如今的大多数多模态大模型,其视觉输入侧采用的视觉编码器,都是依照CLIP的训练方式,采用大规模对比学习进行训练的。在论文 [1] 中,作者发现CLIP特征具有某些视觉短板,从而导致基于此的MLLM也受到了影响。作者观察到,在一些简单直接(不需要复杂推理)的问题上,MLLM似乎并不能很好解决...
前言
今天读到篇CVPR 24'的论文 [1],讨论了常见的多模态大模型(大多都基于CLIP语义特征,以下简称为MLLM)中的视觉短板问题,笔者感觉挺有意思的就简单笔记下,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

如今的大多数多模态大模型,其视觉输入侧采用的视觉编码器,都是依照CLIP的训练方式,采用大规模对比学习进行训练的。在论文 [1] 中,作者发现CLIP特征具有某些视觉短板,从而导致基于此的MLLM也受到了影响。作者观察到,在一些简单直接(不需要复杂推理)的问题上,MLLM似乎并不能很好解决,如Fig 1所示,一些光从图片中就能很容易判断的问题,如头的朝向、眼睛数量、车门的状态等,强大的mllm反而不能很好地理解,经常会出现“睁眼说瞎话”的情况。这不禁让人好奇,是因为视觉侧没有对图片内容进行完备准确的描述(也就是“眼睛出问题了”)?还是作为底座的大语言模型没有理解好视觉侧提供的信息呢(也就是“大脑出问题了”)? 本文就尝试在探索这个问题。
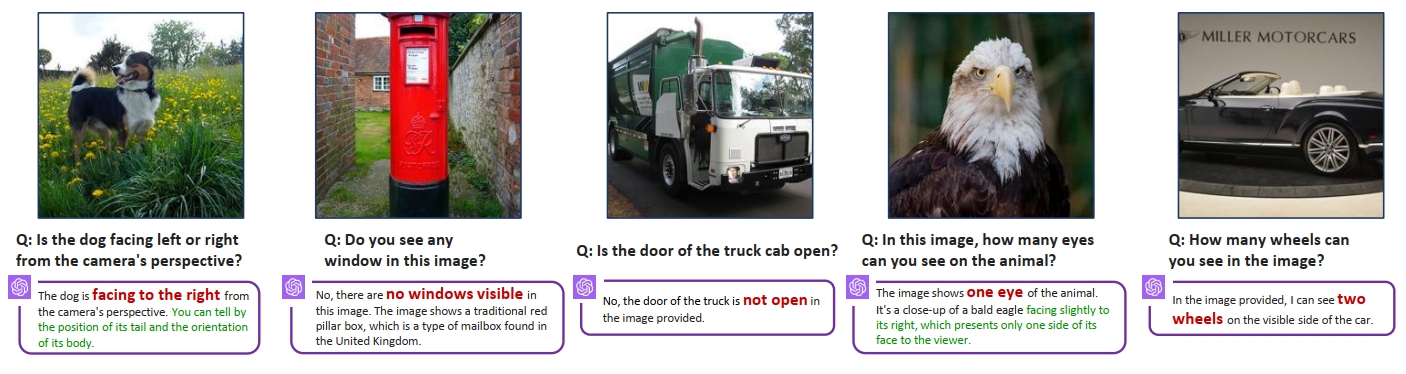
作者认为是CLIP视觉特征的问题,也就是MLLM的“眼睛”有“视觉问题”,导致其“睁眼说瞎话”。考虑到在Fig 1中是一些明显直接的视觉问题,作者假设CLIP在视觉问题上可能存在固有的缺陷,这个缺陷通过扩大模型规模和数据尺度可能都无法弥补。 为了验证这个观点,作者想出了这样一个招儿。
CLIP是弱监督模型,建模了图片的语义信息,而描述图片本身的视觉信息,则可以考虑视觉自监督模型(SSL),比如MAE、MoCo或者DINOv2等,如果一个图片对CLIP-blind(笔者译为,CLIP视盲)的图片对,其采集规则为:

作者首先去评估了MMVP基准的可靠性,考虑先拿市面上可用的MLLM(都是采用的CLIP视觉编码)在这个基准上进行测试。同时,作者请评估者对这300个选择题进行了标注,发现人工的准确率是95.7%,这是一个很高的基线,也说明了MMVP中的视觉问题的确是一些基础的视觉问题。然而,作者发现大部分模型的结果甚至还不如随机猜测(25%),即便是表现最好的Gemini(40.7%),也和人工表现差了一大坨。
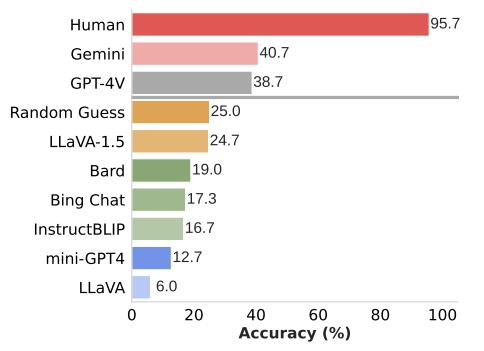
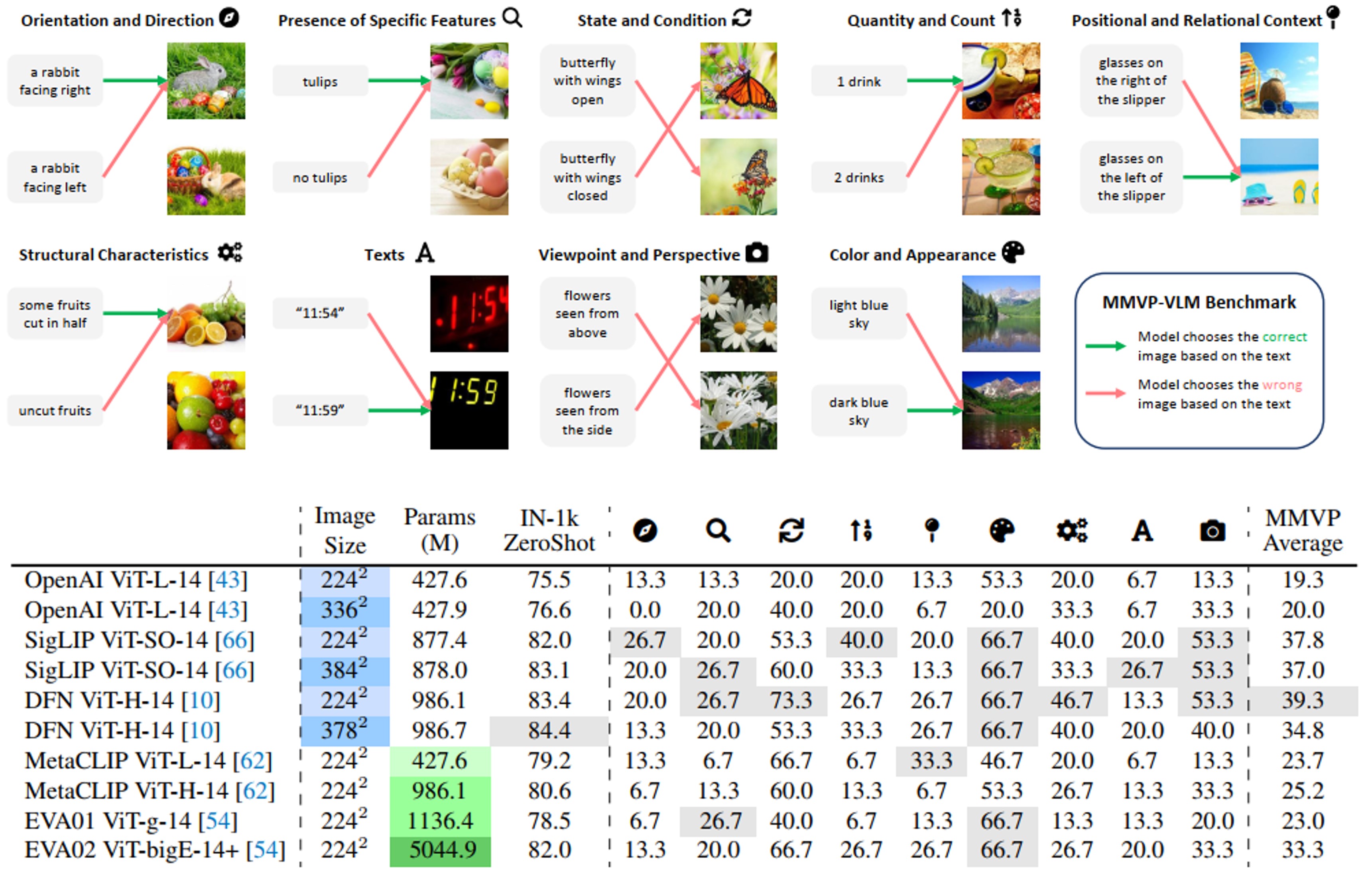
看起来,MLLM确实在这些简单的视觉问题上无能为力,究竟这些视觉问题有什么样本的固有模式能困倒“万能”的大模型呢?作者将MMVP样本交给GPT-4v进行判断其带有的视觉模式,发现了如Fig 4.所示的9种视觉模式。上面的试验说明了MLLM在这些视觉模式上存在固有缺陷,但是这个问题是否是从CLIP带来的呢?这个问题仍未得到解答。
作者采用不同规模的类CLIP模型,将MMVP基准(每个样本都进行了视觉模式的归属)的图片对和其文本进行匹配,如Fig 5所示,只有完全能匹配上的CLIP视盲对样本才认为是有效的一次验证。从结果上看,不难发现在大多数的视觉模式下,增大CLIP的模型规模和图片分辨率都没有帮助,并且ImageNet-1k ZeroShot上的指标和MMVP指标并没有太大相关性。这意味着
- 当前CLIP在这些视觉问题上准确率很低,MMVP平均值最高的都不超过40%。
- 即便增加CLIP的模型规模,数据规模,图片分辨率等,都无法有本质上的提升。
这意味着,CLIP特征在这些视觉问题上是存在固有缺陷的。
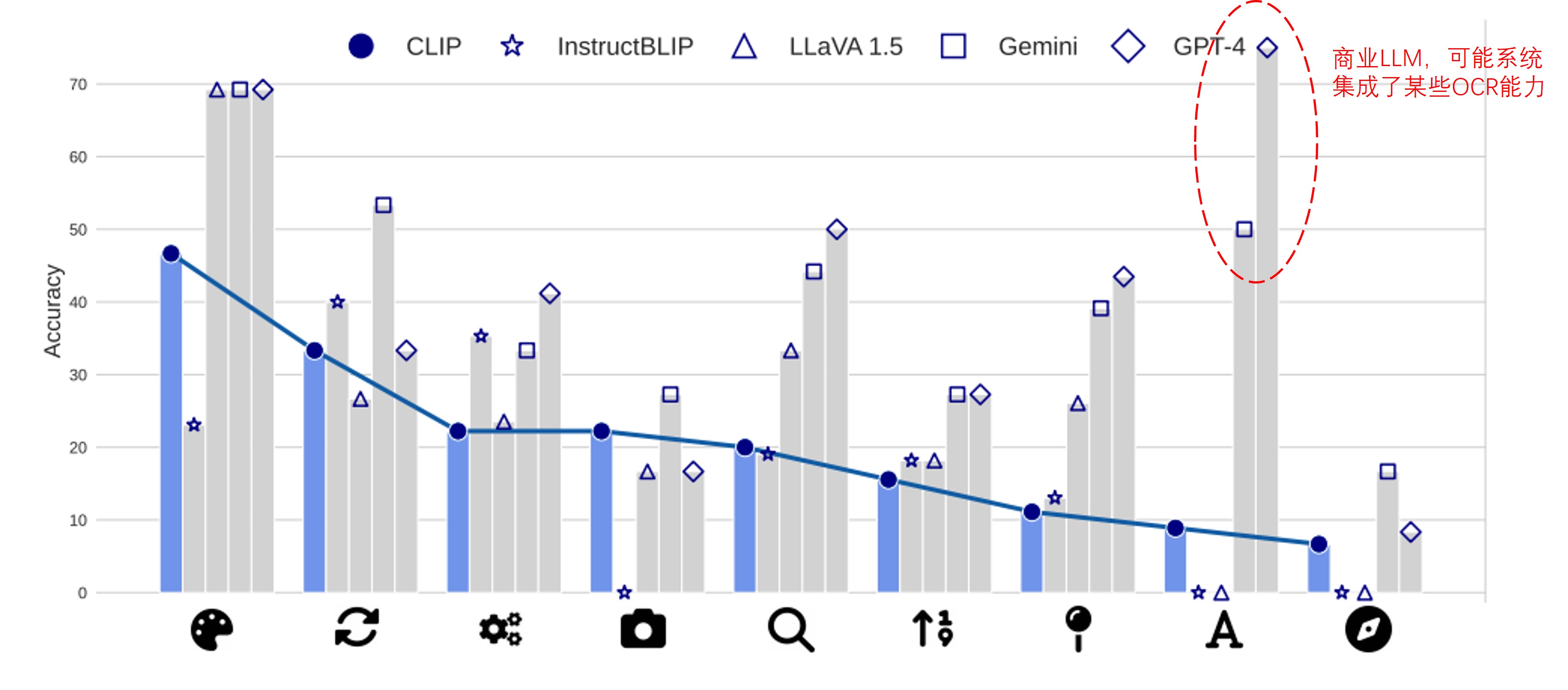
当然了,CLIP存在固有缺陷,并不代表着其结合LLM后就表现一定糟糕(因为LLM可能会弥补CLIP的缺陷),是否能找到这两者的相关性呢?如Fig 6.所示,CLIP在不同视觉模式下的表现曲线,和MLLM的性能曲线变化是相当一致的。据作者统计,LLava和InstructBLIP和CLIP特征的性能表现之间的相关系数超过了0.7,这意味着存在着很大的相关性。当然,在文本问题上,GPT4和Gemini的表现存在异常的高,笔者不负责任地猜测是因为商业LLM,系统继承了某些OCR能力。
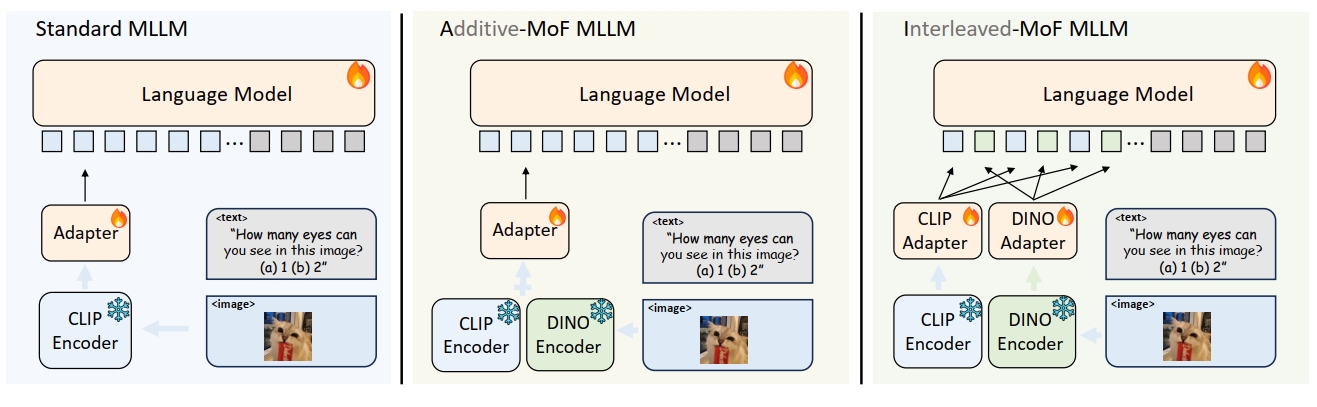
那么怎么解决这个问题呢? 一种合理的想法是,既然CLIP特征存在缺陷,那么我们就在MLLM中引入另外的视觉特征呗,考虑到这些CLIP视盲样本是采用DINOv2特征采集的,那么我们将引入DINOv2特征就好咯,这个想法称之为特征混合(Mixture of Feature,MoF)。也就是说,MLLM的视觉侧特征,应该同时具有语义能力和视觉自身的能力。作者基于这个想法,进行了两种模型设计,如Fig 7所示,分别是加性的特征混合、交织的特征混合。
作者发现加性的特征混合方法,的确能大幅度提升MMVP指标(5.5 -> 18.7, +13.2),但是其指令跟随能力也会极度地下降(81.8 -> 75.8, -6.0),要牺牲指令跟随能力还是不舍得的。作者又继续尝试了基于拼接的方法,不过作者不是将两个特征直接相拼,而是将其中的视觉特征交织地拼接。笔者猜测,是因为CLIP编码器和DINO编码器都是采用的Visual Transformer模型,因此对图片进行了分块,将语义特征和视觉特征相邻拼接在一起,其存在“彼此之间的能力增强”,不过这是笔者脑补的哈哈哈嗝。不管怎么说,这样搞了后,在不牺牲指令跟随能力的情况下(81.8->82.8, +1.0),还能得到MMVP能力的提升哦(5.5 -> 16.7, +10.7)。
笔者看完后呢,还是比较认同这篇论文的结论的。不同的是,笔者之前虽然不是大模型的应用场景,而主要是站在视频搜索业务落地多模态能力过程中的经验去看待这个工作。如博文 [4] 所说的,笔者在规划多模态基础算子能力的时候,就认为CLIP语义特征虽然很强大,但是描述的问题大多是基于语义的,在一些需要考虑视频本身视觉结构问题上(如质量、后验应用),应该基于自监督的方法进行建模。这篇文章算是提供了一个很不错的参考,嘿嘿嘿。
Reference
[1]. Tong, Shengbang, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. "Eyes wide shut? exploring the visual shortcomings of multimodal llms." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9568-9578. 2024.
[2]. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. aka CLIP
[3]. Maxime Oquab, Timothee Darcet, Theo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023 aka DINO v2
[4]. https://fesianxu.github.io/2024/06/30/video-retrieval-multimodal-20240630/, 《万字浅析视频搜索系统中的多模态能力建设》