全连接为王?...
前言
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号: 
基于局部感知和权值共享的卷积网络CNN和自注意力机制的Transformer系列架构已经在CV和NLP领域得到了广泛的应用。Transformer在诞生之初本是应用在NLP领域,而后续的研究者发现Transformer在视觉和多模态领域也有着惊人的效果[2,3],ViT [3,4]就是将Transformer用在视觉任务上的典型例子。而搞出ViT模型的那伙人现在又在『整活』了,是否可以摒弃卷积和自注意力机制,单纯依靠充足的预训练,利用简单的全连接MLP就可以达到甚至超过以往的结果呢?简单的MLP可以看成是矩阵乘积,具有更好的通用性,因此也在底层优化中更容易实现性能优化。MLP-Mixer [1]这篇文章给出了答案,的确可以这样操作,并且效果也可以匹及目前的基于卷积和自注意力的SOTA结果。
对于一个视觉任务而言,最重要的无非是考虑如何融合: 1)给定空间位置内的信息融合 ;2)不同空间位置之间的信息融合。在卷积中,通过channel-mixing channel和token-mixing channel。Fig 1展示了MLP-Mixer的基本框架。
其中我们发现,这里对图片进行分块的策略和在ViT中保持一致,其中每一块(patch)也称之为token,类比于NLP中的文本token。假如原图片的大小为
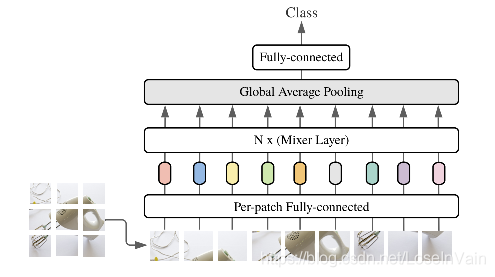
因此关键在于Mixer模块如何设计的问题。Mixer模块如同CNN模块,也是层叠诸多的Mixer层构成的,其中每个Mixer层都是同构的。而在每个Mixer层中则包含有channel-mixing和token-mixing模块,分别负责跨通道和跨token的信息融合。其设计也很简单,如Fig 2所示,考虑到输入的特征表token-mixing对channel-mixing对token-mixing操作。如Fig 2所示,同样也采用了类似于resnet的skip-connections以缓解梯度消失的问题。对应操作的公式如(2)所示。
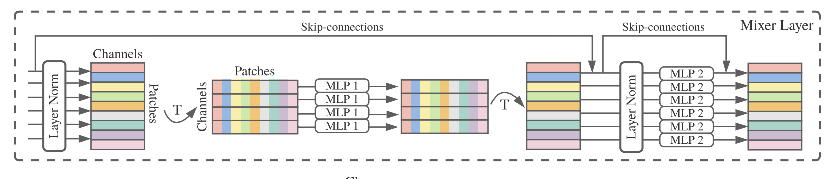
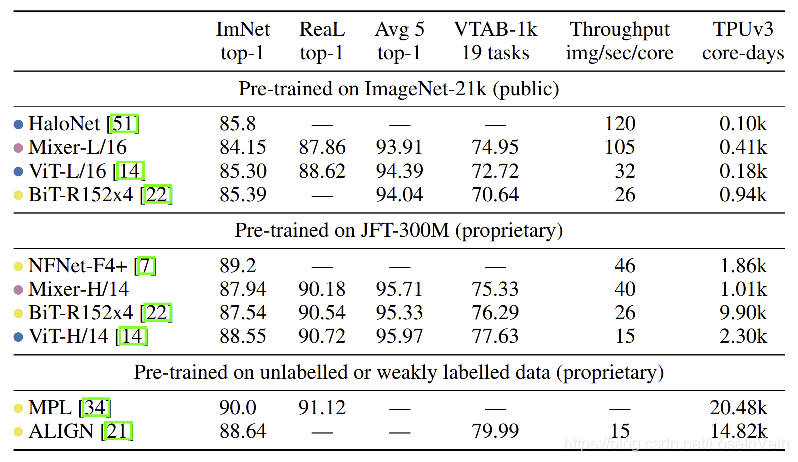
MLP-Mixer并没有采用和ViT一样的位置编码(position embedding),因为token-mixing的MLP对于输入token的顺序是敏感,这意味着不需要位置编码即可实现顺序建模。就实验结果来看,如Table 1所示。我们发现其对比CNN-based和Transformer-based的模型,虽然并不是有领先的优势,但是我们能得出的结论是,即便不引入CNN和Transformer的结构转置先验知识,单纯基于MLP的网络也有潜力达到甚至超过其前辈的表现,而MLP对底层优化更为友好,这就有研究的动力了。
笔者读后感
MLP-Mixer给笔者有一股熟悉的感觉,因为之前在看Shift-GCN [5,7]和Shift算子[6] 的时候,发现也有一些工作在考虑用channel shift操作去替代卷积的部分功能,从而实现效率和性能的优化。而channel shift操作,意外地结合
Reference
[1]. Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., ... & Dosovitskiy, A. (2021). Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601.
[2]. https://fesian.blog.csdn.net/article/details/116275484
[3]. https://fesian.blog.csdn.net/article/details/116031656
[4]. Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[5]. https://fesian.blog.csdn.net/article/details/109563113
[6]. Wu, B., Wan, A., Yue, X., Jin, P., Zhao, S., Golmant, N., … & Keutzer, K. (2018). Shift: A zero flop, zero parameter alternative to spatial convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9127-9135).
[7]. Cheng, K., Zhang, Y., He, X., Chen, W., Cheng, J., & Lu, H. (2020). Skeleton-Based Action Recognition With Shift Graph Convolutional Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 183-192).