最近笔者需要基于Efficient Net作为图片编码器进行实验,之前一直没去看原论文,今天抽空去翻了下原论文,简单记下笔记。
前言
最近笔者需要基于Efficient Net作为图片编码器进行实验,之前一直没去看原论文,今天抽空去翻了下原论文,简单记下笔记。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

前人的研究证实了,一种有效提高卷积网络性能的方法是:
- 增大卷积网络的深度,比如经典的ResNet [2]
- 增大卷积网络的宽度,比如Wide Residual Network [3]
- 增大卷积网络输入图片的分辨率,比如[4,5,6]
然而单独提高深度/宽度/分辨率很容易达到性能的饱和,如Fig 1.1所示,EfficientNet考虑如何以一种合适的方式,组合性地同时提高深度+宽度+分辨率。对于一个卷积网络而言,第
可看到最终搜索出来的参数
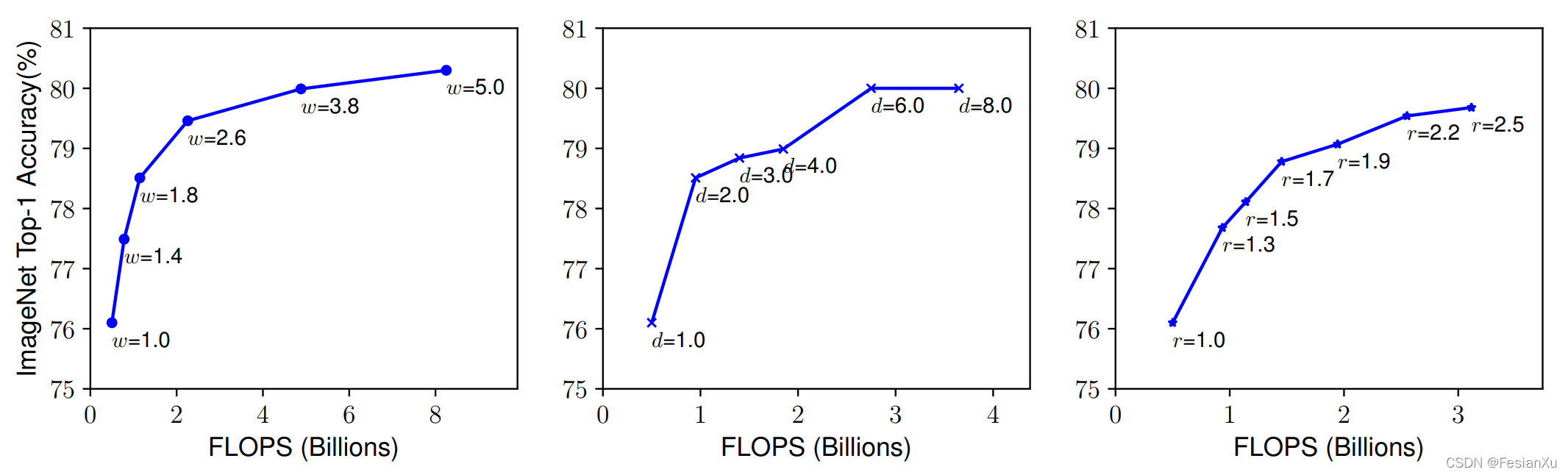
正如(1-4)公式所示,作者通过在小型网络上进行网格搜索,搜索出基本参数
- 首先控制
,然后以MBConv [7]为基础模块,对 进行网格搜索,最后搜索出 ,这个 的网络命名为 EfficientNet B0。 - 固定
,通过选择不同的 从而实现对EfficientNet的尺度增大,从而得到 EfficientNet B0~EfficientNet B7。
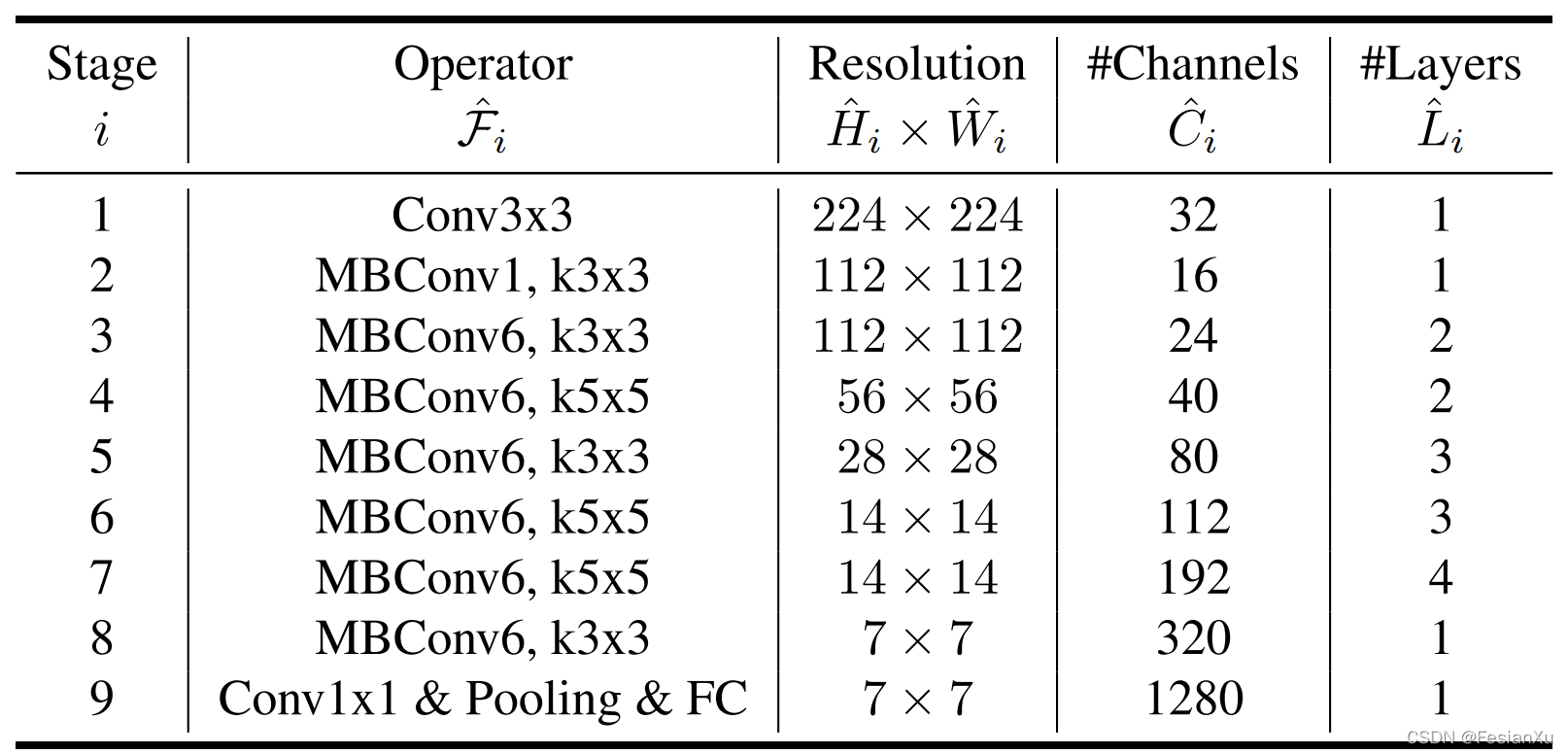
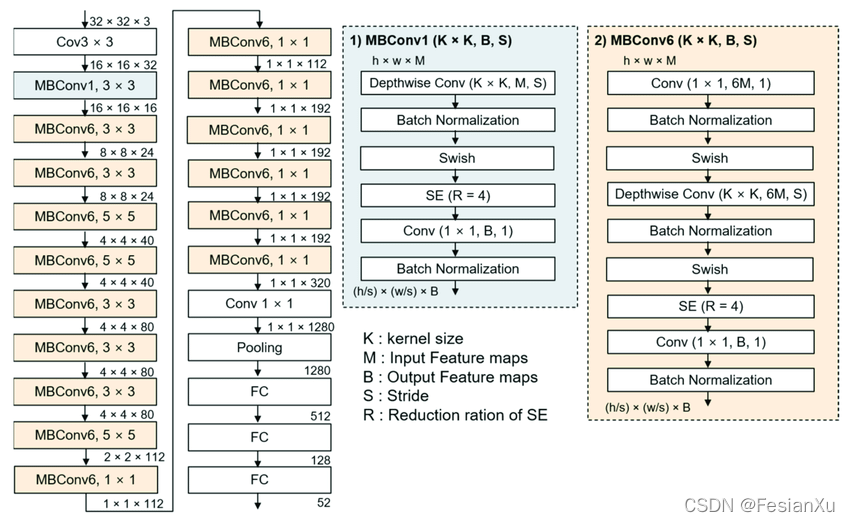
最终得到的EfficientNet B0网络见Fig 1.2所示,其网络结构图可见Fig 1.3,最终各个版本的EfficientNet的
| Model-type | width_coefficient | depth_coefficient | resolution | dropout_rate |
|---|---|---|---|---|
| Efficientnet-b0 | 1.0 | 1.0 | 224 | 0.2 |
| Efficientnet-b1 | 1.0 | 1.1 | 240 | 0.2 |
| Efficientnet-b2 | 1.1 | 1.2 | 260 | 0.3 |
| Efficientnet-b3 | 1.2 | 1.4 | 300 | 0.3 |
| Efficientnet-b4 | 1.4 | 1.8 | 380 | 0.4 |
| Efficientnet-b5 | 1.6 | 2.2 | 456 | 0.4 |
| Efficientnet-b6 | 1.8 | 2.6 | 528 | 0.5 |
| Efficientnet-b7 | 2.0 | 3.1 | 600 | 0.5 |
| Efficientnet-b8 | 2.2 | 3.6 | 672 | 0.5 |
| Efficientnet-l2 | 4.3 | 5.3 | 800 | 0.5 |
Reference
[1]. Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." In International conference on machine learning, pp. 6105-6114. PMLR, 2019.
[2].He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. CVPR, pp. 770–778, 2016.
[3]. Zagoruyko, S. and Komodakis, N. Wide residual networks. BMVC, 2016.
[4]. Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. Rethinking the inception architecture for computer vision. CVPR, pp. 2818–2826, 2016.
[5]. Zoph, B., Vasudevan, V., Shlens, J., and Le, Q. V. Learning transferable architectures for scalable image recognition. CVPR, 2018.
[6]. Huang, Y., Cheng, Y., Chen, D., Lee, H., Ngiam, J., Le, Q. V., and Chen, Z. Gpipe: Efficient training of giant neural networks using pipeline parallelism. arXiv preprint arXiv:1808.07233, 2018.
[7]. Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. CVPR, 2018.
[8]. https://www.researchgate.net/figure/The-structure-of-an-EfficientNetB0-model-with-the-internal-structure-of-MBConv1-and_fig2_351057828
[9]. https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/efficientnet_builder.py