【论文极速看】CLIP-Lite:一种不依赖于负样本数量的高效多模态学习方法
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

传统的CLIP [1]对比学习模型依赖于海量的图文对训练数据,以及每个正样本对应的负样本的数量,为了弥补CLIP模型对于负样本数量的极度依赖,而单纯通过当前batch size提供足够的负样本又强烈依赖于显卡资源的现况,有些方案提出采用虚拟batch size(即是memory bank)进行弥补 [2]。MoCo [3]模型提出采用动量编码器和负样本队列的方式,可以利用训练历史上的负样本,从而扩大了参与训练的负样本数量。
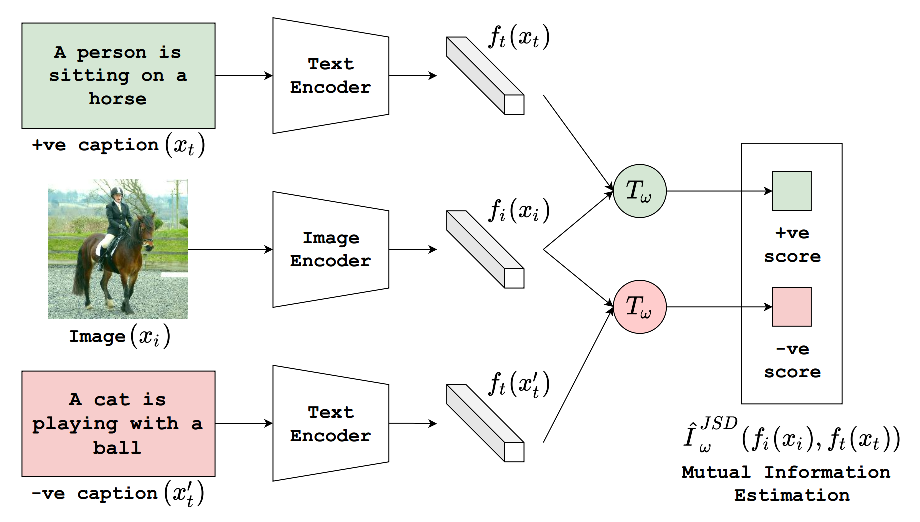
在文章[4]中,作者提出了CLIP-Lite,该模型通过Jensen-Shannon散度对互信息进行下界估计,而不是像CLIP采用infoNCE对互信息进行估计。互信息(Mutual Information, MI)描述了『在知道某个随机变量
对互信息进行优化在表征学习中有着广泛地应用,通过最大化互信息可以学习到更好的表征。不难看出,互信息可以用Kullback-Leibler(KL) 散度表示,为: 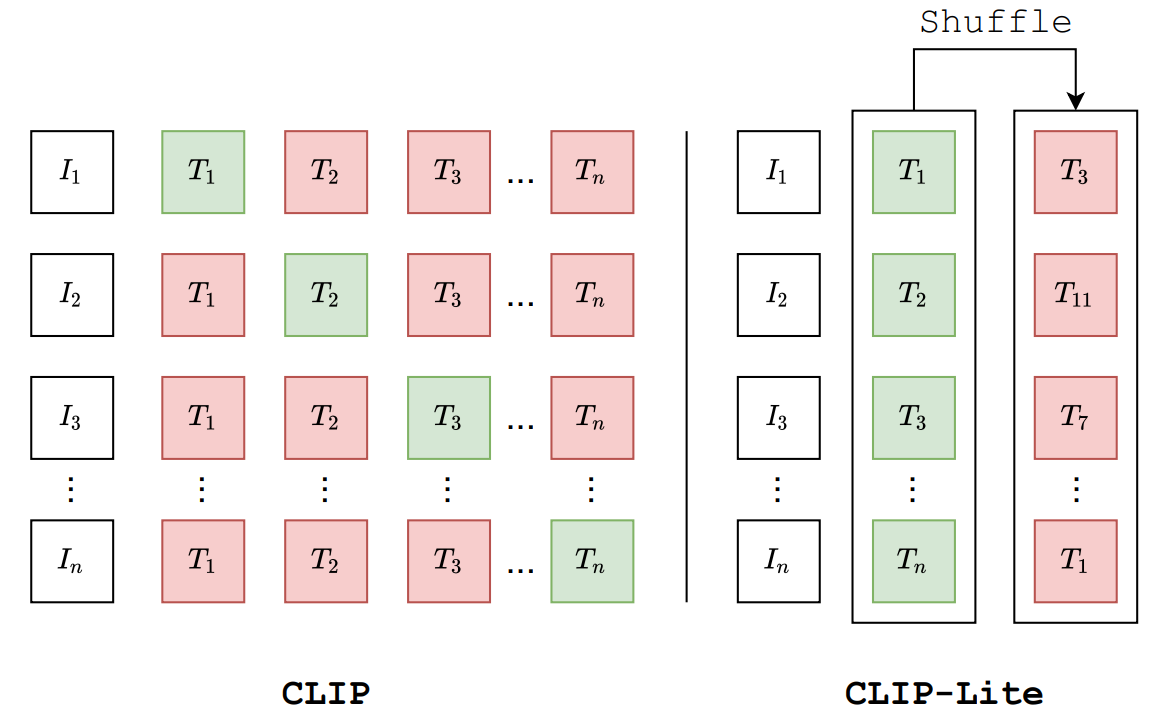
其中的
Reference
[1]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.
[2]. https://fesian.blog.csdn.net/article/details/119515146
[3]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738).
[4]. Shrivastava, Aman, Ramprasaath R. Selvaraju, Nikhil Naik, and Vicente Ordonez. "CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations." arXiv preprint arXiv:2112.07133 (2021).
[5]. M.D Donsker and S.R.S Varadhan. Asymptotic evaluation of certain markov process expectations for large time, iv. Communications on Pure and Applied Mathematics, 36(2):183–212, 1983.
[6]. Hjelm, R. Devon, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. "Learning deep representations by mutual information estimation and maximization." arXiv preprint arXiv:1808.06670 (2018).