之前笔者在[1]中介绍过MoCo v1模型通过解耦batch size和负样本队列大小,从而实现超大负样本队列的对比学习训练方案;在[2]中我们提到了当前对比学习训练中提高负样本数量的一些方法;在[3]中提到了将MoCo扩展到多模态检索中的方案。在本文,我们介绍下MoCo v3,一种尝试在Transformer模型中引入MoCo机制的方法,并且最重要的,介绍其中作者得到的一些训练的小技巧(Trick)。
前言
之前笔者在[1]中介绍过MoCo v1模型通过解耦batch size和负样本队列大小,从而实现超大负样本队列的对比学习训练方案;在[2]中我们提到了当前对比学习训练中提高负样本数量的一些方法;在[3]中提到了将MoCo扩展到多模态检索中的方案。在本文,我们介绍下MoCo v3,一种尝试在Transformer模型中引入MoCo机制的方法,并且最重要的,介绍其中作者得到的一些训练的小技巧(Trick)。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

MoCo的基本原理,包括其历史来龙去脉在前文中[1,2,3]中已经介绍的比较充足了,本文就不再进行赘述。本文主要介绍下MoCo v3 [4]中的一些新发现。MoCo v3中并没有对模型或者MoCo机制进行改动,而是探索基于Transformer的ViT(Visual Transformer)模型[5,6]在MoCo机制下的表现以及一些训练经验。作者发现ViT在采用MoCo机制的训练过程中,很容易出现不稳定的情况,并且这个不稳定的现象受到了学习率,batch size和优化器的影响。如Fig 1.所示,在batch size大于4096的时候已经出现了明显的剧烈抖动,如Table 1.所示,我们发现在bs=2048时候取得了最好的测试性能,继续增大batch size反而有很大的负面影响,这个结论和MoCo v1里面『batch size越大,对比学习效果越好』相悖,如Fig 2.所示。这里面的大幅度训练抖动肯定是导致这个结论相悖的罪魁祸首。这个抖动并不容易发现,因为在bs=4096时候,模型训练最终能收敛到和bs=1024,2048相同的水平,但是泛化效果确实会存在差别。
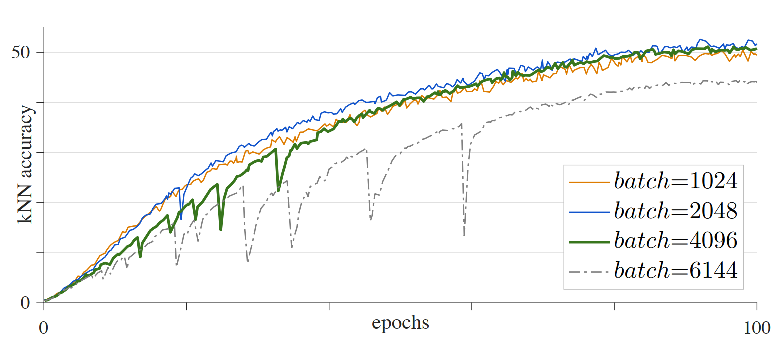
| batch | 1024 | 2048 | 4096 | 6144 |
|---|---|---|---|---|
| linear acc. | 71.5 | 72.6 | 72.2 | 69.7 |
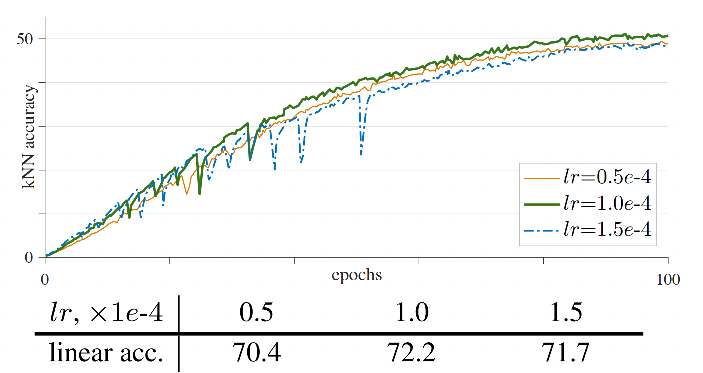
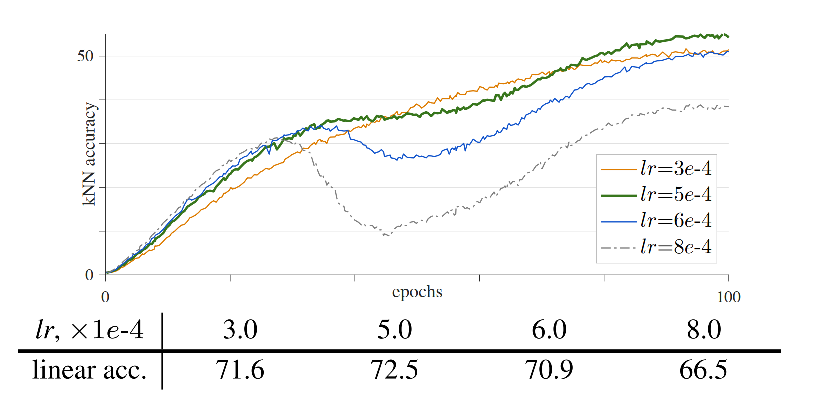
不仅仅是batch size,学习率也会导致ViT训练的不稳定,如Fig 3.所示,我们发现在较大的学习率下训练曲线存在明显的抖动,而最终的训练收敛位置却差别不大。在测试结果上看,则会受到很大的影响。如果将优化器从AdamW更换到LAMB优化器,那么结果也是类似的,如Fig 4.所示,只是可以采用更大的学习率进行训练了。
这种出现训练时的剧烈抖动,很可能是梯度剧变导致的,因此作者对ViT的第一层和最后一层的梯度的无穷范数进行了统计。注意到无穷范数相当于求所有梯度值中绝对值的最大值,也即是如(1)所示。结果如图Fig 5.所示,我们发现的确会存在有梯度的骤变,而且总是第一层先发生,然后经过约数十个step之后传递给了最后一层。因此,导致训练曲线剧烈抖动的原因可能是ViT的Transformer的第一层梯度不稳定导致。 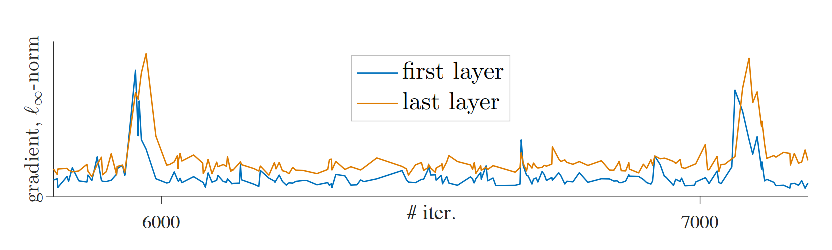
考虑到在ViT中的第一层是将patch映射到visual token,也就是一层FC全连接层,如图Fig6.所示。作者在MoCo v3里面的做法也很直接,直接将ViT的第一层,也即是从Patch到Visual Token的线性映射层随机初始化后固定住,不参与训练。
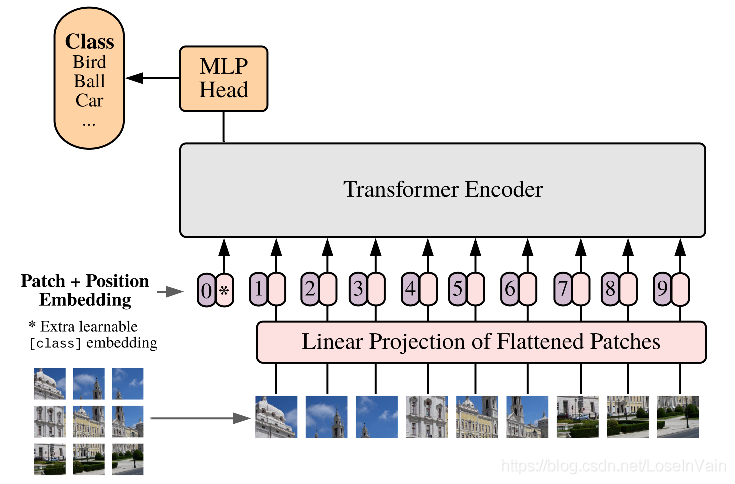
这个做法挺奇怪的,但是实验结果表明在固定住了线性映射层之后,的确ViT的训练稳定多了,如Fig 7.所示,训练曲线的确不再出现诡异的剧烈抖动,最主要的是其测试结果也能随着学习率的提高而增大了,并且同比learned path proj.的情况还更高。
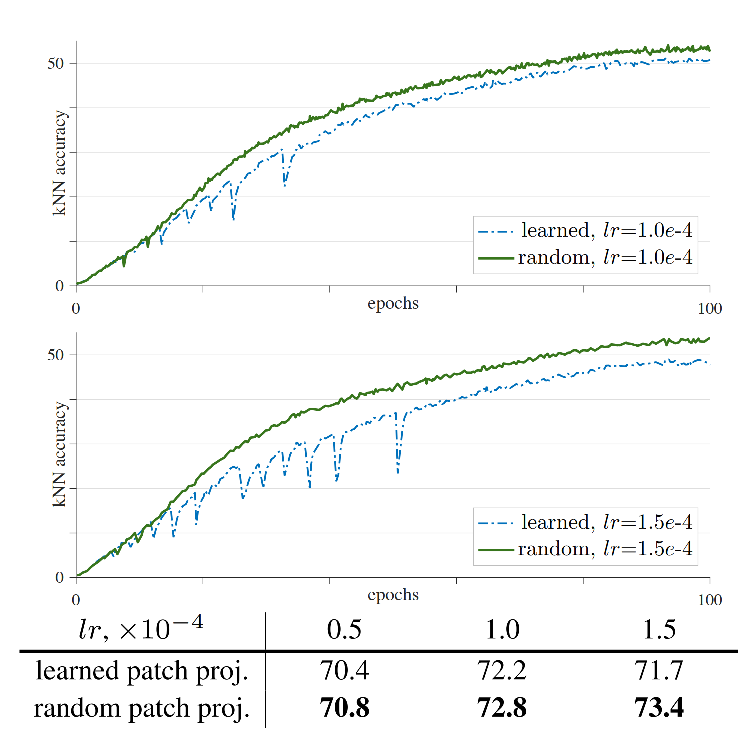
这种现象还是蛮奇怪的,也就是说即便不训练这个patch projection layer,模型的性能也不会打折,而且还会更加稳定。作者给出的解释就是目前这个映射是完备的(complete),甚至是过完备(over-complete)的,以visual token为例子,那么这个映射矩阵就是patch来说,可能在随机的
笔者在大规模的对比学习训练过程中也遇到过类似的训练曲线抖动(虽然没有那么剧烈),但是笔者发现可能是温度系数的剧烈变化导致的,我们以后再继续讨论下温度系数的影响。
Reference
[1]. https://fesian.blog.csdn.net/article/details/119515146
[2]. https://fesian.blog.csdn.net/article/details/120039316
[3]. https://fesian.blog.csdn.net/article/details/120364242
[4]. Chen, Xinlei, Saining Xie, and Kaiming He. "An empirical study of training self-supervised vision transformers." arXiv preprint arXiv:2104.02057 (2021).
[5]. https://blog.csdn.net/LoseInVain/article/details/116031656
[6]. Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).