我们经常会谈到“业务”一词,作为在互联网圈混的我们,也经常会听到“技术赋能业务”这一概念。笔者作为刚毕业时间不满一年的职场新人,在学校(包括在实习的时候,见[1])时期接触最多的是技术相关的内容,对“业务”这一概念其实没有太多的认识,对于技术如何给业务“赋能”更是完全没有头绪。笔者从实习开始到工作到现在也接近一年多时间了,在此尝试去理解什么是业务,以及技术如何支持业务,赋能业务。
前言
我们经常会谈到“业务”一词,作为在互联网圈混的我们,也经常会听到“技术赋能业务”这一概念。笔者作为刚毕业时间不满一年的职场新人,在学校(包括在实习的时候,见[1])时期接触最多的是技术相关的内容,对“业务”这一概念其实没有太多的认识,对于技术如何给业务“赋能”更是完全没有头绪。笔者从实习开始到工作到现在也接近一年多时间了,在此尝试去理解什么是业务,以及技术如何支持业务,赋能业务。如有谬误请联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

业务是什么 以及 技术如何赋能业务
从百度词条上看,业务被定义为 [2]:
各行业中需要处理的事务,但通常偏向指销售的事务,因为任何公司单位最终仍然是以销售产品、销售服务、销售技术等等为主。“业务”最终的目的是“售出产品,换取利润”。
从这个角度上看,业务是以销售某种东西(产品,服务,或者技术),以换取利润的商业行为。然而这个定义太过于广泛,我们无法从这句话里面提取出更多细节信息,还是需要结合一些工作经验才能更好地理解。笔者是从事互联网中的搜索业务的,更具体来说是视频搜索业务,这种业务的本质是为用户提供更为满足的搜索内容结果,从而获得用户的流量和停留。在获得了用户的青睐之后,有了足够的用户流量后,就可以考虑开始商业变现了。商业搜索引擎本身不带来太多盈利,但是成功的商业搜索引擎将带来巨大的流量,而流量变现就是它最主要的盈利方式,流量变现最主要的手段就是广告推广。如Fig 1所示,当你搜索一个Query时候,比如“机器学习”"machine learning",当系统认为这个关键词有广告需求,并且广告池里面有相对应的优质广告时,就会尝试将广告推送给用户,结果就是展现自然结果的时候同时会出现部分广告。当搜索引擎做得越好(能搜索出更多满足的结果,用户搜索成本低,用户体验好等),那么就能吸引到越来越多的用户,而吸引到的用户多了自然就有部分用户能被投放的广告所“打动”,从而转化为消费(包括购买,注册,激活,引流等等),自然会有更多广告需求接入,而投放广告自然是需要付钱的,自然就产生了盈利。因此据笔者看来,搜索引擎是间接产生盈利的一种业务,需要结合一些外部业务,比如广告,电商等才能产生盈利。
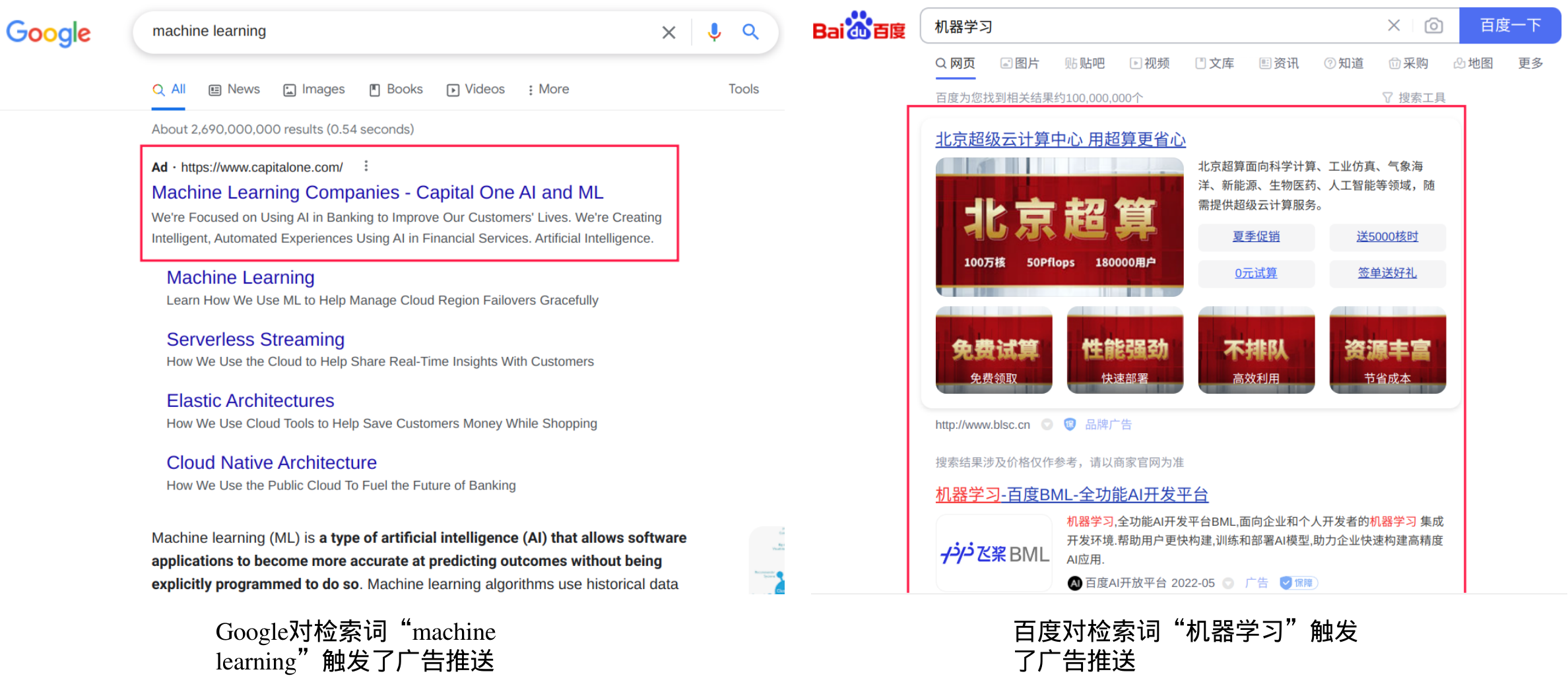
那么技术如何在搜索业务中发挥作用了,或者说得“互联网化”一点,如何赋能搜索业务呢?在此之前我们要明白,就互联网而言,大部分情况下技术本身并不盈利,也就是说技术本身并不能直接作为商业交换以获得利润,但它能更高效,更好地帮助业务运营下去,从而间接获得经济效益,因此也就被称为技术赋能业务,技术是用来给业务赋予某些能力的。就笔者目前的认知来看,觉得有以下几点技术赋能业务的场景:
- 更好的自然排序结果:搜索系统的搜索满足性是吸引新用户,留存旧用户的主要因素,想必没有用户希望使用的搜索引擎排出的结果都是不满住自己搜索需求的。之所以用“满足性”而不是“相关性”,那是因为在保证搜索结果相关性的同时,还需要保证结果的质量,权威,时效等,这一点在[3]已经谈过就不累述了。
- 搜索速度体验:想必大家都不希望搜索一个结果需要好几分钟才能返回,即便这个搜索结果再怎么满足,大部分用户也会因为响应速度问题而投向其他竞品,因此需要一定程度上保证搜索响应速度。
- 更低的机器资源消耗:在保证搜索结果的满足性与响应速度的同时,需要尽可能地减少机器资源消耗,比如储存,CPU或者其他异构计算资源(GPU,TPU等),内存消耗,带宽等,这样才能控制成本从而提高净利润。
- 规避政策风险:全世界各地的政策各有不同,每个国家或地区有着各自敏感而不容触犯的内容,作为立足于某个国家的商业搜索引擎,对于某些违法违规的敏感内容应该予以过滤,即便这个内容满足用户的需求,否则该业务就可能因触犯法律而面临风险。举个例子就是如果用户搜索某些爆炸物的详细制作方法和原材料获取方式,或者该用户搜索关于反社会反人类相关的内容,那么搜索引擎应该对内容池里面的内容有所感知,并且予以过滤,这类型的搜索自然是无法得到满足的。再举个例子就是色情内容,google对于色情内容没那么敏感,但是对于未成年色情内容却相当敏感,而国内的政策更为保守,因此百度对于普通色情内容也是予以屏蔽的。一般来说,政策风险包括:色情敏感,政治敏感两大类,而后者内涵更为深刻,却无法在这里展开。显然,一个业务想要安全长久地运营下去就必须得解决政策风险。
以上的四点都可以通过技术手段进行解决(或者说赋能),而第二第三点更多的体现在搜索架构上的优化,第一第四点更多是搜索算法/策略的优化,鉴于笔者没有太多架构经验,因此只以第一第四点进行举例。
更好的排序结果
信息是信息时代的金矿,而搜索系统就是挖掘信息黄金必不可少的利器,一个理想的搜索系统就像是一个圣杯,一个“万能的许愿机”,可以回答用户的所有问题。然而系统无法生产所有问题的答案,因此最好的解决方法就是用用户生产的内容去回答其他用户的问题。搜索总的来说是从海量的数据池中召回相关资源,然后在根据满足程度进行排序,并将排序最前的若干个结果返回给用户。在这个过程中,“满足”不仅仅意味着内容与问题“相关”,而且要求内容是优质的,权威的,有些问题具有明显的时效性,比如天气预报,股票信息,时政政策,时事热点等,还要求内容的时效性。这些都是业务问题,为了解决这些业务问题需要引入特定的技术。
有诸多技术为了解决相关性问题而被提出,比如传统的TF-IDF,BM25可用于衡量文档与Query的相似程度。如今的技术主流更倾向于引入更复杂的机器学习模型去衡量搜索Query和文档的相关性,此处的相关性大多数情况下是文本相关性,比如衡量Query与Title的相关程度,Query与文档文本的相关程度,在图片搜索或者视频搜索中还可能会有多模态相关性,比如Query与图片的相关性,Query与视频帧的相关性等等。搜索中的不同阶段对这些输入的应用是不同的,即便是相同的输入(比如Query和Title),其数据构建方式,模型结构都可能随着需要解决的问题的不同,而有着诸多细节上的不同。在对业务有着较好的理解才能对以上技术有着较灵活的运用。在深度学习已经成为常规技术的今天,深度模型已经在搜索场景有了很广泛的落地实践,与此相关的文献可参考[4-6]。相关性建模技术为搜索引擎保驾护航,是一个搜索引擎最为关键的技术之一。
质量性是在保证搜索结果相关的前提下,尽可能保证搜索结果的高质,比如搜索一个综艺节目,或者科普解说,大多数情况下我们当然希望其高清,无马赛克,声音大小合适,画面亮度合适等等,最好还有中文字幕以减少用户的消费成本。这些都属于搜索的质量性问题,以视频搜索为例,通常需要引入视频理解技术为视频提供各种算子,比如识别视频是否有大规模黑边,马赛克,清晰度如何。考虑到有些时候高质量视频存在一些视频制作风格的倾向,有些视频制作风格就是比较高质量(或者是格调更高),但是“视频风格”这种概念很难用单一算子组合进行判断,因此有些更高阶的系统还会引入语义算子以整体提高搜索的质量性。视频的质量定义除了一些通用的定义外(比如黑边,马赛克,清晰度一般是较为普遍认可的),还有些质量定义(比如恶意推广,引流等)是属于产品定义的,不同的业务上对其定义不同。这些视频理解技术都为提高视频搜索质量性赋能,减少了用户的消费成本,提高用户体验。
权威性笔者接触的少,那么就以笔者浅薄的认识谈一下。我们对某件事抱有疑问,因而去搜索一个问题的答案,当然希望返回的结果是可靠的,是权威人士的回答,在某些领域更是如此,比如医疗,法律,科技等领域,我们期望得到专业医生,律师和工程师的回答,这种时候我们需要判断搜索Query与内容生产者的权威匹配程度。再比如我们去搜索一个时事热点,我们希望返回的内容是有官方背书的权威内容,而不是自媒体营销号吸引眼球的“fake new”,这种时候我们需要判断搜索Query与站点的权威匹配程度。为了实现这些业务需求,就需要权威性建模站点,用户,对Query进行需求分析等技术赋能。时效性作者接触的更少了,因此就不谈了。
在上层排序阶段,我们需要对更为抽象的需求进行建模。作为商业化搜索引擎我们不能止步于工具,肯定要实现商业诉求:盈利,而盈利手段大多数是广告推广,那么我们希望用户尽可能停留在自己生态下的产品进行消费,以实现商业目的。这种情况下我们不仅得结合相关性,质量性,权威性时效性等基础性质,还得考虑用户行为特征,比如用户会不会点击这个文档呢(CTR预估),用户停留在这个文档的时长会是多少呢(完播率预估)等等,根据不同的业务类型,可能还会去预测用户点赞,投币,收藏等其他维度行为的概率,从而实现其他业务述求。
除了这些之外,还有诸多技术直接或者间接给以上业务方向赋能,比如利用模型为图片/视频/文档分类,打标签以提高相关性匹配,NLP技术用于Query扩展,Query分析等,知识图谱技术为结构化搜索提供支持,LTR技术用于提高搜索的排序效果等,视频/图片指纹进行视频图片去重等等。
规避政策风险
一个业务想要长长久久地运营下去,前提是不违背业务所在国家的法律法规,否则就会收到行政打击从而伤害到业务,说人话就是这个业务给用户消费的商品是合法合规的,最好是合乎主流道德的(否则还可能遭到舆论攻击)。最为直接的例子就是中国大陆地区显然对色情,时政,暴力等比较敏感,但是我们很难控制用户生产哪些内容,作为视频/图片生产者的用户,有可能会上传一些不符合当地法律法规的内容,从而产生政策风险,这个时候就需要引入相关技术对这些内容进行识别,进行过滤。通常都会设计政敏,色敏模型对相关的文档进行过滤,对此笔者了解不深也就不多说了。
还有一种风险是文档中的恶意广告,举个例子就是“澳门赌场,荷官发牌”这种,还有就是视频图片中的二维码广告,微信,手机号等等,这些可能会将用户引流到虚假欺诈网址,从而影响到业务的信誉,导致一些政策风险(被投诉,被罚款等)。为了实现这些业务需求,同样需要技术的赋能。
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/123615027, 《工作一年时期的土豆总结——复杂度和困难度》
[2]. https://baike.baidu.com/item/%E4%B8%9A%E5%8A%A1/1176273?fr=aladdin
[3]. https://blog.csdn.net/LoseInVain/article/details/116377189,《从零开始的搜索系统学习笔记》
[4]. Guo, Jiafeng, Yinqiong Cai, Yixing Fan, Fei Sun, Ruqing Zhang, and Xueqi Cheng. "Semantic models for the first-stage retrieval: A comprehensive review." ACM Transactions on Information Systems (TOIS) 40, no. 4 (2022): 1-42.
[5]. Xu, Jun, Xiangnan He, and Hang Li. "Deep learning for matching in search and recommendation." Foundations and Trends® in Information Retrieval 14, no. 2–3 (2020): 102-288.
[6]. Li, Hang, and Jun Xu. "Semantic matching in search." Foundations and Trends in Information retrieval 7, no. 5 (2014): 343-469.