线性复杂度的Transformer...
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

在Transformer [1]中作者提出了用自注意力取代CNN,RNN在序列建模中的作用,并且取得了显著的实验效果,对整个NLP,CV领域有着深远影响。然而自注意力机制的时间复杂度是softmax()内的计算将会是
在论文[2]中,作者证明了密集自注意力是所谓低秩(low-rank)的,意味着可以用更小的矩阵去表征这个Projection单元,将序列长度n映射到低维的k,作者将这种单元称之为Linformer。 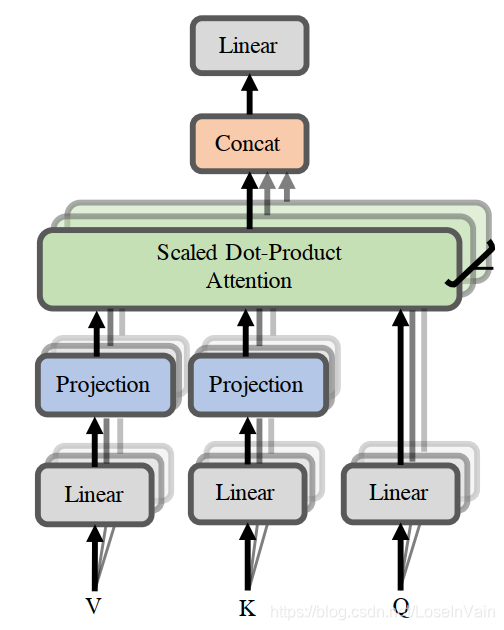
公式也很简单,如式子(2)所示 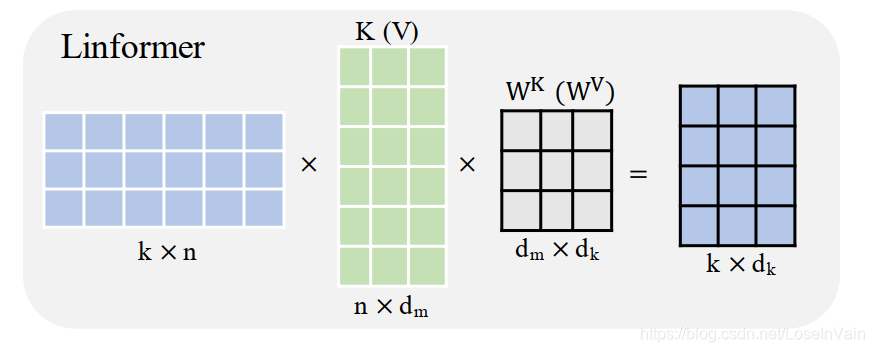 这种做法在序列长度非常长的时候,会有很大的提速效果,如下图实验所示。因此适合于长文本序列。
这种做法在序列长度非常长的时候,会有很大的提速效果,如下图实验所示。因此适合于长文本序列。 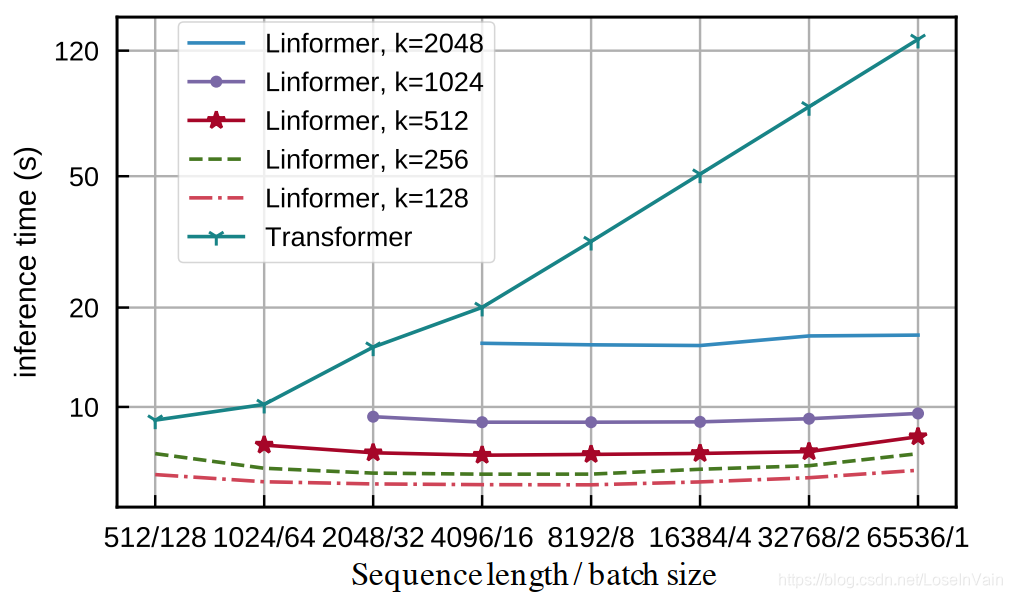 从本质来说,我们可以从式子(2)得到式子(3),我们发现
从本质来说,我们可以从式子(2)得到式子(3),我们发现Linformer。
Reference
[1]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017
[2]. Wang, Sinong, Belinda Li, Madian Khabsa, Han Fang, and Hao Ma. "Linformer: Self-attention with linear complexity." arXiv preprint arXiv:2006.04768 (2020).