在TensorFlow中自带有queue和TFrecord以用为异步并行加载数据,以提高整体系统的性能,但是有些情况下,并不需要或者不能用TFrecord,这个时候,可以手动写一个简单的并行加载数据的框架,可以大大提高系统的性能。
前言
在TensorFlow中自带有queue和TFrecord以用为异步并行加载数据,以提高整体系统的性能,但是有些情况下,并不需要或者不能用TFrecord,这个时候,可以手动写一个简单的并行加载数据的框架,可以大大提高系统的性能。
如有谬误,请联系指正。转载请注明出处。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
code: https://github.com/FesianXu/Parallel-DataLoader-in-TensorFlow
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

为什么需要并行数据加载
在很多深度学习应用中,特别是涉及到图片甚至是视频的处理的时候,经常需要解码图片和视频格式以将其加载到内存中去,本文以解码avi视频为例子,这个过程通常是很慢的,有时候解码一个批次的视频(如128个视频)甚至会需要3秒钟,相比而言,在GPU比如GTX 1080Ti中对模型进行训练反而不需要那么久,如果采取读一个批次的视频,然后再进行训练这种串行的训练策略,那么整个系统的瓶颈将会受限于整个系统的IO能力和解码能力,倒反而不是网络训练了,这样就有本末倒置之嫌了。解决视频解码慢也可以通过预先将视频解码为图片,然后在训练的过程中读取图片,这会省去解码视频的时间,但是这样大大增大了对硬盘的需求。以前我做过一个实验,6400个avi视频,总大小约为4GB,经过预解码为图片后,体积增加了约10倍!可想而知,如果这个视频量更大,硬盘是很难承受的(比如NTU RGB-D数据集有约50000个RGB高清视频)。于是,这个时候,我们可以考虑并行地加载数据,解码视频。
系统模型
接下来我们的讨论将基于假设:
- 我们的网络训练是在高性能GPU上完成的,视频解码是在CPU上完成的,于是单次数据读取时间大于单次网络训练时间,既是
- 称数据加载为生产者,网络训练为消费者。
串行的数据加载模型

串行数据加载如上图描述,数据加载的工作在CPU上完成,网络训练在GPU上完成,这个时候,很容易观察到在数据加载的时候,GPU是空闲的,而在GPU训练的时候,CPU又是空闲的,因此无论是CPU还是GPU都没有得到充分利用。
并行的数据加载模型
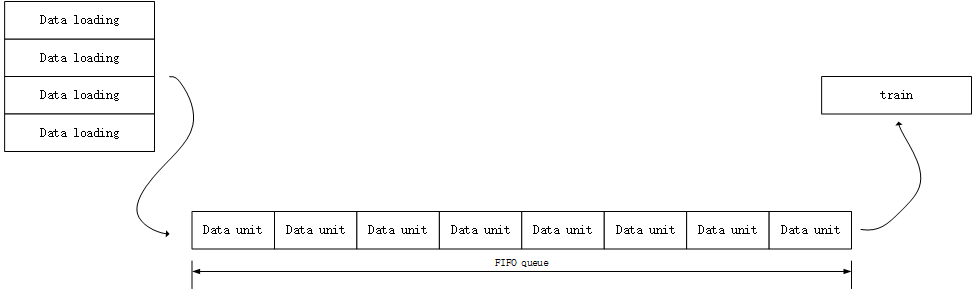
并行数据加载模型如上图所示,在这个模型中,我们首先需要维护一个全局的FIFO队列,这个队列用于保存视频解码过程中的每一个批次,同时需要产生多个DataLoader线程用于解码数据和将数据入队,最后需要一个主线程,用于模型训练同时负责数据出队。当全局队列为空的时候,出队和计算线程将会被阻塞,直到数据加载线程将数据入队后为止;当全局队列为慢的时候,入队和解码线程将会被阻塞,直到计算线程出队使用了数据为止。这样就构成了一个并行数据加载的模型了。
实现
整个过程可以在python中简单实现,我们需要定义一个FIFOqueue类,用于保存数据,如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import queue
class FIFOQueue(object):
__max_len = None
__queue = None
def __init__(self, max_len=5):
if self.__max_len is None:
self.__max_len = max_len
else:
if self.__max_len is not max_len:
raise ValueError('The FIFOQueue has been declared yet and max_len is not same!')
if self.__queue is None:
self.__queue = queue.Queue(maxsize=max_len)
def enqueue(self, item):
'''
put a batch into queue. If the queue is full, then it will be blocked and wait until the queue is not full.
:param item: a batch with the format of (data_batch, data_label)
:return: None
'''
self.__queue.put(item)
def dequeue(self):
'''
pop a batch from queue. If the queue is empty then it will be blocked till the queue is not empty.
:return: the batch with the format of (data_batch, data_label)
'''
item = self.__queue.get()
return item
def max_len(self):
return self.__max_len
def get_len(self):
return self.__queue.qsize()
可以发现只是对queue的简单封装。
在最主要的Train类中,如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43import FIFOqueue as queue
import threading
class Train(object):
_train_global_queue = None
_val_global_queue = None
_test_global_queue = None
_threads = []
def __init__(self,
main_task,
batch_size=32,
train_yield=None,
val_yield=None,
test_yield=None,
max_nthread=10,
max_len=10):
self._train_global_queue = queue.FIFOQueue(max_len=max_len) if train_yield is not None else None
self._val_global_queue = queue.FIFOQueue(max_len=max_len) if val_yield is not None else None
self._test_global_queue = queue.FIFOQueue(max_len=max_len) if test_yield is not None else None
# init the global queue and maintain them
train_threads = [threading.Thread(target=self._data_enqueue,
args=(train_yield, batch_size, task_id, 'train_data_load', self._train_global_queue))
for task_id in range(max_nthread)]
def wrapper_main_task(fn):
while True:
fn(self._train_global_queue.dequeue())
self._threads += train_threads
self._threads += [threading.Thread(target=wrapper_main_task, args=([main_task]))]
def _data_enqueue(self, fn, batch_size, task_id, task_type, queue_h):
print('here begin the data loading with task_id %d with type %s' % (task_id, task_type))
while True:
item = fn()
item['task_id'] = task_id
item['task_type'] = task_type
queue_h.enqueue(item=item)
def start(self):
for each_t in self._threads:
each_t.start()
我们实现了刚才说是的并行加载的过程,其中需要注意几点:
_data_enqueue是用于将数据入队列的,其中fn为数据生成器,需要用户自行重写传入。wrapper_main_task是用于封装主任务的,并且在使得可以在主任务中出队,利用数据。
具体的使用过程请参考github上的代码,我已经开源到github上了。
实验效果
在符合我们的假设的情况下,我们利用time.sleep对生产者和消费者进行模拟,其中消费者延时0.2秒,生产者延时1秒。(在生产者中还进行了简单的文本读取,作为实际例子。)
可以观察到在单线程的时候其cpu使用率仅为5.3%,在实际print中看到也是数据生成的很慢:

而在开了10个生产者线程之后,cpu使用率变为29.8%,提高了接近6倍。

在开了30个生产者线程之后,cpu使用率变为119.3%提高了20多倍。

当然也不是说开越多生产者越好,这个是与具体的任务有关的,但是只要是符合基本假设,都可以有较大幅度的系统提升。