Learning To Rank(LTR)模型是对搜索/计算广告/推荐系统中的排序问题进行模型建模的方法,在当前的搜索系统中有着至关重要的作用...
前言
Learning To Rank(LTR)模型是对搜索/计算广告/推荐系统中的排序问题进行模型建模的方法,在当前的搜索系统中有着至关重要的作用,本文简单介绍LTR模型中常用的GBRank模型,包括一些基本知识和笔者的理解。如有谬误请联系指出,本文遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明并且联系笔者,谢谢。
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号

搜索系统中的排序问题
如果从黑盒子的角度去看待搜索系统,那么可以将搜索系统看成是输入用户Query(用户表达需求的手段),搜索系统通过一阵鼓捣,最后输出一个相关Doc的有序列表,如Fig 1.1所示,对搜索系统更为细节的介绍可见 [5]。可以看出『有序』对于搜索系统的重要性,它直接决定了这个搜索系统的性能,而Learning To Rank(LTR)模型就是用于对若干个Doc进行排序的模型,其输入是若干个Doc的特征
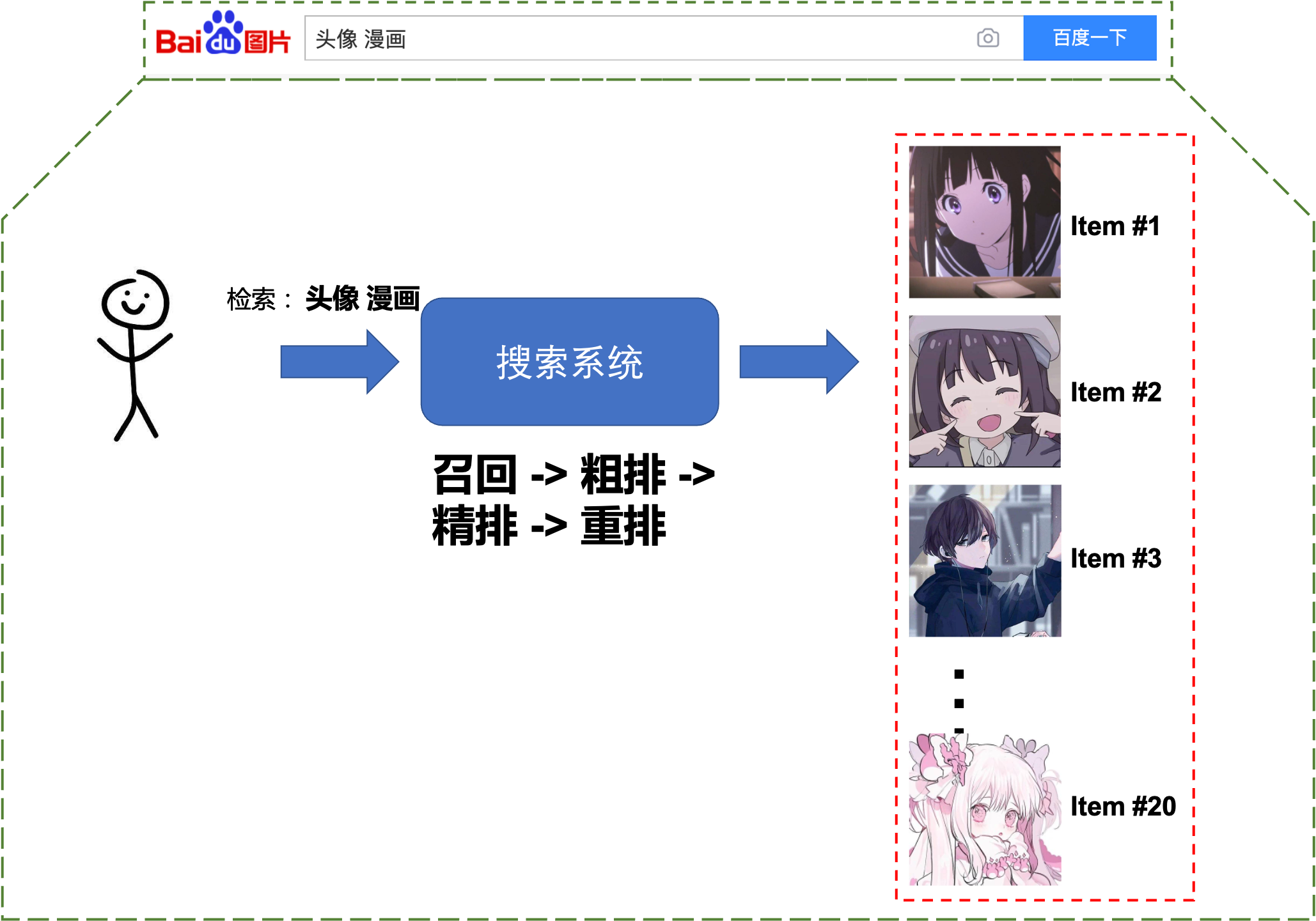
为了描述的简单性考虑,本文只考虑相关性排序。那么总得来说,LTR模型对于Doc排序可以有两种方式:
- 绝对相关性判断: LTR模型对每个文档
给出其相关性判断 ,通过对这 个数值进行排序,从而得到文档有序列表,这类型的模型通常是回归模型,比如GBDT模型。 - 相对相关性判断: 对所有文档
构建出 个有序对 ,而LTR模型通过对每个有序对进行相关性判断 ,如果 则认为 相关性高于 ,也即是 ,反之亦然。这种模型包括RankSVM,还有本文将会介绍的GBRank模型等。
绝对相关性判断LTR模型要求每个Doc都有相关性标注,通常需要大量人力进行标注。相对相关性判断LTR模型的标注是有序对的序关系,而不是对Doc的绝对判断,因此获取标注的方式有两种:1. 通过对每个Doc进行人工标注后计算
GBRank
GBRank [1]全称Gradient Boost Rank模型,其通过采用Gradient Boost Tree模型作为基模型(Base model)对有序对的序关系进行判断,我们之前在 [6]中对GBDT模型进行过简单的介绍,这里为了文章的完整性会再对GBDT模型唠叨几句。我们知道对于一个无约束的多元函数最优化问题,可以通过梯度下降进行求解。假如求解
初始化
对于
个设定的树数量来说,有: 对于
个样本,计算负梯度 对于指定的Terminal Region
而言,采用回归树方法对负梯度 进行拟合。
对于
,计算 这是对每个Terminal Region进行求平均,具体原因见[6] 更新函数:
其中的 为缩放系数, 为指示函数,当条件符合时输出1,否则输出0。
其中的超参数
我们用符号
然而(2-8)由于涉及到了两个自变量
对
进行初始化 对于
(base model的数量)有: 用
作为对 的估计,将 分割为两个互斥的集合: 用回归树
去对数据 进行拟合。 更新
为:
构建有序对数据
以上章节讲述了算法的构成,我们还一直没谈如何构建有序对数据。一般来说可以通过两种方式进行构造:1. 从人工标注数据中构造有序对;2. 根据用户行为信号构造有序对。
从人工标注数据中构造
对于某个检索词q和两个文档
根据用户行为信号构造
根据用户行为信号(比如点击信号)进行有序对构造,也称为隐式反馈(Implicit Feedback),论文[2]对从隐式反馈中构建有序数据有过深入研究,而本文也是基于[2]的研究进行的。对于一个检索词q而言,考虑其前10结果中的任意两个文档,其中的文档Skip-Above等类似的方法构造有序对,Skip-Above可以简单解释如下。假设某次检索的结果,返回了有序的文档列表(其中下标越大表示排序越后): Skip-Above认为排序越后但是被点击过了的文档,其相关性会比排序靠前但是未被点击的文档相关性更好,也就是有 Skip-Above 方法。可以考虑对点击次数卡阈值的方法,再采用 Skip-Above进行有序对构造。Skip-Above的产生是有着用户行为学实验和分析的,这个我们后续的博文再进行介绍。
Reference
[1]. Zheng, Zhaohui, et al. "A regression framework for learning ranking functions using relative relevance judgments." Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. 2007.
[2]. Joachims, Thorsten, et al. "Accurately interpreting clickthrough data as implicit feedback." Acm Sigir Forum. Vol. 51. No. 1. New York, NY, USA: Acm, 2017.
[3]. Li, Hang. "Learning to rank for information retrieval and natural language processing." Synthesis lectures on human language technologies 7.3 (2014): 1-121.
[4]. Liu, Tie-Yan. "Learning to rank for information retrieval." Foundations and Trends® in Information Retrieval 3.3 (2009): 225-331.
[5]. 从零开始的搜索系统学习笔记, https://blog.csdn.net/LoseInVain/article/details/116377189
[6]. GBDT-梯度提升决策树的一些思考, https://blog.csdn.net/LoseInVain/article/details/113429866