笔者在前文[4]中介绍了LTR模型中常用的GBRank模型,在文章末尾提到了根据用户点击数据构造隐式反馈,从而构建出有序对数据进行训练,因而引出了Skip-Above这个构建隐式反馈的方法,该方法在文章[1]中提出,作者根据翔实的用户行为学实验和分析,得出了包括Skip-Above在内的一系列通过点击信号来构建隐式反馈的方法...
前言
笔者在前文[4]中介绍了LTR模型中常用的GBRank模型,在文章末尾提到了根据用户点击数据构造隐式反馈,从而构建出有序对数据进行训练,因而引出了Skip-Above这个构建隐式反馈的方法,该方法在文章[1]中提出,作者根据翔实的用户行为学实验和分析,得出了包括Skip-Above在内的一系列通过点击信号来构建隐式反馈的方法。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号

搜索系统中存在大量的用户行为反馈信号,典型的包括点击信号,展现信号,停留时长,换query率,跳转,评论分享,点赞投币等隐式反馈(Implicit Feedback),也包括一些显式反馈(Explicit Feedback)信号,比如一些搜索系统会让用户评价当前的检索结果是否满意,当然这种做法的用户体验并不是很好。通过显式反馈或者隐式反馈,一定程度上可以评价当前用户对于检索结果的满意程度,也可以视为衡量当前检索结果相关程度的手段,并且后续可以构建有序对数据进行LTR模型训练。然而,对数据进行人工标注和让用户进行显式反馈的代价都太大,最理想的是能通过用户的隐式反馈中挖掘出搜索结果之间的相关性关系,从而构建相关性有序对数据。在此之前,势必需要对用户的搜索行为进行研究,用户在搜索过程中有什么行为模式呢?用户会从返回的搜索结果中,从头到尾都扫一遍再决定点击哪个文档吗?用户对文档的点击行为只是取决于该文档的相关性吗?会受到整页排序结果的影响吗?用户会倾向于点击搜索排序第一的结果吗(即便排序第一的结果可能并不相关)?用户的行为是神秘,难以揣摩的,但是确有规律可循,文章[1]通过对用户搜索过程中的注意力变化情况(通过眼球追踪,Eyetracking实现)和点击行为,对以上问题进行解答。
笔者觉得主要的问题有两个:
- 用户行为是否可以提取出相关性信号?
- 如果可以,通过用户行为提取出的相关性信号是绝对相关性信号(Absolute Relevance Judgement)还是相对相关性信号(Relative Relevance Judgement)?[4]
以往研究表明,用户与搜索引擎的交互信号(包括点击)可以反映用户对于该搜索引擎的满意程度[5],但是还没有回答以上两个主要问题,最终还是得回到『用户是如何做出决定去点击一个文档的』这个用户行为研究上来,这样才能探明点击信号和相关性之间的关系。眼睛是心灵窗户,也是获取信息的第一门户,通过对用户的眼球移动进行跟踪,可以捕获用户在做出某个点击/不点击行为之前的潜意识,并且对其认知过程进行研究。
论文的研究思路比较直接,研究者准备了固定的几种问题,如Fig 1.1所示,其中包括了Navigational(指向性问题)和Informationl(信息类问题)两类问题,其中Navigational需要受试者去找到某个特定的主页,而Informationl需要受试者去尝试检索找到回答该问题需要的信息。然而受试者并没有被限制用何种检索词进行检索,因此受试者的检索行为是自由的。整个研究分为两个阶段:
- 阶段I: 受试者被要求对固定问题进行google检索,并且检索到需要信息后告诉研究者问题的答案。
- 阶段II: 为了研究搜索系统返回的doc排序对于用户检索行为的影响,研究者对google返回的doc进行了排序上的『操作』,如:
- 『正常』(normal): 受试者查询的doc排序是原始的google检索排序,和阶段I的排序一致。
- 『交换』(swapped): 受试者查询的doc排序,是对原结果的top2结果进行交换得到。
- 『逆序』(reversed):受试者查询的doc排序,是对原结果的完全逆序。

研究者将眼球行为分为以下几种,本文只考虑了受试者的在浏览页面上的凝视情况。
- 凝视(fixations):对空间中某个固定的位置注视持续200-300毫秒被认为是凝视,凝视表示了某个位置有值得注意的信息出现,在本文用『关注』一词表示。
- 扫视(saccades):扫视的时间持续很短,大约是40-50毫秒,由于速度过快一般认为是没能捕获充分的信息量
- 瞳孔扩张(pupil dilation):瞳孔扩张是一个受试者对某个内容引起性欲或者兴趣的标识,本文没考虑瞳孔扩张的影响
如Fig 1.2所示,该图表示用户对搜索系统返回结果的关注比例和点击比例,从图中可发现top2的文档收到了最多的关注(同时也是相近的关注),但是点击比例却差别两倍以上,也就是说在得到充分曝光的时候,用户倾向于相信搜索系统的排序结果,认为排序第一的结果应该是最好的,这个也符合我们的日常使用体验。同时,我们发现6-10位的关注程度接近,同时点击比例页差别不大,那是因为6-10位对于用户来说并不是直接可见的,需要滚动下拉(scrolling)才能看到。一旦发生滚动下拉,首位排序结果可能并不尽人意,可能后位的排序位置对于关注程度的影响就没那么大了。我们看到top4的结果收到了最多的关注度,这也是当前商业搜索引擎极为关注top4排序的原因,精排结果会直接影响到用户的体验,一旦超出10位,受关注程度就会断崖式下降。
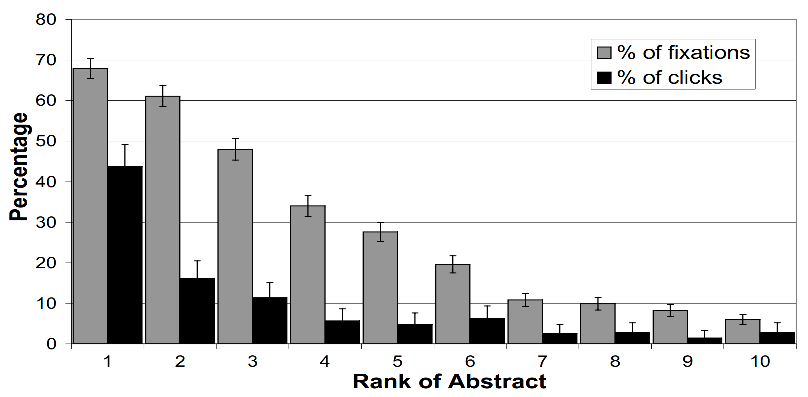
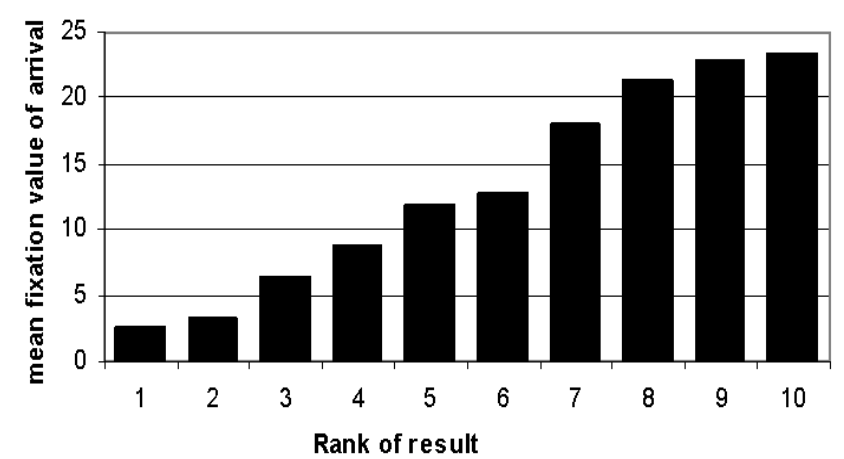
受关注度会随着排序顺序递减,意味着用户会从原始排序的顺序从上至下浏览文档的摘要信息(abstract)?研究者并没有从Fig 1.2直接得出这个结论。研究者统计了不同排序的doc中,收到首次关注次数的平均值,显然该数值越低表示该位置的doc越容易被关注,如Fig 1.3所示,研究者发现从统计上看用户的确倾向于按照排序顺序从上到下进行浏览,但是一旦超出第6位,用户关注的就不再收到排序顺序的影响了,此时由于用户没在top4找到需要的结果,因此用户倾向于不相信搜索系统的排序,因此出现了随机关注的情况。同时,即便在top4内,也可以看到top2的结果首次受关注次数平均数显然低于其他位置的,这意味着用户倾向于关注top2结果(并且消费top2结果),因此有些产品形态中如果34位没排序到好结果,其将会限制展示top2结果。
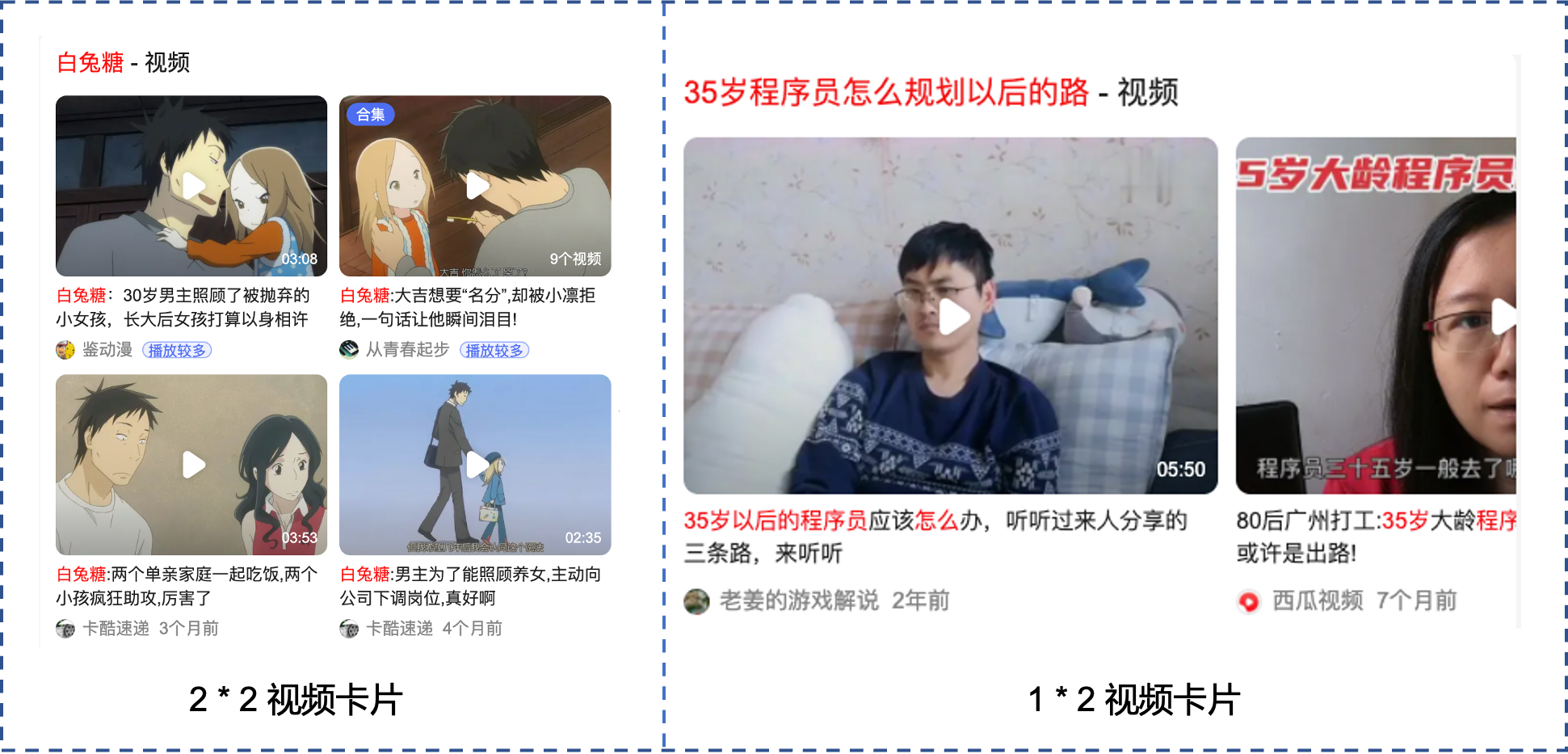
该结论的影响,在百度视频主搜上进行视频卡展现的样式中就有所体现,如Fig 1.4所示,其会根据用户检索query与返回的doc之间的需求满足程度与卡内排序,决定最终展现的样式到底是top4还是top2。
那么用户在点击某个文档之前,ta有如何的行为模式呢?Fig 1.5 展现了用户在点击某个位置
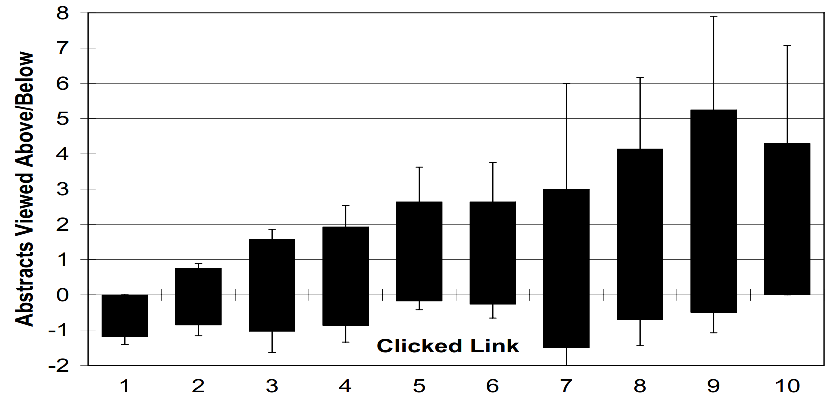
之前的实验对用户浏览搜索结果的模式,以及该模式和他们点击文档行为之前的联系进行了研究,但是仍然没有回答我们提出的主要问题。我们不禁好奇,用户的行为会受到文档相关性的影响吗?会受到整页排序的影响吗?从阶段II的逆序实验与正常实验的对比中,其实可以看出端倪,由于正常实验和逆序实验的top10文档完全相同,只是整页排序出现了逆序,研究者发现两种现象:
- 在逆序实验下,受试者会对排序越后的文档进行更为频繁地点击。
- 在逆序实验下,受试者倾向于更少的点击top1文档结果。
在正常实验下,受试者点击文档的平均排序是2.66,而逆序实验下的平均排序是4.03;正常实验下的每个query下的平均点击为0.80,而逆序实验下的平均点击为0.64。这些实验证明用户不仅对单个文档的相关性有感知,而且整页排序的结果(即便top10只是逆序)也会严重影响用户的搜索行为。也就是说用户的点击行为某种意义上可以描述相关性,至此我们回答了第一个问题『用户行为是否可以提取出相关性信号?』。我们还剩下一个问题,『用户行为提取出的相关性信号是绝对相关性信号吗?』,换句话说,同个query的检索结果下,点击越多的文档其相关性越高吗?回想到之前的一个实验现象『用户倾向于点击搜索系统排序靠前的结果,特别是top2』,这个现象有两种解释:
- 搜索系统排序靠前的结果相关性的确好,用户通过自己的相关性判断,进而甄别了相关结果。(相关性判断是内源性的)
- 用户倾向于相信搜索系统的排序结果,用户认为搜索系统排上top2的结果肯定是最为相关的。(相关性判断是外源性的)
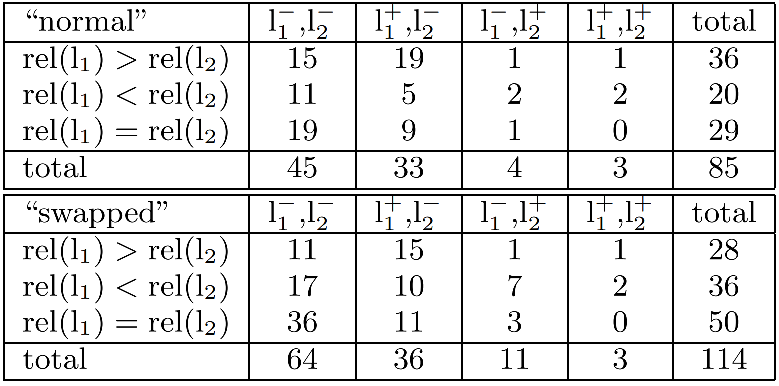
从Fig 1.2中我们已经知道top2的关注程度是非常相近的,也就是用户的点击行为首先不会受到展现的影响。假如用户对文档的相关性判断都来自于内源性判断,那么top2结果的逆序将不会影响用户的点击行为。在阶段II的交换实验(swapped)中设计了对top2结果进行逆序,如Table 1.1所示,其中的『+/-』表示在该排序下,是否用户点击了,而rel()表示人工相关性判断。不难看出即便top2逆序的情况下,用户仍然倾向于点击top1结果,而并没有完全依靠内源性相关性进行判断。这个实验证实了,文档的绝对点击数并不能反映该文档的绝对相关性,因为文档的点击数会受到文档的排序结果的严重影响。这个用户行为倾向被称之为『信任偏差(Trust bias)』。
用户的相关性判断会受到整页排序的影响,这意味着如果要把点击信号解释为相关性信号,就必须考虑该搜索系统的具体排序能力。整页排序的结果会如何影响到用户的相关性判断呢?为了研究这个问题,研究者对逆序实验和正常实验/交换实验中的用户点击文档的平均相关性,研究者定义正常排序下的文档排序为该文档的序(rank),对于成熟的搜索系统google来说,序越小一般意味着相关性越强。在逆序实验和正常/交换实验中,用户的平均序为2.67和3.27(考虑到逆序实验中更不相关的结果被排上来了,因此逆序实验中只考虑序大于5的点击)。这意味着在整页排序差的情况下,用户对于相关性的判断能力也下降了。这个被称之为用户的『质量偏差(Quality bias)』。『信任偏差』和『质量偏差』的存在意味着不能将点击信号解释为绝对相关性判断。
那么点击信号是否可以解释为相对相关性判断呢?答案是Yes。研究者的思路是,不仅考虑点击的文档,而且考虑未被点击的文档,也就是点击/未点击都看成是隐式反馈。显然,自然排序靠后的文档,但是却被点击了,其相关性要高于自然排序靠前但是未被点击的文档。质量偏差问题可以通过在同一个query下的检索结果中采样文档对(doc pair)解决,由于文档对来自于同个搜索系统的同次检索,因此可以抵消掉质量偏差问题;而信任偏差则通过采用相对相关性进行解决。
考虑如下的自然排序结果,带星号的表示被点击的文档。一般来说,排序靠后的
由此研究者提出了若干种通过用户点击信号构建相关性样本对的方法,最为常用的就是Skip-Above,也就是我们此处举例子的算法。我们可以形式化对Skip-Above进行表达:
Skip-Above: (CLICK > SKIP_ABOVE)
对于一个有序文档列表
来说,假设 包含了其中所有被点击的文档,那么存在相对相关性关系 。
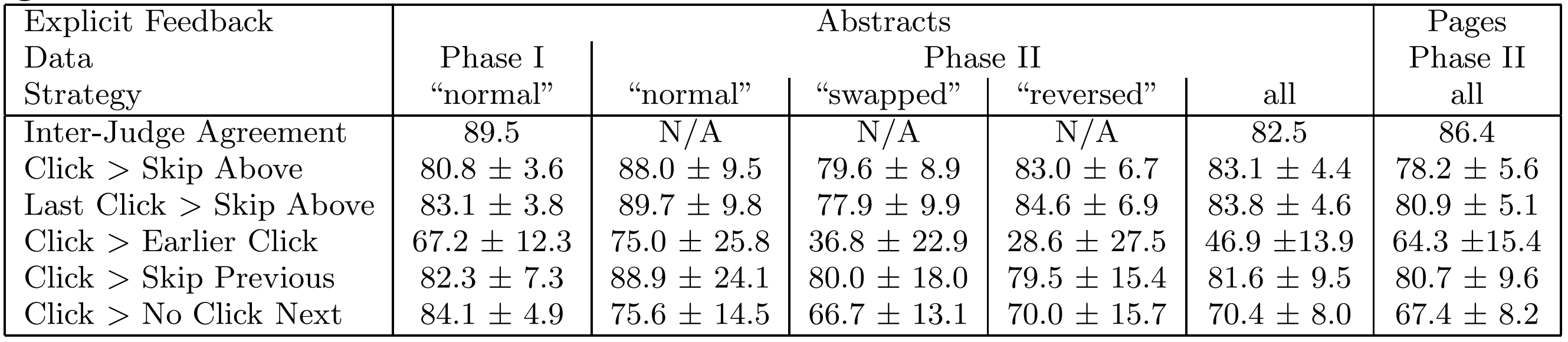
和其他方法的效果对比见Table 1.6。
在GBRank[6,4]中,就采用了Skip-Above方法的变体进行样本构建。
总结
这篇论文虽然『年纪有点大』了,但是读起来很有意思,其设计了很多实验一步步验证了用户行为和搜索结果相关性之间的关系,为我们通过搜索系统中的行为反馈信号构建数据进行训练,提供了很好的行为学研究基础,同时也为产品设计提供了理论基础。土豆认为这种论文读起来是有韵味的。
Reference
[1]. Joachims, Thorsten, et al. “Accurately interpreting clickthrough data as implicit feedback.” Acm Sigir Forum. Vol. 51. No. 1. New York, NY, USA: Acm, 2017.
[2]. Kelly, Diane, and Jaime Teevan. "Implicit feedback for inferring user preference: a bibliography." In Acm Sigir Forum, vol. 37, no. 2, pp. 18-28. New York, NY, USA: ACM, 2003.
[3]. Joachims, T. (2002, July). Optimizing search engines using clickthrough data. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 133-142).
[4]. 搜索系统中的Learning To Rank模型:GBRank https://blog.csdn.net/LoseInVain/article/details/123767279
[5]. S. Fox, K. Karnawat, M. Mydland, S. Dumais, and T. White. Evaluating implicit measures to improve the search experiences. In Talk presented at SIGIR03 Workshop on Implicit Measures of User Interests and Preferences, 2003.
[6]. Zheng, Zhaohui, et al. “A regression framework for learning ranking functions using relative relevance judgments.” Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. 2007.