在多模态大模型中,视觉连接器大致可以分为压缩型和非圧缩型,其中BLIP2提出的Q-Former [1] 是压缩型视觉连接器的代表工作之一。在论文 [2] 中,作者对Q-Former的作用提出了质疑和分析,本文进行笔记,希望对读者有所帮助...
前言
在多模态大模型中,视觉连接器大致可以分为压缩型和非圧缩型,其中BLIP2提出的Q-Former [1] 是压缩型视觉连接器的代表工作之一。在论文 [2] 中,作者对Q-Former的作用提出了质疑和分析,本文进行笔记,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键字:Q-Former、视觉连接器、视觉语义压缩、视觉语义摘要
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

多模态大模型MLLM通常由三部分组成:
- 视觉编码器,可以是CLIP、SigLIP、DINO等,采用的结构可以是ViT,也可以是传统的CNN,不过现在主流都是ViT结构,本文指的视觉编码器也是ViT的产出。
- 视觉连接器(Projector),通常是简单的MLP结构,或者Q-Former、Resampler、D-abstractor等复杂结构。
- 底座LLM,如LLama、Qwen、baichuan等。
对于被切分为
不难看出,视觉连接器作为视觉编码器和底座LLM的连接部分,起着重要的视觉语义压缩和视觉语义抽取的作用。通常来说,视觉连接器从是否进行压缩的角度,可以分为2种:
- 非压缩型连接器:如LLaVA [3] 中采用的线性连接,只是将视觉表征空间的维度
映射到文本表征空间 。 - 压缩型连接器:典型的如BLIP2中的Q-Former结构,其不仅将视觉表征空间的维度
映射到文本表征空间 ,同时进行了视觉语义令牌数量的压缩。
作者将视觉连接器中的信息压缩和语义转换阶段解耦,分别称之为压缩(compression)和摘要(abstraction),前者指的是减少视觉令牌数量,后者则指的是对视觉语义概念的抽取(如属性、实体等)。
在转入作者分析阶段之前,我们直接给出作者在本文的结论:
- 观察1: 底座LLM本身可以从原始视觉特征
中进行有效的语义提取。 - 观察2:压缩型的连接器从视觉块中提取的视觉语义信息会存在折损。
- 结论:Q-Former这种同时进行压缩和摘要的连接器,由于本身已经进行了有损的压缩和摘要,而底座LLM又会进行进一步的摘要,会导致信息损失。
我们主要看下作者是怎么分析的,作者采用了一种称之为GAE(Generic Attention Explainability)[5] 的可视化工具(在文中作者将其扩展成了R-GAE,以适配生成式的LLM模型),用来可视化文本与视觉的关联,可以简单认为激活区域越亮的部分,和文本标签的关联越大。如Fig 1. 所示,作者通过R-GAE工具去跟踪文本标签与视觉块之间的关联,为了能够分析出映射后的视觉令牌(projected visual tokens)的作用,作者将其拆解为了Text -> Patch = Text -> Query * Query -> Patch两个过程,如公式(1)所示,这种拆解让我们可以分别观察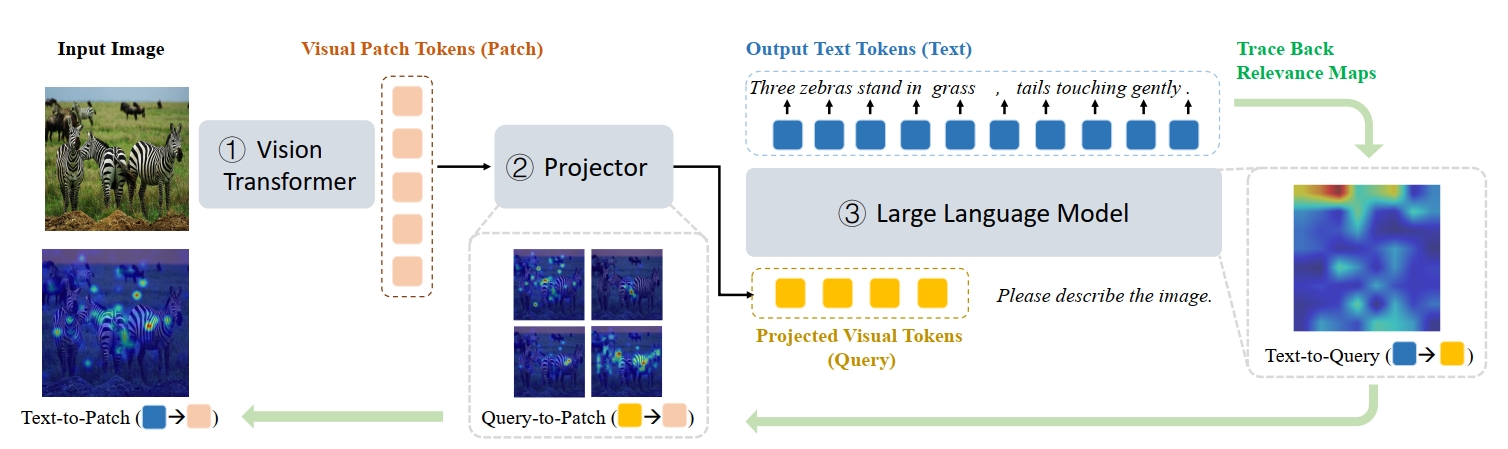
如图Fig 2.所示,我们能看到对于同一个文本描述"remote with purple and red buttons"(带着紫色和红色按钮的遥控器),在不同视觉连接器(线性、Q-Former)下的R-GAE可视化结果。我们分别分析下:
对于线性的连接器,其不具有压缩的作用,因此视觉令牌数量维持在了576个。从Text-Patch的可视化结果来看,模型主要关注在了紫色的按钮上,通过拆解,可以发现这个语义提取主要是Text-Query贡献的,再看到Query-Patch部分没有明显的高亮部分,意味着从原始图像块(Patch)到视觉令牌(Query)的过程中不存在语义的提取,进而也暗示着底座LLM本身具有从图片块中直接进行视觉语义提取的能力(也就是abstraction能力)。
对于Q-Former,其具有压缩(compression)的作用,视觉令牌的数量从576压缩到了64个。从Text-Patch的可视化结果来看,模型的关注点是错误的(也即是没有关注到紫色和红色的按钮上),从拆解的结果来看,我们观察到几个现象:
Text-Query部分具有明显的语义提取过程,在很多图片部分都存在语义高亮。
Query-Patch部分中,Query具有64个视觉令牌,Query-Patch部分放大的结果来看,存在很多不同Query关注在了同一个语义区域的情况,这导致了信息的冗余和浪费。注意到Q-Former是进行了信息压缩的,如果压缩后还具有比较高的信息冗余,意味着会损失一些有效信息。
在Text-Query和Query-Patch部分同时都进行了视觉语义提取(Abstraction)的现象,作者称之为双重摘要(Double-Abstraction phenomenon)。这种现象来自于Q-Former这东西同时考虑了信息压缩和信息摘要,从线性连接器的分析来看,底座LLM是可以对原始的图片特征进行语义提取的,因此作者认为一个“合格”的视觉连接器,只需要进行信息的有效压缩就足够了。

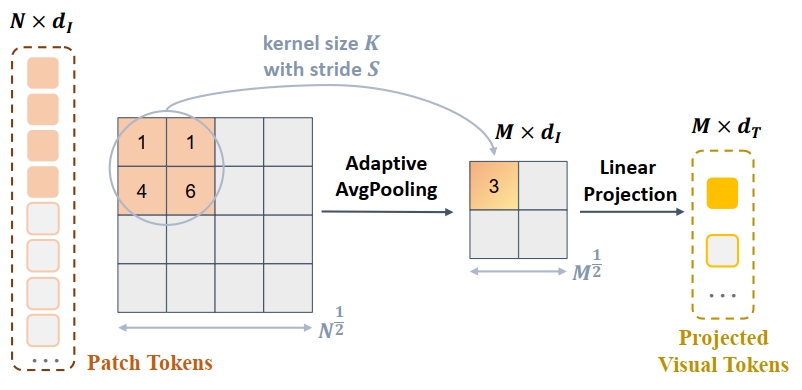
基于以上的分析和启发,作者使用了最简单的自适应平均池化作为视觉连接器,如Fig 3.所示,显然这种连接器具有信息压缩的能力(会压缩视觉令牌的数量),而且平均池化对比Q-Former,不具有语义提取的能力,从而避免了作者提到的双重摘要的问题。此时,平均池化只作为信息压缩器,而底座LLM则负责提取语义。其R-GAE的可视化结果如Fig 2.所示,从中能发现query-patch部分,query提供了更加丰富多样的视觉信息,而text-query则能正确提取语义。
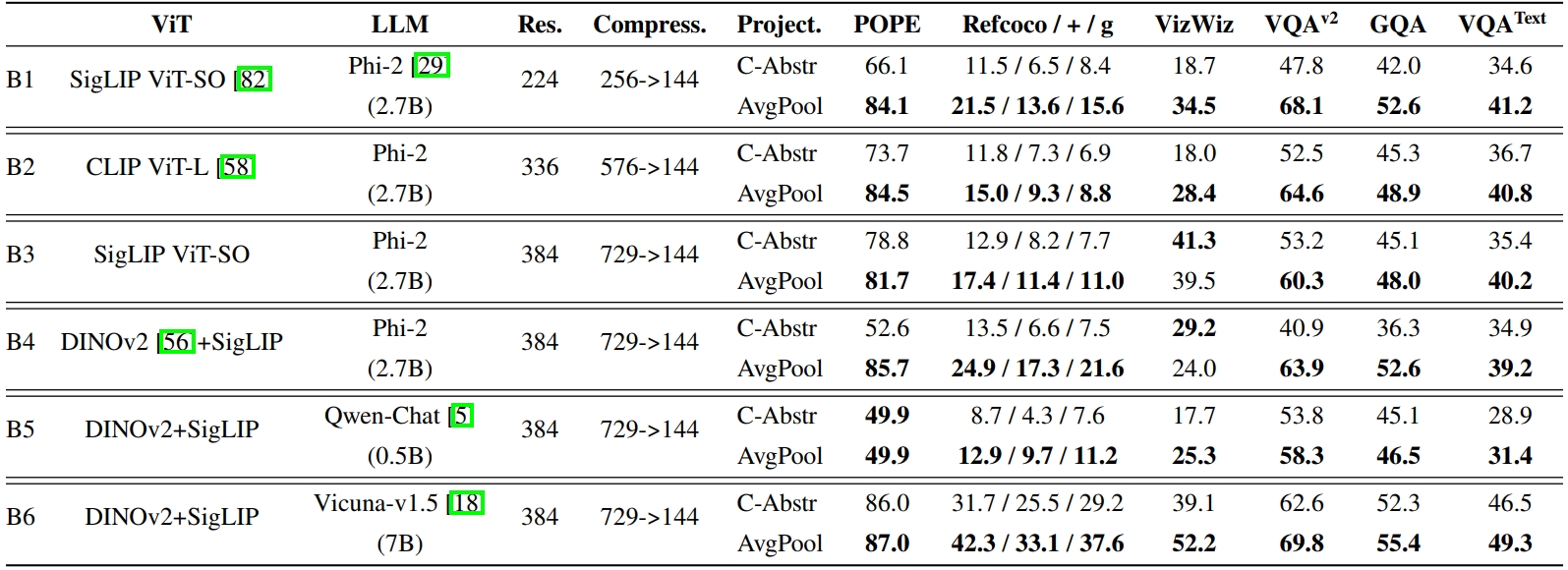
作者设计了一些实验,验证采用平均池化作为视觉压缩器的效果,如Fig 4所示,其中的Linear是没进行压缩的实验(#V=576 tokens),而#V=144的则是进行了压缩的,能发现对比主流的压缩器(Q-Former、C-Abstractor和D-Abstractor),DeCo在多个基准集合上存在效果的优势。作者也进行了进一步的实验,通过组合不同的视觉编码器、底座LLM和输入图像分辨率,如Fig 5.所示,作者发现对比C-Abstractor,平均池化(AvgPool)在多个基准测试中具有一致的优势。

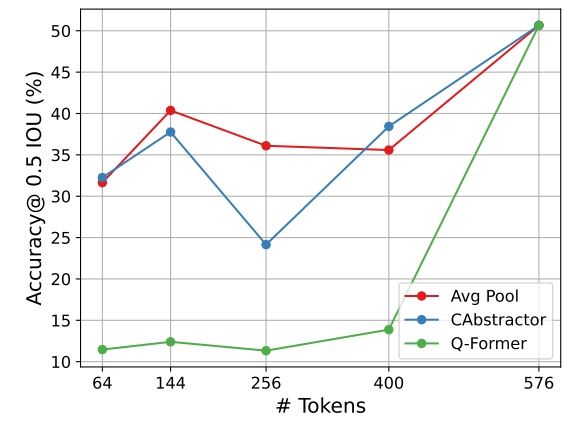
作者还进行了一个试验,逐步提高压缩视觉token的数量,也即是减少视觉信息的压缩率,如Fig 6.所示,我们会发现几点:
- 随着压缩率的减少,输入的视觉token数量会提高,无论采用的何种视觉连接器,效果总是提高的。
- 当压缩能力减少到没有的情况下,输入的视觉token数量等于原始视觉编码器提供的视觉token数量,此时采用不同的连接器效果是相当接近的。
- 在高压缩的情况下,如576->144, 平均池化连接器具有较大的优势。
- 笔者觉得有点奇怪的是,在576->256这个地方,C-Abstractor存在一个明显的性能下降,这一点有点说不过去?
笔者读下来,一个比较重要的启示就是,多模态大模型中的视觉连接器的作用,其实是可以划分为信息压缩和语义摘要的,而底座LLM本身就是语义摘要的好手,因此视觉连接器,似乎只需要做好保真且高效的信息压缩就可以了,尽量不要让它具有过多的语义提取能力,而Q-Former的设计就具有了很强的语义提取能力,导致其效果并没有很好。这个对于我们设计多模态大模型,也是一个很值得参考的结论。
Reference
[1]. Li, Junnan, Dongxu Li, Silvio Savarese, and Steven Hoi. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." In International conference on machine learning, pp. 19730-19742. PMLR, 2023. aka BLIP2
[2]. Yao, Linli, Lei Li, Shuhuai Ren, Lean Wang, Yuanxin Liu, Xu Sun, and Lu Hou. "DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models." arXiv preprint arXiv:2405.20985 (2024). aka DeCo
[3]. Liu, Haotian, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. "Visual instruction tuning." Advances in neural information processing systems 36 (2024). aka LLaVA
[4]. Lin, Ji, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. "Vila: On pre-training for visual language models." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26689-26699. 2024. aka VILA
[5]. H. Chefer, S. Gur, and L. Wolf. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 397–406, 2021 aka GAE