笔者在前文 [1] 中曾经介绍过一种大规模图文匹配模型BriVL,该模型基于海量数据进行对比学习预训练,从而可以实现很强的多模态建模能力。WenLan 2.0是该工作的后续探索,本文尝试简单对其进行笔记。
前言
笔者在前文 [1] 中曾经介绍过一种大规模图文匹配模型BriVL,该模型基于海量数据进行对比学习预训练,从而可以实现很强的多模态建模能力。WenLan 2.0是该工作的后续探索,本文尝试简单对其进行笔记。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

本文在 [1] 的基础上进行,为了行文简练,将会省略部分细节,读者自行斟酌是否需要移步 [1] 补充相关背景知识。
WenLan 2.0的改进
WenLan 2.0 [2] 对比其前辈 WenLan 1.0 [3],其有两个最大的区别:
- 从行文上看,整篇文章叙事更为宏大,从通用智能AGI开始讨论到了人类的概念认知能力,进而引申到了模型的『想象能力』,从而笔锋一转到了自家的BriVL模型。
- 从技术上看,该工作去除了前文中的Object Detector,因此是不依赖于物体检测结果的图文匹配模型,这个特点使得该工作更适合与实际工业界中的应用,因为涉及到了物体检测意味着需要更多的计算消耗。
- 采用了更大的互联网图文数据集进行预训练,数据规模多达6.5亿图文对,并且由于数据来自互联网爬虫得到,没有进行过人工标注,数据更接近与真实生活数据,作者称之为弱语义相关数据集 (Weak Semantic-Correlation Dataset, WSCD),具体关于图文检索中的弱语义场景可见博文 [1]。该数据集对比与在WenLan 1.0中采用的3000万弱语义图文对,显然在数量级上又更上一层楼。
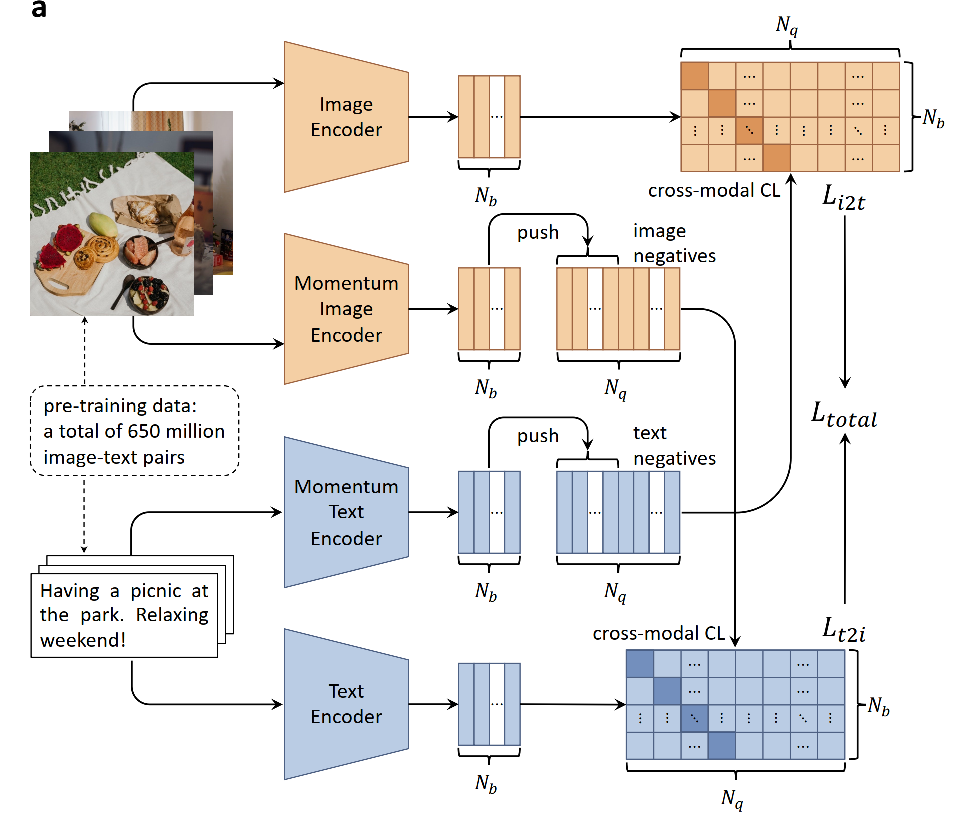
从整体模型结构上看,如Fig 1.1所示,WenLan 2.0和WenLan 1.0并没有太大区别,仅限于其图片编码器由于去除了Object Detector,因此进行了比较特殊的设计。但是注意到,之前笔者在博文 [1] 中其实在loss计算这块儿存在一个小误解,假设其Image-Encoder的图片表征为
1 | # 用爱因斯坦求和规范可以用以下计算方式 |
而实际上,在WenLan中应该是采用的打分矩阵进行的,如同CLIP一样,计算公式为: all_gather汇聚所有卡上的特征,那么此时的
1 |
|
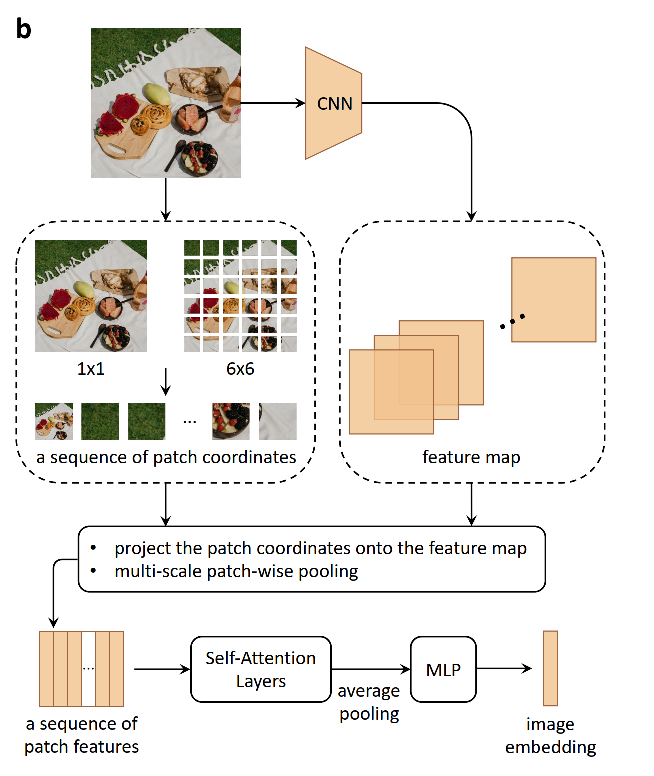
对比于WenLan 1.0前辈,其后辈去下了Object Detector的沉重负担,为了能对图片内物体位置进行建模,在2.0中对图片进行了多尺度的切分。目前来说,作者只进行了两个层次的切分,对于整张图片视为一个patch;再对整张图片均匀切分成
- 假如目前输入的图片为
,通过CNN特征提取后得到的特征图为 ; - 那么假设存在一个patch切分机制
,可以将输入图片切分成 个patch,即是 ; - 并且存在一个坐标对应函数,可以将patch坐标对应到特征图中的坐标,也即是
,从而可以通过映射后的坐标将第 个patch 的对应特征从整个特征图中扣出来,也即是 ; - 通过空间池化 (Spatial Pooling) 可以将patch特征变为一个向量,即是
; - 将这
个patch的向量化特征拼接起来,得到 的特征矩阵。
在得到了Self-Attention机制对这个矩阵进行处理,可以挖掘出patch之间的交互关系,如式子(1.2)所示。 self-Attention处理过后的
在文本编码器这块儿,同样也是采用了两层FC层+ReLU激活层的方案,将文本表征映射到了多模态公共表征层,而文本编码器的Backbone则是采用了RoBERTa [5]。至于负样本队列和动量更新的过程,在前文[1]已经有过比较详细的介绍,就不再赘述了。
模型结果可视化分析
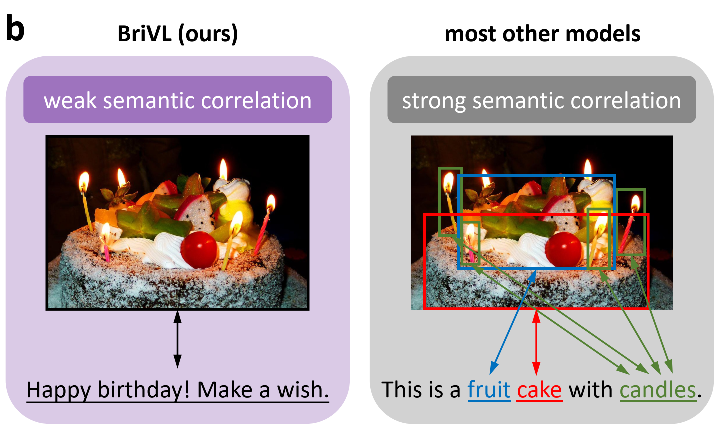
在这篇文章中,令笔者印象最深的并不是其模型结构的改变,而是文章一开始对其embedding表征结果可视化,和其利用WenLan 2.0的BriVL模型作为桥梁从文本生成图像的能力,着实让笔者惊艳,通过这种可视化方式可以分析图文多模态模型对于某些文本概念的理解倾向,算是走向『让模型理解』的第一步吧。由于采用了海量的弱语义关联图文对进行对比学习训练,模型会在一定意义上理解更为抽象的多模态语义概念。以文章的原配图为例子,如Fig 2.1所示,对于一个生日蛋糕的图片而言,所谓弱语义配对就是『Happy birthday! Make a wish.』其中并没有太多的视觉语义实体存在,但是我们知道的确这句话就是在描述这个场景,而传统的强语义图文匹配,包括Image Caption任务等,其大多都会存在明显的视觉实体的文本描述,比如『This is a fruit cake with candles.』中的『fruit, cake, candle』等。
那么利用这样的弱语义图文数据,通过大尺度对比学习学习出来的多模态模型,能达到怎样的多模态理解程度呢?作者首先在WSCD数据集上对BriVL模型进行预训练,然后选定一些概念的文本描述,比如抽象的『自然(nature), 时间(time),科学(science)』等,也可以是具象的『山川(mountains),河流(rivers)』等。然后固定BriVL模型参数,通过BriVL的文本编码器对给定的概念进行表征计算,得到文本域的多模态公共表达,记为
从Fig 2.2 a中,我们发现BriVL对于一些抽象概念,具备着很符合人类直觉的理解能力,比如『自然』,其理解为大量的植被等;对于『时间』,其具象化理解为了一个钟表;对于『科学』,其理解为带着眼镜的科学家(看起来像是爱因斯坦),和一些化学量杯等;对于『梦』,其理解也很抽象了,看起来像是一个很魔幻的天空,然后一条长桥伸向一个未知的大门,而左下角还有个奇异的生物注视着你。Fig 2.2 b中则是对于一些谚语或者是一句短语的理解,比如『Every cloud has a silver lining(雨过天晴时分)』,能看到一丝阳光穿透云层;对于『Let life be beautiful like summer flowers.(生如夏花)』,则是能明显看到一朵荷花,荷叶等。
在细粒度实验上,比如『雪山』『石山』『丛林中的小山』『瀑布边的小山』这些细分的概念上,从Fig 2.2 c中也能发现其的确也能区分出以上四个概念的区别和共同点出来。

这是从Embedding可视化的角度去探索BriVL模型的多模态理解能力,那么能否从其直接生成的图片的角度去探索呢?显然也是可以的,因为在上一步中其实通过梯度更新随机初始化图片,已经生成了文本概念所对应的图片。但是此时的这个图片并不是最符合人类直觉的图片,因为显然这个图片的假设空间很大,如果简单通过梯度更新去找到一个Embedding相似度损失足够小的图片,可能并不是视觉上最符合人类直觉的,因此一般这种任务会通过GAN去辅助图片的生成,比如这篇文章就是采用VAGAN [6] 进行辅助生成的。通过GAN的辅助,将会生成更为人类友好的图片。如Fig 2.3和Fig 2.4所示,其中Fig 2.3 a是利用CLIP [7] 模型进行的文本到图片的生成,而Fig 2.3 b是利用BriVL模型进行的文本到图片的生成。a和b可以看出有明显的风格区别,a的风格更为偏向于漫画,插画,版画的画风;而b的风格偏向于现实图片。这点可能和训练数据有关,BriVL模型的数据来自于互联网爬取的图文数据,可能互联网数据中现实图片数量更大。我们也可以发现,a中的生成图片更有『拼接感』,比如从『自然(nature)』生成的图片中就可以很明显地看出这一点;而b生成的图片则更为自然,有种浑然天成的感觉。这一点同样可能和数据集有关,采用弱语义图文数据集,某个文本实体概念并不是一定配对某个视觉实体概念,而是可能更为抽象的一个概念,而CLIP则不然,因此基于CLIP生成的图片则更具有拼接感。

而对于某些现实生活中不存在的概念,比如『火海(blazing sea)』『梦魇(horrible nightmare)』『天空之城(castle in the clouds)』『月宫(palace on the moon)』,BriVL模型同样有着不错的图像生成表现,如Fig 2.4所示。这一点很惊艳,因为这意味着模型从某种程度上理解了抽象概念,而不是去从海量数据里面拟合数据,显然这些虚拟概念在互联网数据中出现的概率远远小于真实图片(当然可能也有一定数量,但是根据笔者个人理解,虚拟的图片合成显然比真实图片生成困难,因此数量会比真实图片显著少很多)

这是这篇文章笔者比较惊艳的部分,而对于指标数据上的消融对比实验,读者可以自行去查看原论文,总得来说,采用了Self-Attention的图片编码器,并且采用MoCo机制去训练对比学习模型,能取得比较好的指标提升。
笔者读后感
就笔者看来,本文体现了『海量数据+大算力+对比学习』暴力美学的强大力量,所谓大力出奇迹,通过从互联网中挖掘海量的弱标注,弱语义相关图文数据,并且通过大规模对比学习进行训练,可以让模型学习到很不错的多模态语义理解能力。这种趋势看来,未来也许会出现所谓的『人工智能垄断』,因为这样海量的数据储存,挖掘和大算力(比如说100+的A100算力,而单卡A100价格高达7万,更别提其他外设,比如内存,CPU,磁盘等),为了训练一次这样的模型,需要的成本可能数以十万百万计,再加上调试时间成本,小公司的盈利和现金流很难hold住这样的成本,更别说小型的研究机构了。数据成本加上训练成本门槛过高,也许将会导致未来只有大型公司或者大型研究机构才能入场。
Reference
[1]. https://fesian.blog.csdn.net/article/details/120364242
[2]. Fei, Nanyi, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu et al. "WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model." arXiv preprint arXiv:2110.14378 (2021).
[3]. Huo, Yuqi, Manli Zhang, Guangzhen Liu, Haoyu Lu, Yizhao Gao, Guoxing Yang, Jingyuan Wen et al. "WenLan: Bridging vision and language by large-scale multi-modal pre-training." arXiv preprint arXiv:2103.06561 (2021).
[4]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738).
[5]. Cui, Y. et al. Revisiting pre-trained models for chinese natural language processing. In Conference on Empirical Methods in Natural Language Processing: Findings, 657{668 (2020).
[6]. Esser, P., Rombach, R. & Ommer, B. Taming transformers for high-resolution image synthesis. arXiv preprint arXiv:2012.09841 (2020).
[7]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.