数都是相同,也就谈不上泄露了。当然你还可以用更简单的方法,比如在[5]中,作者采用Layer Norm取代了Batch Norm。从Fig 4.中可以看出,Layer Norm进行统计参数计算的维度是[Feature, Channel],而不涉及Batch维度,统计参数不会跨Batch使得统计参数不会泄露样本之间的信息。
这个方法相当地直观,因为最理想的情况下,我们应该对所有的正负样本一个个地送到编码器中,以达到完全隔离不同样本之间的目的,通过将BN替换成LN,达到了这个目的。
MoCo
还有一种非常火的实践是何凯明大佬的MoCo[3,1],这种方式不仅需要维护一个大尺度的负样本队列,还需要用动量更新的方式去一致更新Query-Key编码器,如Fig 5.所示。此时的负样本数量的提升不是由于all_gather机制导致的,并且负样本数量和batch size也是解耦了。因此这种情况下,我们认为即便是单GPU也可以跑很大的负样本数量的对比学习。那么此时在上文所说的BN层统计参数泄露问题在MoCo中存在吗?
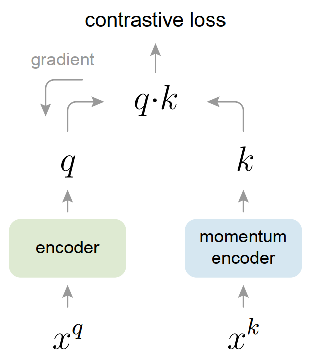
很遗憾,即便在MoCo中,BN层的统计参数泄露还是存在的,但是原因显然不是由于多GPU的异步BN统计参数导致的,因为即便只有一张卡也可以理论上跑MoCo。如Fig 6.所示,此时正样本打分的计算如Code 1.所示,是通过对某个样本进行数据增广后,将其视为正样本,再进行打分。这个部分也就是Fig 6.的蓝色部分。而负样本是直接采用Key-负样本队列中的特征,直接和Queryt特征进行打分,如Fig 6.的绿色部分所示。注意到代码中的k = k.detach(), 这意味着构造出来的正样本的梯度流只会更新Query编码器,而Key编码器是通过动量更新的。
1 | f_k.params = f_q.params # initialize |
即便在MoCo中不通过正样本构造的k进行key编码器的更新,但是同个step中,将会通过式子(2)进行动量更新,因此QK编码器的更新也是一致的。
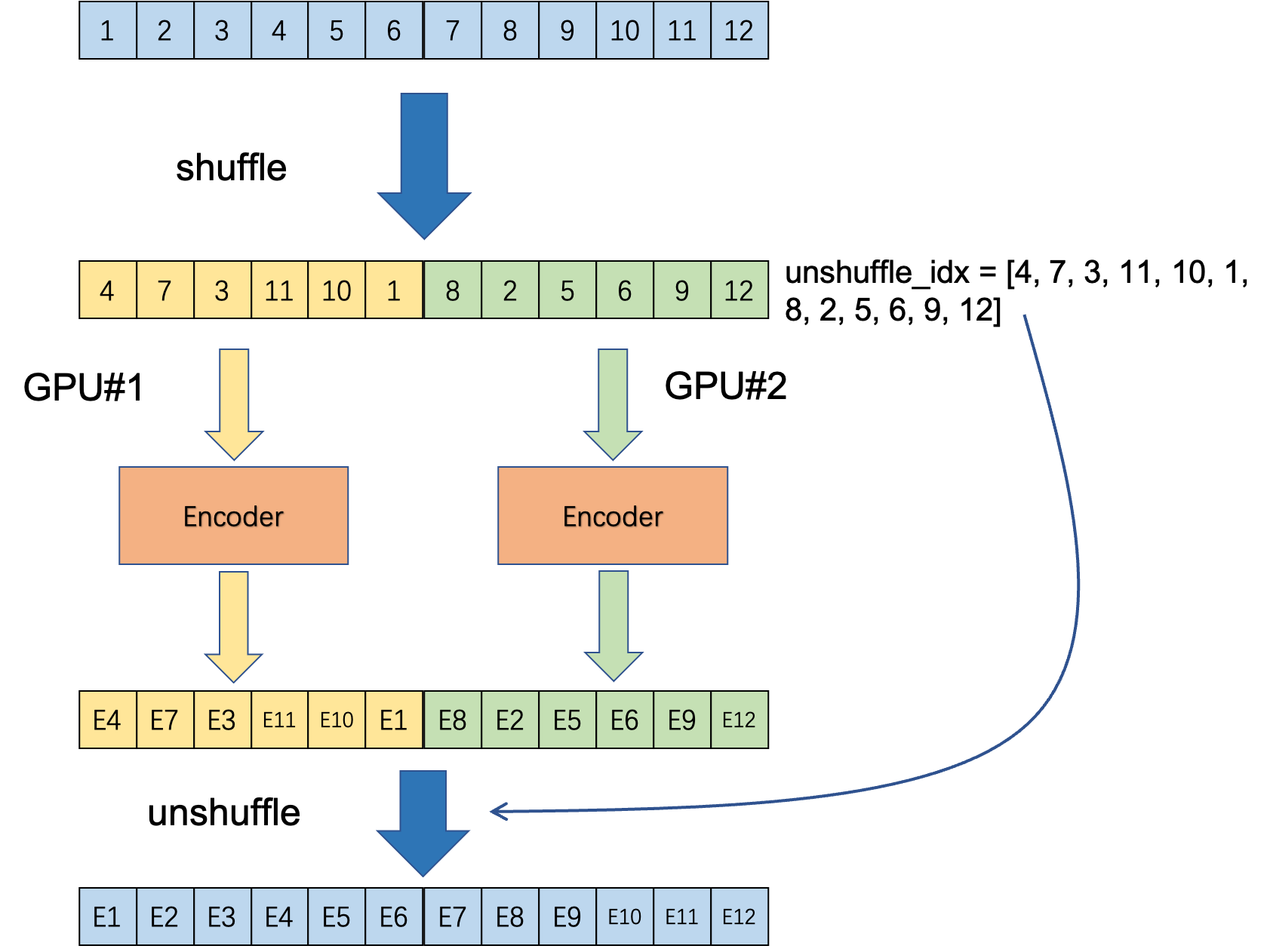
因此,虽然MoCo和端到端的方式中数据组成方式大相径庭,但是BN层的统计特征在QK编码器一致更新的过程中,都存在泄露正样本的位置的可能。为了解决这个问题,在MoCo中采用的是Shuffling BN,分为以下几个步骤,注意Shuffling BN必须运行在多卡环境下:
- 将输入进行
all_gather,并且进行随机打乱,此时需要记下打乱后的索引unshuffle_idx,因为最后需要『反打乱』回一开始的样本顺序。 - 将打乱后的样本平均分发到
个GPU上,每个GPU上的batch size大小为 。 - 通过Key编码器计算特征
,注意到Key编码器中存在BN层,比如经典的 resnet结构。 - 将所有GPU上计算得到的特征
进行 all_gather,并且通过unshuffle_idx进行反打乱回原来的样本顺序。
整个逻辑的示意图如Fig 8所示。整个过程其实就是通过打乱和分发到多个GPU,实现统计参数的打乱,解耦统计参数和正样本位置的关联。Shuffling BN通过打乱实现随机,而Global BN通过gather->分发的方式实现统计参数的全局统一。一个是『打乱』一个是统一,这些手段都保证了BN的统计参数不会带有正样本的位置信息。
Memory Bank
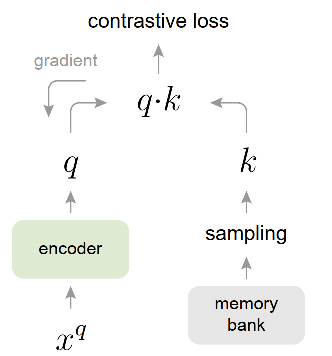
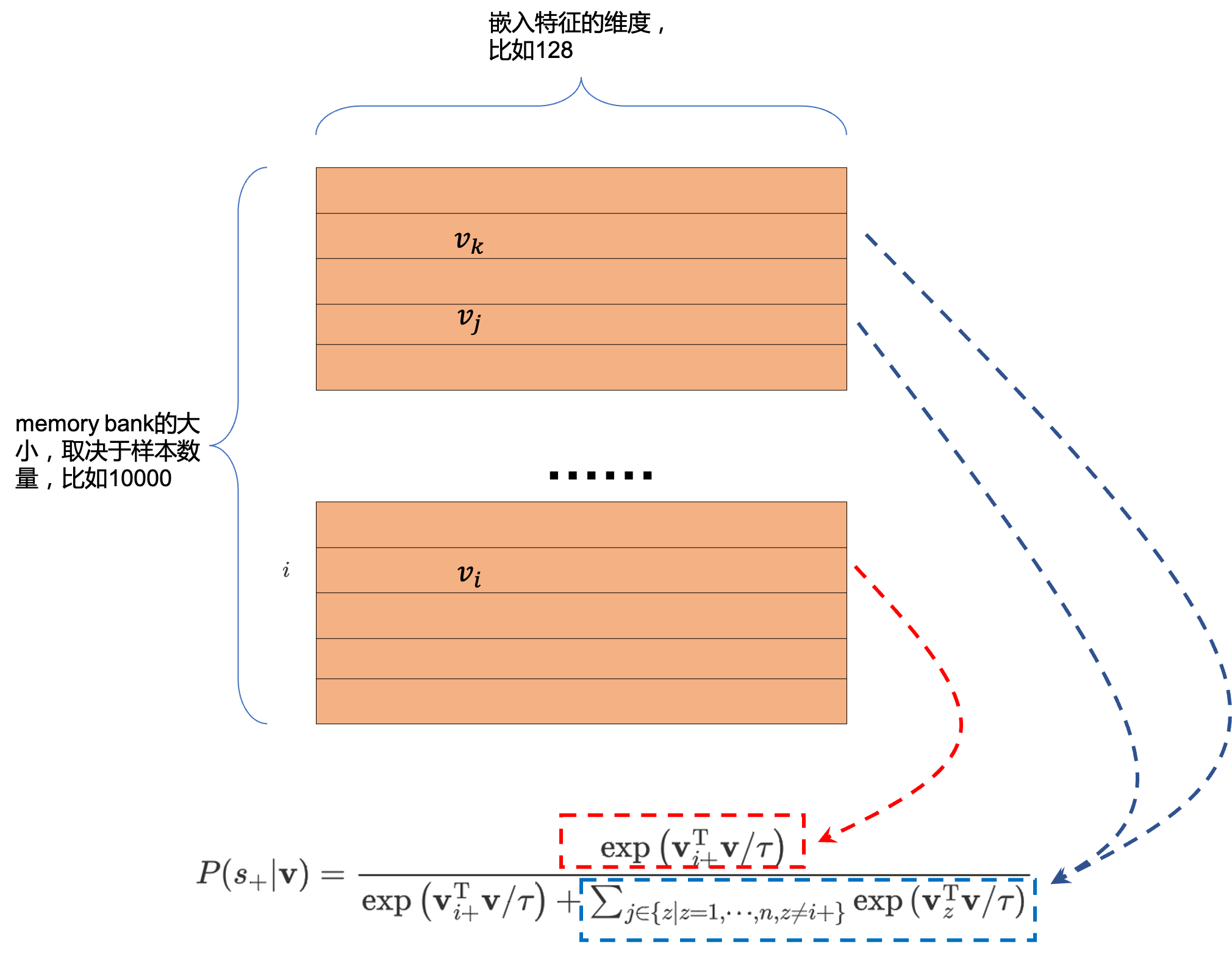
然而,在memory bank [10, 12]中却并不会出现BN层统计参数泄露的问题,那是因为memory bank是通过『异步』的方式取正样本key的。具体而言,如Fig 9.所示memory bank维护了一个负样本队列
而我们如果采用相关性计算的方式计算样本之间的距离,那么就可以形成如式子(4)所示的非参数化的交叉熵损失(其中的
因此,按照这个逻辑,此时我们计算正样本的相关性时候,采用式子(5)
说在最后
对于对比学习的研究,在学校中,我们没有足够的计算资源和超大型的数据量,因此比较难发现在大batch size甚至是超大batch size下才会出现的BN层统计参数泄露问题。目前在学术界有报道这个问题的文章据笔者了解也就[3,4,5]这几篇。然而在公司的实践中,在面对数以亿计的大量数据时,简单粗暴地提高batch size将导致意料外的结果,因此笔者将其进行笔记,希望对读者有所帮助。此外,以上结论并不一定在所有数据集上都成立,我们发现数据集的特性也很重要,如果读者在相同实践中也遇到了对比学习的过拟合问题,不妨也可以往着BN层统计参数泄露这方面考虑。
Reference
[1]. https://fesian.blog.csdn.net/article/details/119515146
[2]. https://fesian.blog.csdn.net/article/details/119516894
[3]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738).
[4]. Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.
[5]. Hénaff, O. J., Razavi, A., Doersch, C., Eslami, S., and Oord, A.v. d. Data-efficient image recognition with contrastive predictive coding. arXiv preprint arXiv:1905.09272, 2019.
[6]. https://pytorch.org/docs/stable/distributed.html#torch.distributed.all_gather
[7]. https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/distributed/all_gather_cn.html
[8]. https://blog.csdn.net/LoseInVain/article/details/86476010
[9]. Memory Bank Code: https://github.com/zhirongw/lemniscate.pytorch
[10]. Wu, Z., Xiong, Y., Yu, S. X., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3733-3742).
[11]. https://github.com/facebookresearch/moco/blob/master/moco/builder.py
[12]. https://github.com/zhirongw/lemniscate.pytorch