最近chatGPT、GPT-4火爆了全网,笔者觉得大规模语言模型(Large Language Model, LLM)可能是未来人工智能发展的方向,因此最近也在恶补相关的论文。本次分享一个经典的工作,该工作介绍了LLM中的一种独特模型属性——“能力涌现”,而这个能力可以说是chatGPT、GPT-4等对话模型的基石...
前言
最近chatGPT、GPT-4火爆了全网,笔者觉得大规模语言模型(Large Language Model, LLM)可能是未来人工智能发展的方向,因此最近也在恶补相关的论文。本次分享一个经典的工作,该工作介绍了LLM中的一种独特模型属性——“能力涌现”,而这个能力可以说是chatGPT、GPT-4等对话模型的基石。笔者刚接触该领域不久,如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

在论文[1]中,作者指出在语言模型的模型规模1达到一定程度之后,模型会“涌现”(Emergency)出一些小模型所不具有的能力,这些能力包括但不限于:少样本提示(few-shot prompt)、多步推理能力(Multi-step reasoning)、指令执行(Instruction following)、程序执行(program execution)、模型矫正(model calibration)... 涌现这个概念借用了一篇名为《More is Different》[2] 的文章中提到的“从量变到质变的过程”:
涌现,是系统中的量变积累导致了质变的过程。
这个定义能够帮助我们理解LLM的涌现,但是还不够具体,作者给出了一个更适合于LLM的涌现的定义:
一个能力如果在小模型中不存在,但是在大模型中却存在,这种能力就是一种涌现。
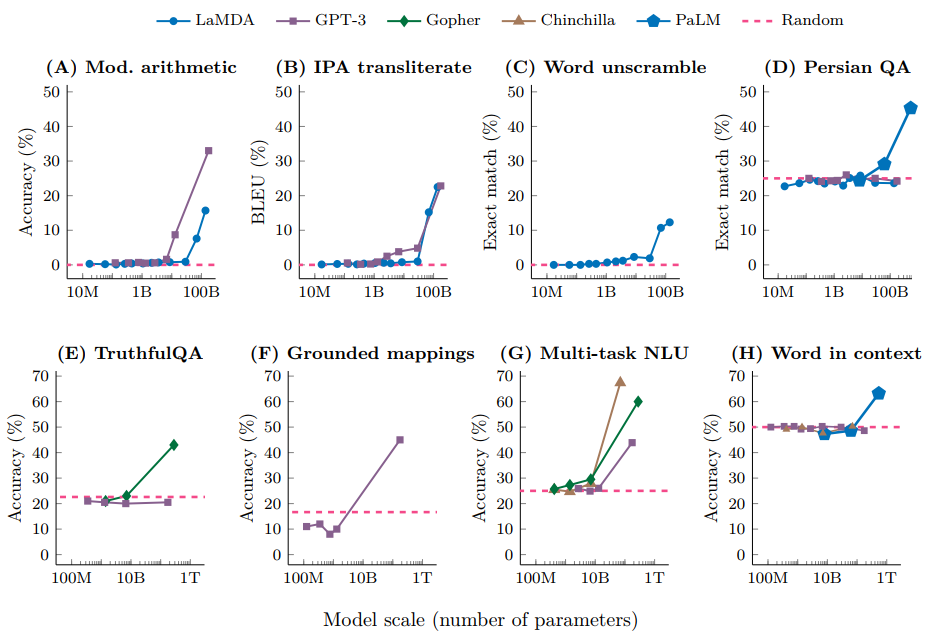
注意到,涌现的能力神奇的一点在于,并不是持续提高小模型的规模,就能观察到该能力持续的提升的2,这种能力只有在模型的规模达到一定程度后,才能观察到。这个涌现的过程,在指标—模型规模的曲线图上就能很容易发现这个模式,如Fig 1.所示,我们发现在不同的测试集中,只有在模型规模达到了一定的程度后,某种能力才会涌现,这个过程并不是连续的,这意味着并不是对小模型进行简单的少量参数增加就能获得涌现能力。
我们在简单介绍了涌现这个神奇的现象之后,有必要了解下few-shot prompt这种方法,因为这种方法在LLM中经常使用。few-shot/one-shot prompt和finetune都是会采用人工标注数据,但是两者是截然不同的方法,如Fig 2.所示,one-shot/few-shot prompt的方法会将标注数据作为LLM的输入的一部分,比如Fig 2. (a)中将已有的人工标注的Review和Sentiment的信息作为输入的提示,并且在这个提示之后拼接真正需要LLM预测的问题“Review: I love this movie”,并且将Sentiment留白,等待LLM的输出,Fig 2. (b)也是类似的过程。Fig 2.给出的例子都是one-shot prompt,而在few-shot prompt中则会拼接更多的人工标注数据,除此之外和one-shot prompt并没有太多的不同,而zero-shot prompt,则不会提供任何人工标注数据作为拼接,直接输入问题期望得到输出。one-shot prompt/few-shot prompt 这个过程也可以称之为In-Context Learning。
这个方法看起来很简单,但是其背后的思想却非常深刻。首先我们考察其和finetune的异同。首先,in-context learning和finetune都是采用人工标注数据的方法,finetune会对模型进行由梯度指引的模型参数更新,而in-context learning这种方法则不需要更新模型参数。这一点在LLM上有着非常大的优势,可想而知,当模型的规模达到了上千亿参数后,即便是模型finetune也需要非常大的代价,而不需要进行模型参数更新的in-context learning此时就显得更为迷人。
in-context learning还有更为有趣的地方,当我们采用pretrain -> finetune这种范式进行下游任务迁移的时候,我们需要对不同的下游任务进行finetune,通用性有限。而如果我们采用pretrain -> prompt的范式进行下游任务的迁移,则只需要设计不同的prompt就可以了,不需要对预训练后的模型进行干涉,通用性大大增强。那么读者可能就会有疑问,简单地通过修改提示词,即便把若干个人工标注样本拼接上去,就能从LLM中获得我们预想中的输出吗?难道LLM真的是万能的?的确,一般的LM在few-shot prompt中只有接近随机的表现,但是一旦模型的规模达到一定程度,非常神奇的,few-shot prompt的能力就涌现出来了。如Fig 1.所示,我们发现一旦语言模型的规模超过10B(百亿参数),few-shot prompt的性能表现将得到极大幅度的跳跃,这种跳跃式的曲线违背了我们之前对于模型规模和性能之间关系的经验。

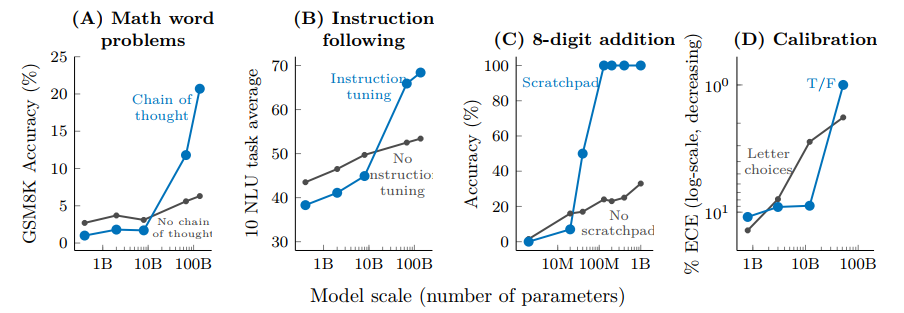
few-shot prompt能力并不是唯一在LLM中涌现出来的能力,如Fig 3.所示,作者还探索了一些其他在LLM能够涌现的能力。
- 多步推理(Multi-step reasoning):多步推理能力能将一个较复杂问题拆解为多个较简单的步骤进行求解,这个能力是通过一种称之为Chain-of-thought prompting(思维链提示)的技术实现的。如Fig 3. (A)所示,只有在模型规模超过了10B之后,采用了CoT prompt技术的方法开始大幅度超越不采用CoT prompt的方法。
- 指令拆解(Instruction Following):指令拆解能力在只提供对某个任务的粗糙描述的时候(比如“将匹萨放进冰箱”),语言模型能对这个任务进行具体的拆解与执行(比如将上面的任务拆解为:首先将匹萨打包,然后打开冰箱,最后将匹萨放进空位,关闭冰箱)。如Fig 3. (B)所示,在模型规模大于10B的时候,LLM的指令拆解能力出现了涌现。
- 程序执行(Program Execution):一些计算型任务需要将整个计算任务拆解为多步的计算过程,比如一个大数加法或者一个程序执行过程,可以拆解为多步简单计算或者程序,如Fig 3. (C)所示,作者呈现了8位数字加法这个任务,在LLM中通过ScratchPad(草稿本,可以理解为将复杂运算拆解为若干简单计算的叠加?),在模型达到100M以后,能够显著超越不采用Scratchpad的方法,因此也是一种能力涌现。
- 模型校准(Model Calibration):语言模型研究中还有一种能力称之为“校准”,指的是判断模型是否能够预测自身知道如何回答某个问题。有点拗口,其实就是需要让模型对自己不知道如何回答的问题进行拒绝,这个能力在chatGPT上是存在的。如Fig 3. (D)所示,在模型规模达到52B以上的时候,这个能力才有可能涌现。
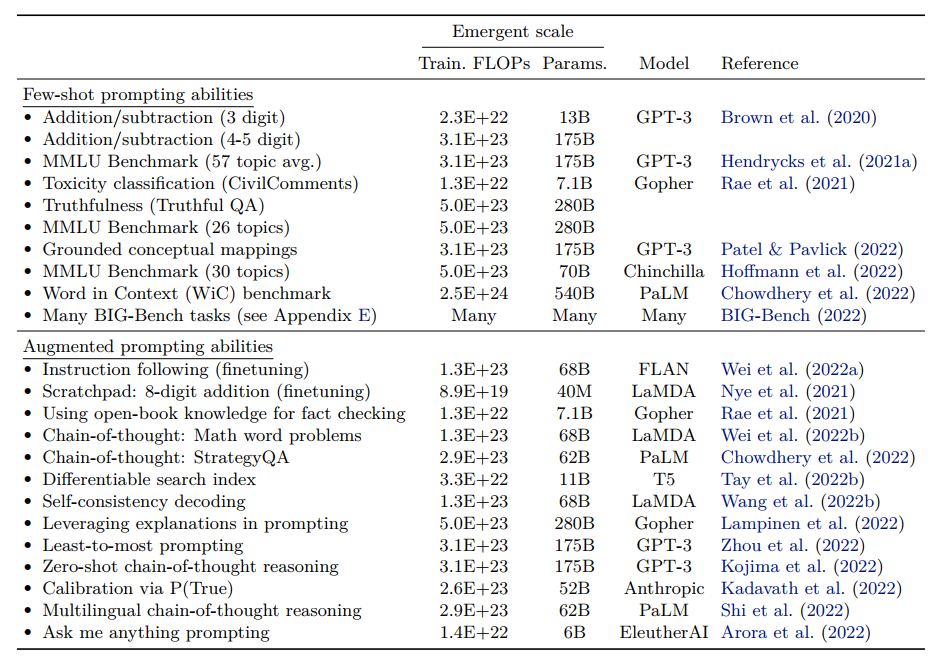
除了以上提到的大模型涌现能力外,文章还列举了一些其他涌现现象以及对应的模型规模,如Fig 4.所示,不难发现,大部分的涌现能力都要求模型规模足够大,起码需要10B以上。
Reference
[1]. Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama et al. "Emergent abilities of large language models." arXiv preprint arXiv:2206.07682 (2022).
[2]. Philip W. Anderson. More is different: Broken symmetry and the nature of the hierarchical structure of science. Science, 177(4047):393–396, 1972. URL http://www.lanais.famaf.unc.edu.ar/cursos/em/Anderson-MoreDifferent-1972.pdf.