最近从朋友处得知了DSI这个概念,所谓的可微分检索索引DSI,就是通过语言模型将检索过程中的索引和召回阶段端到端地融合在一起,输入query模型直接输出docid,笔者今日抽空看了下原论文,简单笔记下,希望对各位读者有所帮助...
前言
最近从朋友处得知了DSI这个概念,所谓的可微分检索索引DSI,就是通过语言模型将检索过程中的索引和召回阶段端到端地融合在一起,输入query模型直接输出docid,笔者今日抽空看了下原论文,简单笔记下,希望对各位读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

检索系统一般可以分为索引-召回-排序三大阶段。索引就是给每个文档赋予标识符,记为docid,用于后续召回阶段以此为key进行检索。索引可以分为稀疏索引和稠密索引,其中稀疏索引利用分词结果、词频、词权等等信息构建倒排索引,然后通过项匹配(term match)的方式进行召回。稠密索引则是一种语义索引,将每个doc映射到一个语义向量然后通过ANN召回。在排序阶段,根据更高阶的特征对召回结果进行排序以达成整个检索系统的功能目标和商业目标。
在传统检索中,这三个阶段都是独立的,而在可微分检索索引(Differential Search Index, DSI)这篇工作 [1] 中,作者尝试用语言模型将索引和召回两个阶段结合在一起,即是query -> LM -> docid,然后发现效果还比稀疏索引和稠密索引的基线效果更好,挺有意思吧,让我们看下他们是怎么做的。
从直觉上看,这个过程需要让语言模型(以下简称为LM)建模两个东西:
- 索引过程: 即是
doc -> docid的过程。这个过程,其实是将doc索引内涵在了模型参数中。 - 检索过程,即是
query -> docid的过程。
从训练过程来看,有两种可行的思路:
- 多阶段: 首先用LM端到端训练索引过程(第一阶段),然后再以此热启训练检索过程(第二阶段)。
- 多任务: 索引过程和检索过程同时进行训练,通过平衡两种数据不同的比例去控制模型的能力。如Fig 1所示,其中
v123 -> doc456这个过程就是检索过程,而v456 -> doc456、 v137 -> doc137就是索引过程。作者在实验中发现多任务的效果会更好些,同时也探索了合适的索引和检索数据比例。

我们再看到一些细节的地方。 索引过程中(也就是从doc到docid的过程),需要考虑两个点:第一是doc应该以什么形式去产生docid,第二是应该怎么表示doc。
对于第一个问题,即是doc应该以什么形式去产生docid,我们称之为索引方法(Index Methods):
- 输入到目标(Inputs2Target):直接将
doc_tokens -> docid看成是一个seq2seq问题,这种做法有个隐藏的缺陷,就是难以对doc引入通用的预训练目标(自回归/MLM)。 - 目标到输入(Targets2Inputs):和第一种方案相反,是从
docid -> doc_tokens,从直观上看是一个自回归模型,只是这个模型受到docid的约束,即是p(doc_tokens|docid)。这种做法可以对doc引入基于自回归的预训练目标。 - 双向建模:在一个训练过程中,同时建模Inputs2Target和Targets2Inputs,通过一个前缀令牌去区分具体是哪个方向的任务。
- 文段腐化(Span Corruption):文段腐化这个方法将
docid和doc_tokens拼接在一起,然后随机进行文段掩膜(span mask),并且尝试对掩膜后的文段进行恢复。这种做法,使得能在索引训练过程中引入预训练任务。
对于第二个问题,即是应该怎么去表征一个文档,我们称之为文档表征策略(Document Representation Strategies):
- 直接索引(Direct Index):这种方法将原始文档的令牌(token)进行截断,只保留前
个token,同时保留了token之间的上下文位置关系。(也即是只是进行了截断,不做其他特殊处理)。 - 集合索引(Set Index):一个文档中可能包含有很多重复的文段或者无意义的字词(比如停用词),这个方法在除去停用词后,采用python中的
set()函数去对文档中重复的文段进行去重,去重后的文档就和直接索引一般进行应用。 - 倒排索引(Inverted Index):这种方法将文档分为了很多个片段(chunk),然后随机将一个片段映射到docid(而不是一个文档对应一个docid)。
在检索过程中,由于DSI中的docid是直接输入query后,模型直接解码输出的,因此怎么去表征docid是一个很重要的问题。一种最朴素的想法就是无结构化的原子性docid,也就是给每个文档分配一个随机的唯一整数docid,即便是两个语义上、主题上相似的文档,这两个docid之间也不存在相关性,此所谓之无结构化。原子性,则是模型是一次性就将docid给预测出来的,而不需要进行自回归式的token by token解码。这意味着这种方法需要扩充现有的词表,将每个docid都添加进词表。 最终LM的输出将会被扩展成如式子(1)所示
有一种方法是,把docid看成是一个字符串,因此可以用自回归解码的方式去进行docid的解码,因此整个词表也不需要随着doc数量的扩充而扩充了,也可以解决在超大词表下softmax计算的问题。这种看起来比较离谱的方式(因为此时的docid没有语义信息),作者表示居然效果还不错,挺有意思的。
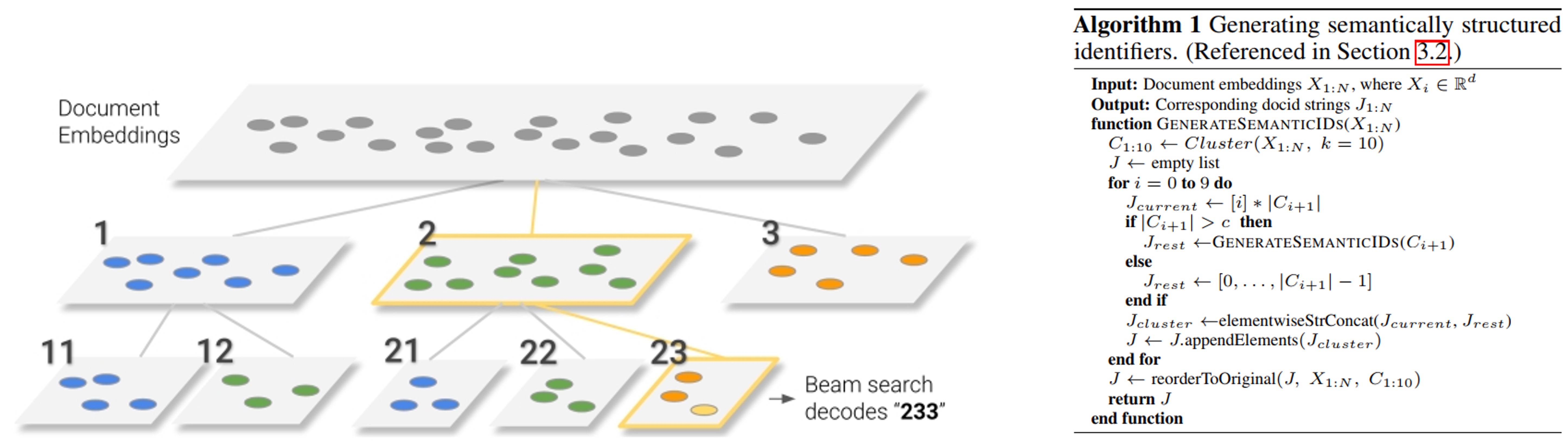
还有一种方法是去构建具有语义信息的docid,我们希望的是相似的doc之前具有相似的docid前缀,因此可以考虑层次聚类的方式。
- 首先对库里所有doc进行语义向量计算(可以采用BERT计算);
- 然后对这些doc进行聚类,聚成10个聚类簇,如果每个聚类簇中样本量大于一个超参数
,那么继续对这个聚类簇进行聚类(聚类簇数量仍然是10),一直到叶子聚类簇数量小于 为止。 由此可以给每个doc进行编码,如Fig 2所示,相似的doc由于聚类簇会更加接近,其docid前缀也就会更加接近。
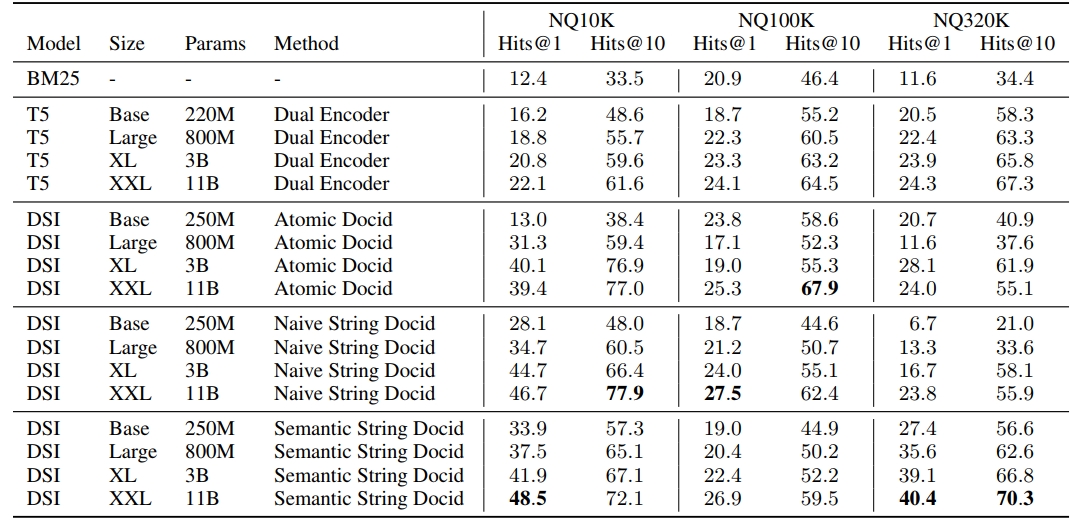
作者用T5作为底座模型,模型参数分布尝试了Base (0.2B), Large (0.8B), XL (3B) 和 XXL (11B) ,试验都是采用直接索引和Inputs2Targets的方式进行试验的(作者在前期的消融试验里面已经对比过了效果)。 试验是在Natural Questions(NQ)数据集中进行的,如Fig 3实验结果所示,首先能看到随着模型尺寸的提升,效果都是呈现提升趋势的。然后能看到基于DSI的方法,效果都大幅度超过了基于BM25的稀疏索引方法,也超过了双塔召回的结果。我们看到,在较大数据量的NQ 320K设置下, 语义docid(Semantic string docid)具有最好的的效果,而实际的检索场景都是海量数据的,从直觉和试验数据上,笔者觉得语义docid都是更为合理的方式。此外,作者还做了zero-shot效果试验,检索数据和索引数据在多任务下的数据配比探索,尺度效应(scale law)的验证等,具体细节就不在这里展开了,有兴趣的读者可以自行翻阅论文。
这篇文章是22年10月份的,从时间上看应该是和chatGPT同期的工作,笔者感觉这篇论文和chatGPT应该是异曲同工之妙吧,或者是某种程度上“退化”版本的chatGPT?首先DSI将文章索引都内涵到模型的内部参数中,而不是像传统方法一样维护一个巨大的明文索引库,这就和chatGPT通过大规模自回归预训练将海量知识内涵在模型参数中一致。不过似乎chatGPT会做的更加彻底,把索引内涵到模型参数后,将召回和排序都融合在一起了,用户直接通过prompt工程就能从chatGPT中以某种形式“搜索”出答案。而DSI还只是将索引和召回融合在一起,后续的排序部分还是采用排序模型进行的,这有一个好处就是方便工业界落地,并且可解释性、可控制性也更强,方便融入一些商业目标,笔者认为可能会更适合于公司落地,可能能给当前的RAG提供一些思路(可能已经有类似的方法了,笔者没有去调研) 。不过DSI也明显会遇到一些挑战,比如新增文档可能就需要增量式地重训底座模型,以将新增doc的索引融入到底座模型中(这个应该是LLM的共有问题了)。同时,层次聚类的方式去产出语义docid,新增doc应该怎么处理也是一个值得考虑的问题。当然,以生成式模型的方式去搞召回,速度问题也是非常需要考虑的问题。
Reference
[1]. Tay, Yi, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin et al. "Transformer memory as a differentiable search index." Advances in Neural Information Processing Systems 35 (2022): 21831-21843. aka DSI