最近笔者在回顾&笔记一些老论文,准备整理下之前看的一篇论文LexLIP,其很适合在真实的图片搜索业务场景中落地,希望笔记能给读者带来启发。
前言
最近笔者在回顾&笔记一些老论文,准备整理下之前看的一篇论文LexLIP,其很适合在真实的图片搜索业务场景中落地,希望笔记能给读者带来启发。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

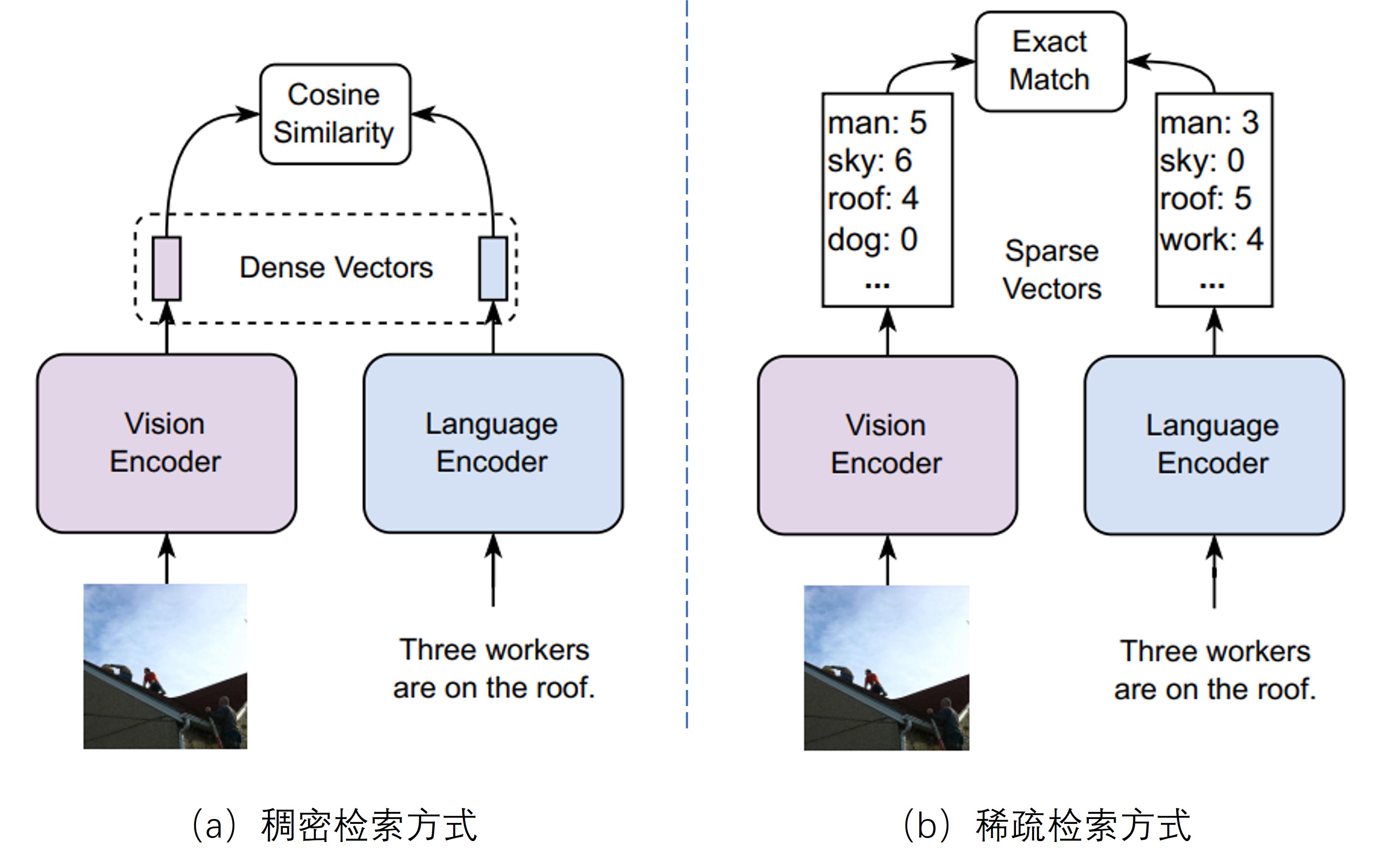
图片搜索场景,指的是输入文本去检索相关的图片,是一种典型的跨模态检索场景。在图片搜索中,强烈依赖于图片的视觉信息,多模态能力是必要的,典型的第一阶段检索方式(也即是召回阶段)采用的是稠密检索,如Fig 1所示,目前主流的管道是:
- 以图文匹配为目标,采用基于CLIP等大规模对比学习的方式训练图片和文本塔
- 对索引库中的所有待索引图片进行图片稠密特征刷取,在线上部署文本塔以提取query的稠密特征
- 将文本塔和图片塔的稠密向量进行度量计算(如余弦相似度),得到图文之间的相似度
当然,在真实的业务场景中,还会采用ANN(近似最近邻)等技术对大规模的图文相似度计算进行速度和效果的折中。我们能从以上的描述中,感受到稠密检索的几个缺陷:
- 储存代价高:以一个512维度的特征向量,如果是
float32形式储存,那么10亿左右的图片量级就需要接近2T的储存。 - 检索速度慢:对2个维度为
的稠密向量进行相似度计算需要 次浮点乘法运算和加法运算。 - 可解释性差:采用稠密检索的方式,无法提供足够好的可解释性,去解释为何一对图文之间为何打分高/低,这对于业务场景中需要定期解case的需求而言,是一个不利因素。
这让我们想到为何不采用稀疏的检索方式呢,比如在传统的文本检索任务中,会采用基于BM25的方式给文档和query进行词频统计,然后基于词的字面精准匹配去计算相似度打分,这种方式储存代价低、检索速度快且具有更好的可解释性。 然而,图片搜索中的图片无法通过传统的方法将其进行“词频统计”,而LexLIP(Lexicon-Bottlenecked Language Image Pre-Training, 基于词典瓶颈的图文预训练) [1] 这篇文章就是考虑将图片也像文本一样进行“词频统计”,从而使得图片搜索也可以采用稀疏检索,如Fig 2所示。 让我们进一步深究下这篇文章是怎么做的。
首先我们反过来,先看到当LexLIP整个模型训练完后,是如何使用的。 如Fig 2所示,训练好的视觉编码器会对索引库中的所有图片进行特征计算(俗称刷库),然后每一个图片中的关键实体元素,将会被分解到文本词表中,并且词会有对应的词权(weight),笔者将其称之为视觉词(visual word)。待刷完库后,可以构建倒排索引链表,此时可以知道词表中的每个词都在哪些图片中出现过,并且词权是多少。用户在使用时候,对于输入的query文本也进行词权计算,用
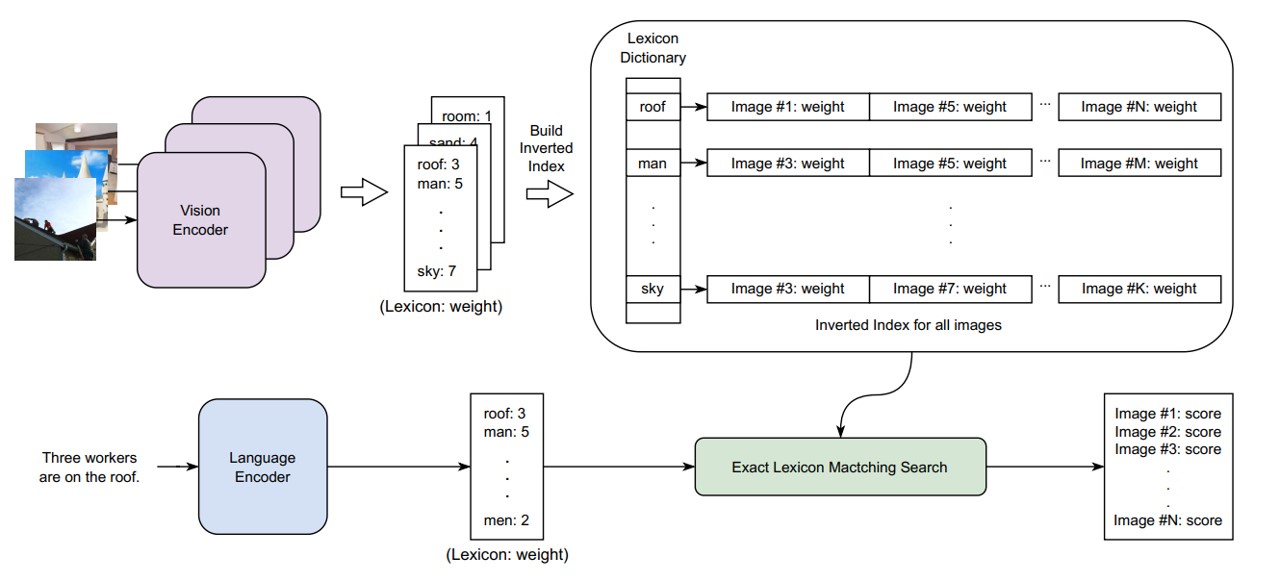
这个就是LexLIP的检索过程,那么这个模型是怎么训练的呢? 从直观上看,这个模型应该具有几大块:
- 文本编码器和词权计算器(lexicon-bottleneck): 用于对文本侧进行稠密编码,然后通过词权计算器对文本稠密特征处理,得到词权。
- 视觉编码器和视觉词权计算器:用于对图片进行稠密编码,然后通过视觉词权计算器对视觉稠密特征处理,得到视觉词权。
因此,这个模型的训练需要考虑文本、图片双塔的编码器如何训练,也需要考虑各自的词权计算模块怎么训练。如Fig 3.所示,让我们看下这个模型训练是怎么做的。在图片侧的编码器采用的是ViT,需要对图片进行切块,切块后结果记为
Text MLM: 文本的MLM预训练任务,即是将输入文本
进行一定概率的掩膜2 得到 ,然后通过上下文去预测被掩膜的token,如公式(4)所示。这个目标主要是建模文本编码器本身的能力。 LexMLM: 这个损失用于建模词权计算的能力,也即是原文中提到的"lexicon-bottleneck",其中的lexicon表示词典,bottleneck表示瓶颈,也即是通过这个模块,能将稠密向量的关键信息“封锁”到稀疏的词典表示中,就像是瓶颈一样,算是很形象了。这块的建模比较复杂, 首先需要进行规范化,如公式(5)所示,注意到文本侧的输入是掩膜后的文本
。
由于这是一个跨模态模型,要求词权也具有跨模态建模的能力,在传统的多模态融合模型UNITER(见博文 [2] )中,是采用跨模态的MLM去建模不同模态之间的语义关联,在本工作中也是采取了类似的方法,考虑到LexLIP的底座是一个双塔模型,因此也引入了一个弱化的Transformer(被称之为Weakened Language Decoder)作为跨模态关联。
在模型学习好了的情况下,现在的
不过我们需要考虑一下细节,
- BaCO(In-Batch lexicon-Contrastive Loss):采用对比损失去保证进行过视觉稠密特征稀疏化后的
同样具有良好的语义匹配能力,如公式(8)所示,此处的 是一个控制稀疏度的正则项,在SPLADE [3] 这篇文章中引入的,笔者感觉不是很关键,暂时先不关注,那么 。
就笔者感知而言,其实不妨将LexMLM看成是ALBEF [4] 中的MLM loss,而BaCO则是ALBEF中的ITC loss,只不过为了适配稀疏特征的特点做了一些优化而已,这样理解这个论文就会容易一些。最终的损失为:
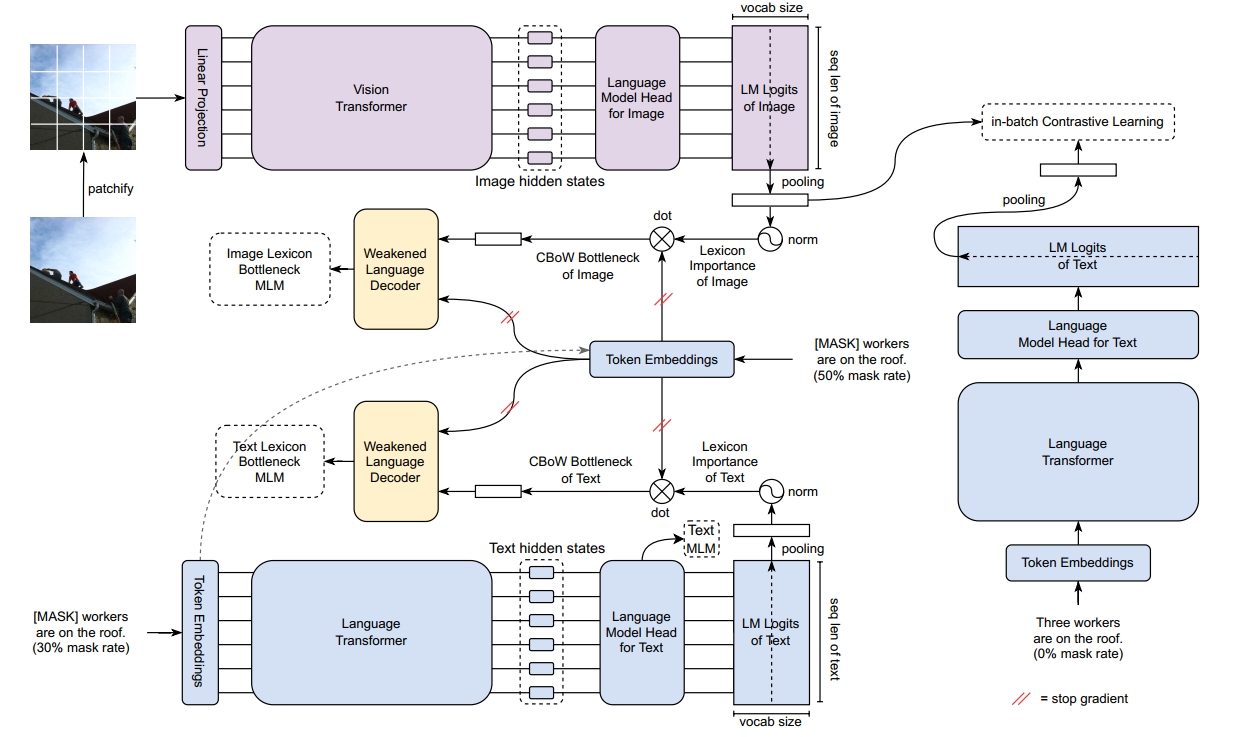
以上模型就训练好了,然而为了实现梯度反传,以上提到的相似度计算都是在实数域进行的,比如
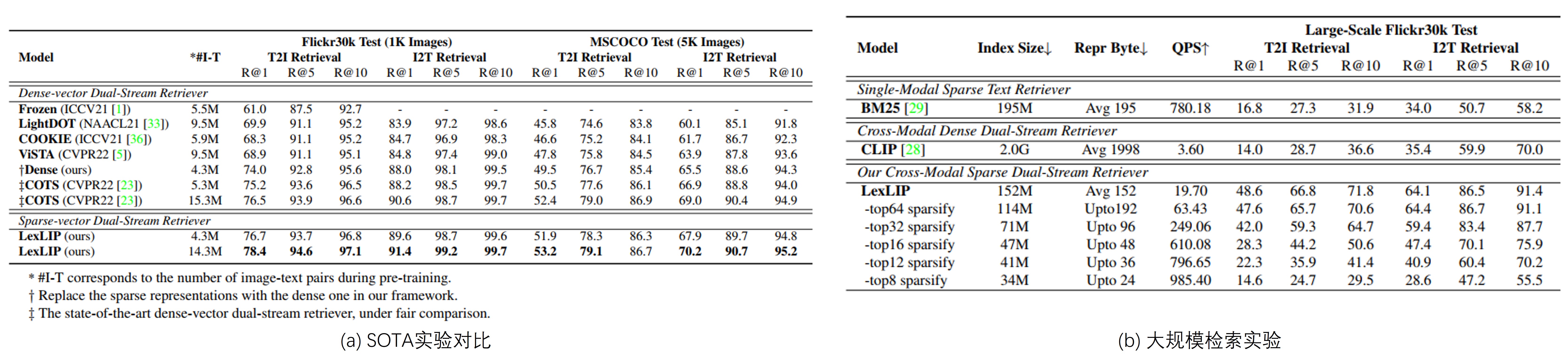
作者进行了一些实验去对比LexLIP的模型性能和速度,如Fig 4 (a)所示,作者对比了一些图文检索的SOTA模型,能发现LexLIP在公平比较下,大部分时候都能达到SOTA的性能,具体的实验细节就不累述了,读者有兴趣可以自行翻阅论文。 同时,作者还进行了大规模检索实验,去探索LexLIP的速度和模型性能的均衡表现,如Fig 4. (b)所示,其中的BM25,指的是用图片的caption信息去表示图片,使得可以采用BM25方法去进行图文检索,这个可视为是稀疏检索的基线,稠密检索的基线则是采用CLIP。从结果上看,LexLIP所需的索引储存量(最多152M)明显小于稠密索引(2G),甚至比BM25的索引储存量还少。在保持同样效果的前提下,QPS是稠密检索的270倍,在最佳模型效果下,QPS是稠密检索的5.4倍,并且有着模型效果上的绝对优势。和纯文本的稀疏检索基线对比,在保持相似QPS的情况下,LexLIP的模型效果也是有着明显优势(22.3 > 16.8)。这说明LexLIP在模型效果,索引储存量和检索速度上都有着明显优势,是一个适合业务落地的方法。
作者还进行了词权的可视化,如Fig 5所示,其中词权越大则可视化出来的词尺寸也越大,可以发现LexLIP这种方法还能提供比较好的可解释性,这对于线上应用来说也是很友好的。作者还对本文提到的各种损失函数进行了消融试验,结论就是各种损失函数都是有效的,不过本文就不继续累述了,读者感兴趣的请自行翻阅。

笔者之前在 《万字浅析视频搜索系统中的多模态能力建设》 [5] 中曾经讨论了在真实的视频搜索业务场景中,多模态稀疏特征的重要作用。我在看完这篇论文后,感觉这个工作还是很适合在真实的图片搜索场景落地的(甚至是视频搜索场景也可以),可以作为一个独特的多模态稀疏召回通路而存在,其特征甚至排序阶段也有作用。不过这个倒底还是不能完全取代稠密检索的作用,笔者在博文 [6] 中讨论过基于CLIP特征的视觉短板问题,在一些需要视觉本身的结构信息,而不是语义信息的情况下,基于CLIP方式训练出来的特征并不够完备,因此需要引入视觉自监督模型的特征,如DINO等。 本文还是在建模跨模态的语义信息,只是将其做成了视觉的离散特征,因此笔者觉得,可以考虑再引入对自监督视觉特征进行稀疏化(比如dVAE、VQ-VAE等)的召回通路,也许这样就能彻底抛弃稠密检索的召回通路了哈哈哈。算是抛砖引玉吧,读者有啥想法欢迎交流~
Reference
[1]. Luo, Ziyang, Pu Zhao, Can Xu, Xiubo Geng, Tao Shen, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. "Lexlip: Lexicon-bottlenecked language-image pre-training for large-scale image-text sparse retrieval." In Proceedings of the IEEE/CVF international conference on computer vision, pp. 11206-11217. 2023. aka LexLIP
[2]. https://fesianxu.github.io/2023/03/04/story-of-multimodal-models-20230304/, 《视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望》
[3]. Thibault Formal, Benjamin Piwowarski, and Stephane Clin- ´ chant. SPLADE: sparse lexical and expansion model for first stage ranking. In Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai, editors, SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, pages 2288–2292. ACM, 2021 aka SPLADE
[4]. Li, Junnan, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. "Align before fuse: Vision and language representation learning with momentum distillation." Advances in Neural Information Processing Systems 34 (2021). short for ALBEF
[5]. https://fesianxu.github.io/2024/06/30/video-retrieval-multimodal-20240630/, 《万字浅析视频搜索系统中的多模态能力建设》
[6]. https://fesianxu.github.io/2024/07/06/20240706-visual-shortcome-mllm/, 《基于CLIP特征的多模态大模型中的视觉短板问题》