传统的CLIP采用对比学习的方式进行预训练,通常需要汇聚多张节点的多张设备的特征向量以进行打分矩阵的计算,训练速度通常都较慢...
前言
传统的CLIP采用对比学习的方式进行预训练,通常需要汇聚多张节点的多张设备的特征向量以进行打分矩阵的计算,训练速度通常都较慢,本文介绍一种采用传统的BCE损失进行多标签分类的方式,在提速2.7倍的同时,能达到CLIP的模型性能。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键字:多标签分类损失、高效视觉预训练方式、CLIP同水平编码器
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

CLIP [2] 开创了一个图文大规模预训练的时代,然而CLIP也具有不足之处,因此引出了一系列的改进工作,具体可见 [3]。 针对CLIP在大规模数据下训练速度慢的问题,已有一些工作研究,如SigLIP [4] 尝试用sigmoid损失去替换infoNCE损失,从而减少通信量,在提速的同时还能提高模型效果,具体可见博文 [5]。 本文介绍的CatLIP [1], 则是考虑将对比学习这种方式改为多标签分类任务,从而进一步减少通信量,并且能在各任务下达到CLIP水准的视觉编码表现。如Fig 1 (b) 所示,对于当前batch给定的

让我们具体看下整个工作,笔者曾经在博文 [3] 中谈到过自己对CLIP的理解,CLIP主要是跨图文模态语义对齐,进一步说就是对视觉语义元素,包括实体(Entity),属性(Attribution),关系(Relation)进行语义对齐。其中最为主要的,可能就是“实体”和“属性”了,至于“关系”这一个元素,则可以在语义融合阶段进行更加高效地学习。然而,有一个问题不禁在心中涌出:采用大规模对比学习的方式,去学习“实体”和“属性”,性价比是否足够高呢?
为了回答这个问题,有必要回顾下CLIP学习到语义对齐的原理,对比Image-Text Matching(ITM)和Mask Image Modeling(MIM)来说,CLIP是高效的语义对齐机制。 CLIP的模型结构和正负样本组成策略并不复杂,其负样本构成方式是经典的batch negative方式,也即是从batch内部去构成负样本,而CLIP的贡献点在于能够采用海量的来自于互联网的图文对数据(约4亿条图文对)和超大batch size(约32000)进行预训练,并且为了能够充分学习,采用了大容量的模型结构。为何CLIP的这种“朴素”学习方式可以有效进行语义对齐呢?如Fig 2. 所示,在一次对比中,正样本可以和海量的负样本进行对比,这种对比有两种维度:
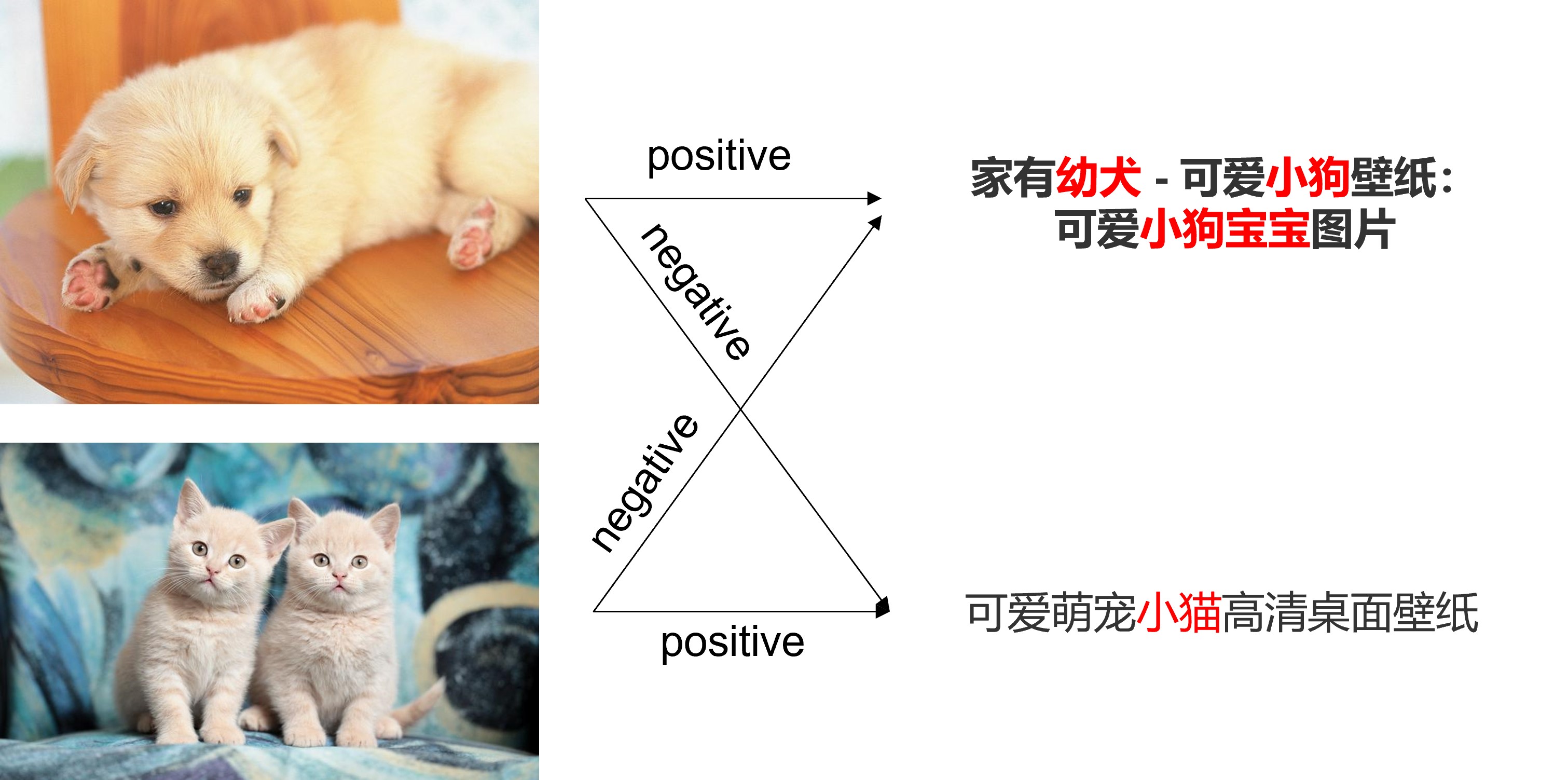
- 图-文对比:一个图片对应有一个匹配的文本(正样本),和个不匹配的文本(负样本),此时一次正负样本对比,可以充分地厘清不同文本中的视觉语义对齐。如Fig 6.2中,以第一行视为正样本,那么对于文本中的“幼犬、小狗、小狗宝宝”都是与正样本图片相符的,而其负样本文本“小猫”则和正样本图片不负。因此一次性就厘清了“小狗,幼犬”和“小猫”的语义差别,如果我们的负样本足够大,那么就能够在一次迭代过程中,厘清非常多的文本中的视觉概念,而这是MLM和ITM不能做到的。
- 文-图对比:和图-文对比类似,一个文本对应有一个匹配的图片(正样本),和
个不匹配的图片(负样本),同样一次正负样本的对比,可以厘清不同图片之间的视觉语义对齐。同样以第一行为正样本,那么文本中的"幼犬、小狗、小狗宝宝"等字样只和第一行图片匹配,和其他图片并不能有效匹配,因此能一次性厘清非常多图片中的视觉概念。
也即是CLIP中对于语义概念,除了本身图文对的正样本监督之外,都是依赖与负样本的“对比”学习出来的,而这种模式主要在学习视觉实体和视觉属性。这种学习机制,在学习初期可以有效地进行视觉概念的厘清,但是到后期后,绝大部分的负样本将会变成简单负样本(语义概念已在前期学习到了),使得学习变得缓慢且低效。回到我们的问题:光是为了实体和属性的对齐,采用大规模对比学习的方式去学习是不够划算的。
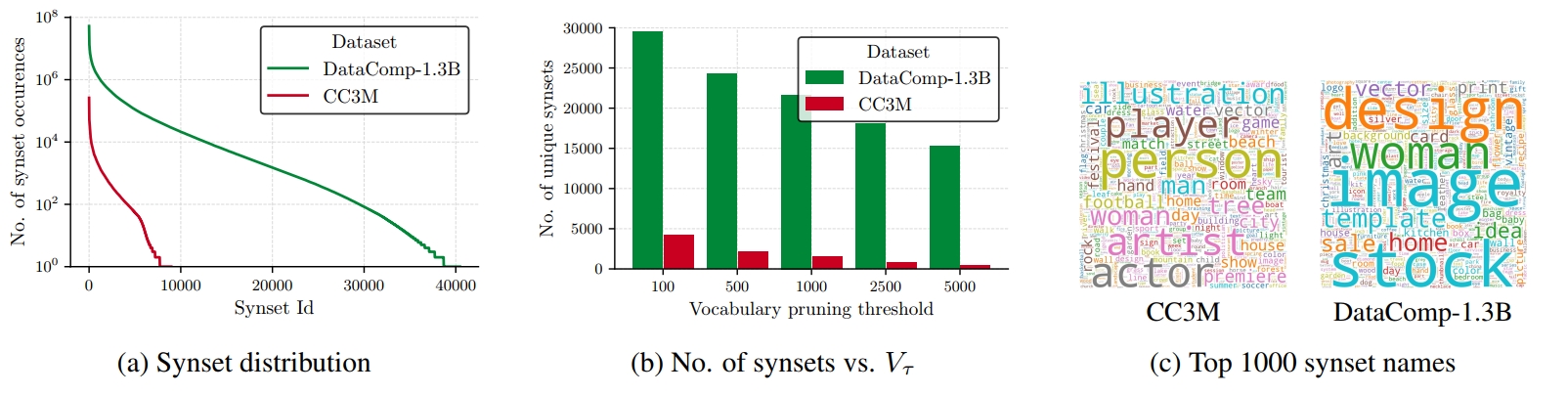
而本文的CatLIP作者提出了一种方法,将对比学习任务改为多标签分类任务,其中的多标签就是来自于图文对中的文本描述,主要就是各种名词性的实体,为了进一步提高泛化性和zero-shot能力,作者还对这些实体进行求同义词。让我们形式化表达下整个过程,假设当前batch有WordNet中的同义词集合DataComp-1.3B和CC3M这两个预训练数据集上提取了同义词集合,可以看到:
- 越大的预训练集合(13亿 vs 3百万),其同义词集合的尺度就越大(将近40000 vs 将近10000),这代表越大的预训练数据具有更多的内容丰富度和多样性。
- 采用阈值
进行筛选后,整个多标签分类任务的类别将在2000-25000左右。
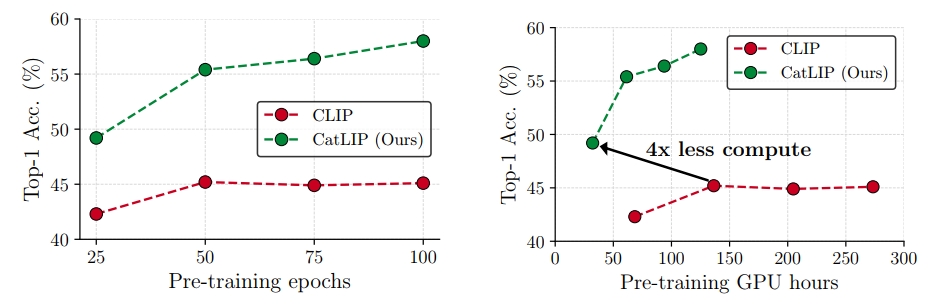
作者对比了CatLIP和CLIP (图像编码器都是ViT B/16)在数据集CC3M上的预训练效果,采用ImageNet-1k的线性探测(Linear Probe)top-1准确率作为指标监控,如Fig 4. 所示,可以发现:
- CatLIP不需训练文本编码器,并且只需要对最基本的梯度进行跨卡通信,训练速度快。
- CatLIP的指标随着训练epoch的数量提高而递增,而CLIP则会达到饱和,这意味着CLIP或许需要更大的预训练数据集。
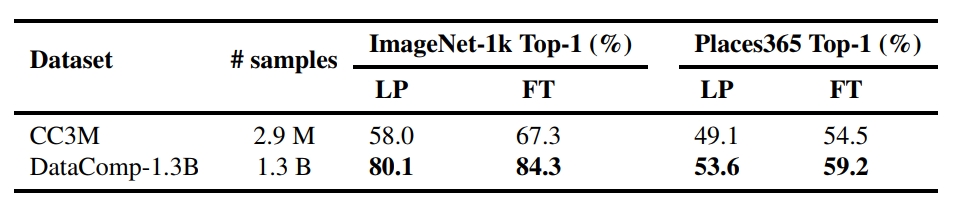
CC3M是一个只有3百万图文对的小型预训练数据,作者也进行了数据尺度放缩的试验,将预训练数据集换成了DataComp-1.3B,一个具有13亿图文对的数据集,实验结果如Fig 5.所示,通过放大预训练的数据量,CatLIP能够得到可观的、一致的性能提升。
作者在原文还对模型尺度放缩的效果进行了对比,同时用CatLIP在其他任务(如分类任务、语义分割、目标检测和实例分割等)进行了效果验证,结论是采用CatLIP的方式预训练的模型,在这些任务中都得到了持平或者更好的模型效果表现。在此就不展开了。最后贴一张CatLIP和其他同类模型的对比参考,任务是分类任务。
![]()
笔者读后感:
这篇论文给笔者带来的启发,就是CLIP中语义对齐部分的实体语义对齐,可以拆分为简单直白的多标签分类任务进行建模,损失就是Binary Cross Entropy损失,这个的确能带来训练速度上的大幅度提升。不过笔者还是有点疑惑的地方:
- 只对名词进行检测并且求同义词集合,一些视觉属性,比如颜色、图样(条纹状、格子状等)等形容词,是不是就没法建模了?这个CLIP应该是可以建模出来的。同理,关系类的视觉概念似乎也没办法建模了。
- 对于组合型视觉概念更加不友好了,虽然CLIP也对组合型的视觉概念不友好,但是还是能学习出高频组合概念的,但是我理解在CatLIP中由于完全拆分为了多标签分类任务,并且没有对比的过程,已经没办法建模组合概念了。
- 我直观上感受是,CLIP是一个主要通过正负样本对比去学习视觉概念的过程,这个过程如果设计好正负样本,比较容易建模细粒度的视觉概念,CatLIP这种方式,可能没办法对细粒度的概念(比如比同义词集合中的描述粒度还小的概念)进行学习。
先存疑吧,后面继续看看有没有后续工作讨论我的这些疑问的,也欢迎读者评论区交流&指正。
Reference
[1]. Mehta, Sachin, Maxwell Horton, Fartash Faghri, Mohammad Hossein Sekhavat, Mahyar Najibi, Mehrdad Farajtabar, Oncel Tuzel, and Mohammad Rastegari. "CatLIP: CLIP-level Visual Recognition Accuracy with 2.7 x Faster Pre-training on Web-scale Image-Text Data." arXiv preprint arXiv:2404.15653 (2024). aka CatLIP
[2]. Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. "Learning transferable visual models from natural language supervision." In International conference on machine learning, pp. 8748-8763. PMLR, 2021. aka CLIP
[3]. https://fesianxu.github.io/2023/03/04/story-of-multimodal-models-20230304/, 《视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望》
[4]. Zhai, Xiaohua, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. "Sigmoid loss for language image pre-training." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11975-11986. 2023. aka SigLIP
[5]. https://fesianxu.github.io/2024/09/08/sigmoid-language-image-pretrain-20240908/, 《SigLIP——采用sigmoid损失的图文预训练方式》