Transformer自提出以来在NLP领域取得了诸多突破,而自然而然有工作在考虑如何在图片等视觉媒体上应用Transformer,本文介绍Vision Transformer (ViT)模型,并且作为笔记记录了一些笔者的读后感...
前言
Transformer自提出以来在NLP领域取得了诸多突破,而自然而然有工作在考虑如何在图片等视觉媒体上应用Transformer,本文介绍Vision Transformer (ViT)模型,并且作为笔记记录了一些笔者的读后感。如有谬误请联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号: 
Transformer
涉及到了Transformer的工作,自然首先会简单提一下Transformer。Transformer [2] 开启了一个预训练模型的新时代,其后续工作BERT [5],GPT,ERNIE [4]等都是NLP领域经典的工作,在工业界也得到了广泛应用。作为NLP领域的一个创新之作,Transformer舍弃了常用的RNN,CNN结构,单纯采用自注意力机制 (self-attention)和全连接层(FCN)实现了时序建模。后续的一些工作如BERT等,设计了多种多样的预训练任务,开启了预训练的大时代。我们本章只对Transformer进行简单介绍,具体的代码解析等留后文讲解。
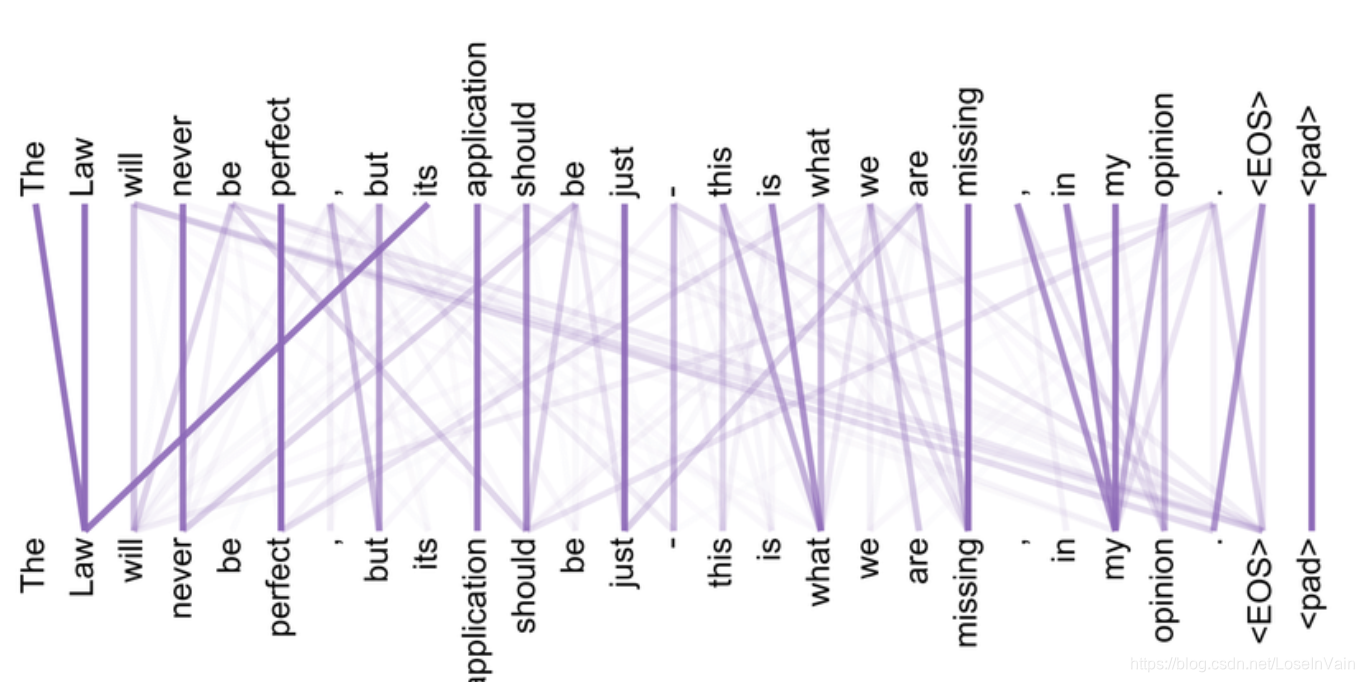
Transformer用自注意力作为组织语句token之间依赖关系的方式,而不是传统的CNN或者LSTM等。如Fig 1.1所示,通过自注意力可以学习到一句话中某个token与另一个token之间的关系强度。
在Transformer中用式子(1.1)进行自注意力的计算,
通过这种形式可以将
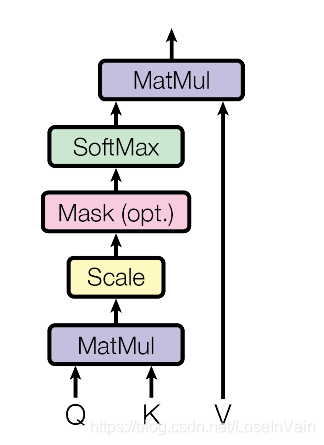
得到了注意力后的序列并不是就完成了,还需要用FC层进行特征变换,在Transformer中将这层叠的FC层称之为Feed Forward Network (FFN),如式子(1.3)所示。
- I eat an apple.
- An apple eat me.
这种类似于词袋(BoW)的结构显然不够合理,不能捕捉到序列的时序信息。为了让模型能够考虑到不同位置的区别,需要加入位置编码,我们记为
Vision Transformer
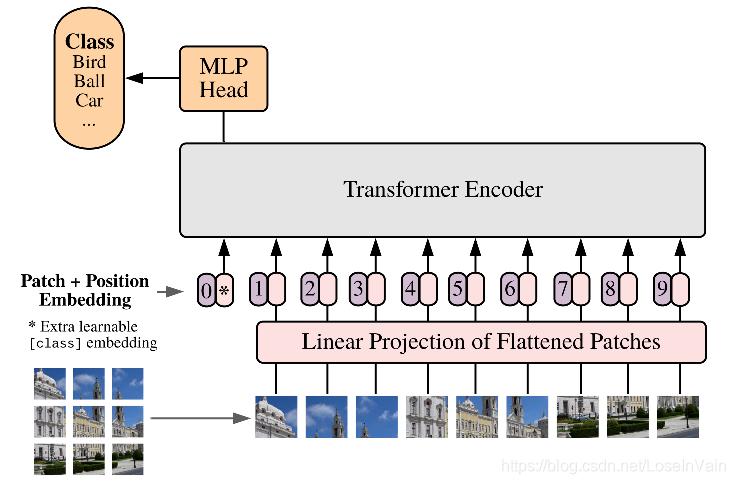
Vision Transformer(ViT)出自论文[1],是一篇考虑将Transformer用在图片任务的工作。ViT的想法很朴素,直接对原图片进行等块分割并且拉直(flatten),然后通过FC层将原图像素直接映射到初级特征,然后直接输入到Transformer中,如Fig 2.1所示。这种思路相当于将每个小块按照顺序,视为文本输入中的token输入到Transformer。
可以用公式进行形式化描述,令原图为
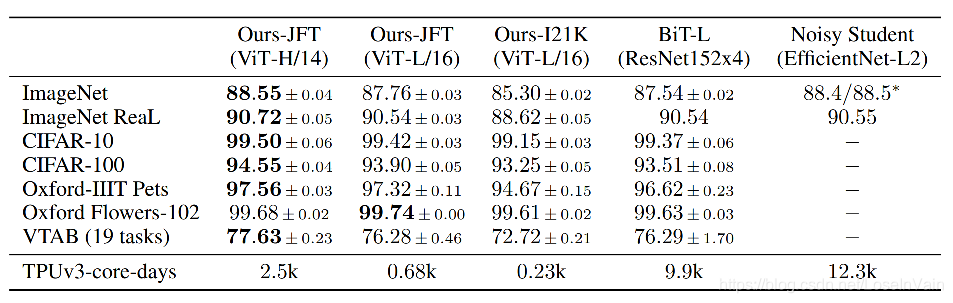
ViT直接用像素经过FC的特征进行输入,本文还对比了混合模型,即是先用若干层CNN对图片进行特征图提取,然后对特征图进行切割,随后输入到Transformer中。除了混合模型,作者同时对比了CNN网络Big Transfer(BiT) [6]的实验结果。如Fig 2.3所示,ViT无论是在
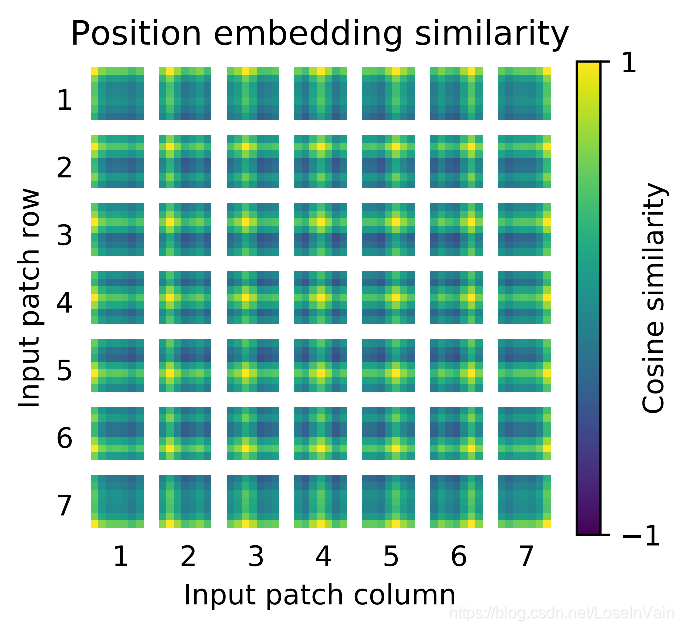
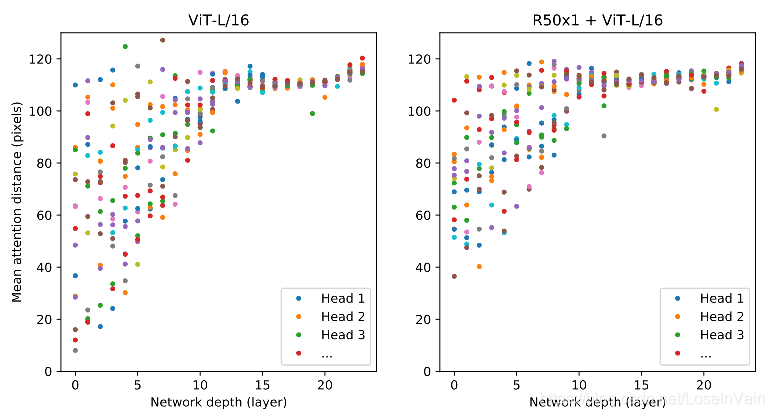
论文还从实验上对比了个有趣的指标,作者仿照感知野的概念,造出了个『attention distance』的概念,衡量当前的注意力范围大小,越大代表当前的注意力感知野越大。如Fig 2.4所示,作者对比了纯ViT和Resnet特征+ViT(也即是混合模型)的不同层的mean attention distance。从对比图中,我们发现在混合模型中,因为引入了CNN的先验知识(比如局部感知,图像的局部性等),使得其注意力感知野从浅层就比较大,范围从
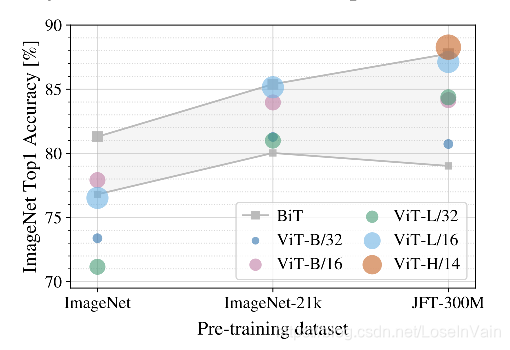
在Fig 2.5实验中,作者让ViT和BiT分别在不同数量级的数据集上进行预训练,然后对比下游分类任务的效果,可以看出,即便ViT模型在小数据集上预训练时候效果不如BiT模型,在大型的JFT-300M数据集上进行预训练后,模型的效果可以赶上甚至超越BiT模型,并且预训练时间少很多。
当然,本文还有很多实验和分析都设计的很精彩,值得读者进一步细细品味。不过对于笔者来说,该文的意义在于,指明了Transformer即便不用CNN的加持,通过足够大的数据集进行预训练(可以是强监督的预训练,也可以是类似于BERT的自监督预训练),也可以达到甚至超过传统CNN网络,并且速度更加快。这意味着Transformer的适用范围远远不只是局限于NLP,在图片,视频等视觉领域也许也可以成为一个通用的基础架构,而基于此的预训练将可以让大数据物尽所用。在多模态领域,Transformer将会有着更为广阔的应用空间,那是我们的后话了。
Reference
[1]. Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[2]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017
[3]. https://fesian.blog.csdn.net/article/details/114958239
[4]. Sun, Yu, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. “Ernie: Enhanced representation through knowledge integration.” arXiv preprint arXiv:1904.09223 (2019).
[5]. Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[6]. Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.