LLM的预训练是决定其底座能力的至关重要的步骤,其预训练数据通常会包含有多种领域的数据,如何调整不同领域的数据配比(可以理解为采样频率)是极其重要的大模型预训练研究点...
前言
LLM的预训练是决定其底座能力的至关重要的步骤,其预训练数据通常会包含有多种领域的数据,如何调整不同领域的数据配比(可以理解为采样频率)是极其重要的大模型预训练研究点。本文介绍DeepMind提出的一种基于代理模型去估计最佳数据配比的方法,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键字:LLM预训练数据配比、代理模型估计数据配比、大模型预训练
- 发表会议:NIPS 2024
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎:https://www.zhihu.com/people/FesianXu
微信公众号:机器学习杂货铺3号店

为了提高LLM底座的通用能力,通常预训练数据都会包含有各种领域的数据,比如The Pile [2] 就是一个800GB大小的,涵盖了22个不同领域的常用预训练数据集,如Fig 1所示。对于LLM预训练而言(采用next token prediction的自回归方式进行预训练),不同领域数据的配比很重要,之前的工作大部分基于启发式的方法拍定配比(比如均匀采样,或者根据不同领域数据的数据量大小进行采样),由于不同领域数据的学习难度各不相同,这些启发式的配比方法不能保证LLM在预训练阶段充分利用数据。本文旨在利用一个小规模的代理模型(280M参数量),通过Group DRO (Distributionally Robust Optimization) [3-4] 1的方式去寻找最佳的数据配比,然后在全量参数的LLM(8B参数量)上进行预训练,通过这种方式,作者发现预训练速度能加速2.6倍,并且最终能获得6.5%的效果提升,最终整个方法被称之为 DoReMi (Domain Reweighting with Minimax Optimization),接下来让我们具体看看这个方法是怎么实施的。
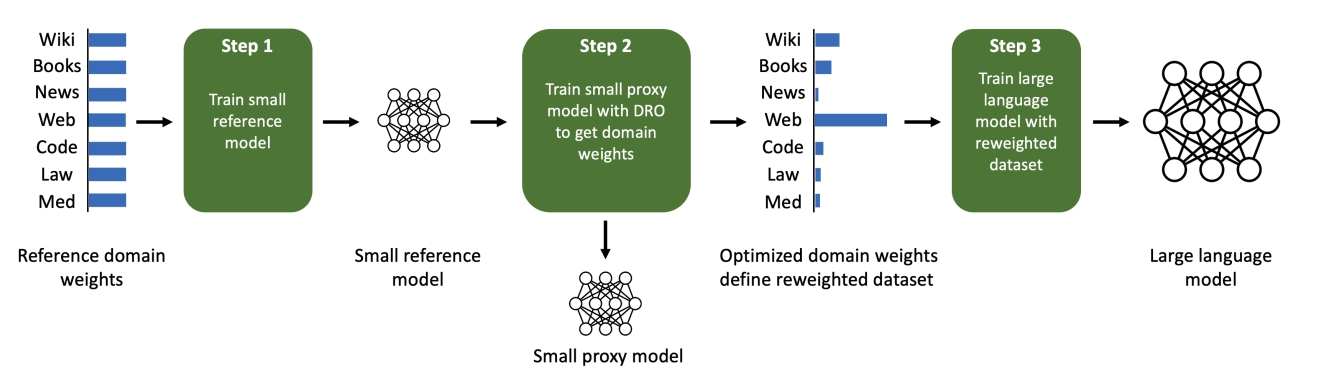
首先,我们先理解一个点:LLM在通过自回归进行预训练的时候,其最理想状态应该是能拟合不同领域数据的分布,也就是各个领域数据的困惑度都最小化 2。因此,如果我们能在“监控”预训练过程中的各个领域数据中,通过损失大小确定拟合程度最差的样本来自于哪个领域,然后适当提高这个领域数据的采样率,那么理论上LLM就能有更多机会去学习较难拟合的领域的数据分布,从而以更小的训练代价实现更好的拟合效果。当然,完整的LLM参数量动辄10亿(B)规模,训练一次的成本较高,我们假设参数量较小的(亿级别,如280M)LLM模型的预训练趋势和完整参数量(8B)的LLM模型是类似的,因此可以共享相同的数据配比,我们称此处的较小参数量模型为代理模型,通过代理模型我们能找出最佳数据配比,然后给完整参数模型进行预训练,整个过程可以参考Fig 2.示意。
由于需要判断拟合程度最差的样本,这是一个“比较”的过程,比较的一方是代理模型(proxy model),而比较的另一方则是一个参考模型(reference model) ,参考模型指的是在默认的启发式数据配比下,用和代理模型同样参数量的模型(也就是280M),预训练得到的模型。
至此,我们需要了解的DoReMi的基本思路已经介绍完了,我们开始深入细节。首先先进行形式化表示,假设预训练数据集中具有
第一步,训练一个参考模型
首先采用初始化的数据配比
第二步,通过Group DRO的方式训练一个代理模型并且得到新的域权重
有了参考模型minmax过程,其优化目标正如我们前文讨论的,优化(体现在min目标上)各域上最差拟合程度样本(体现在max目标上)的损失,我们着重讲解下这个公式。 minmax的内层目标(也即是max)看起,此时代理模型不进行参数更新,优化项是min目标,此时优化项是代理模型参数
这个过程,用算法描述的形式表述则是:
输入:各个域的数据
- 初始化代理模型参数
- 初始化域权重
对于
从
中采样一个大小为 的小批量 ,其中 令
为样本 的token长度 计算每个域
的超额损失( 是第 个token的损失),此处的 就是在实现公式(2)里面提到内层 max过程,需要保证超额损失的非负性,其中的。 启发式地更新域权重(指数更新):
更新归一化和平滑的域权重:
, 此处采用平滑更新的方式,是希望整个域权重更新的过程更加平滑(因为每次只见到了当前batch的数据,因此可能存在噪声),最好是在先验分布 的基础上进行增量更新。 使用目标
更新代理模型的参数 (可以采用Adam优化器)。
结束循环
返回:
第三步,用新的权重训练一个完整的LLM
采用第二步得到的
迭代式的DoReMi
第一轮迭代的DoReMi的
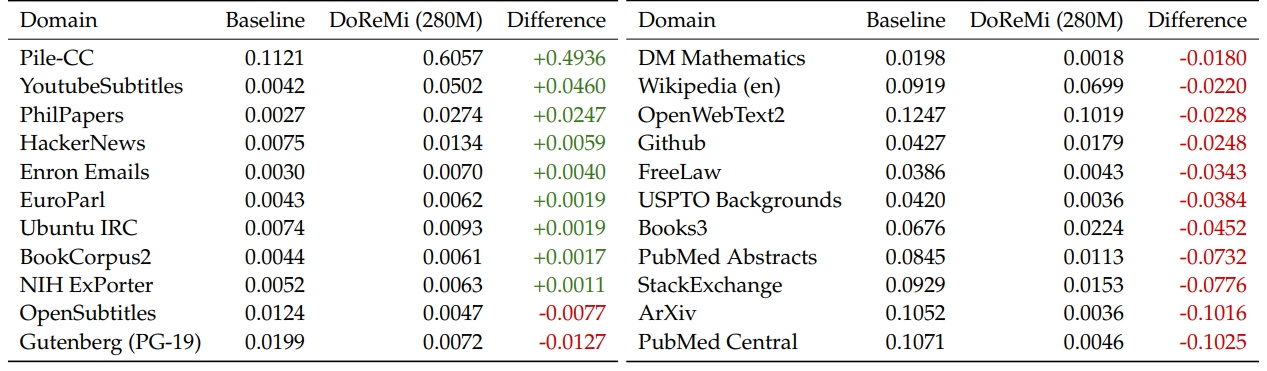
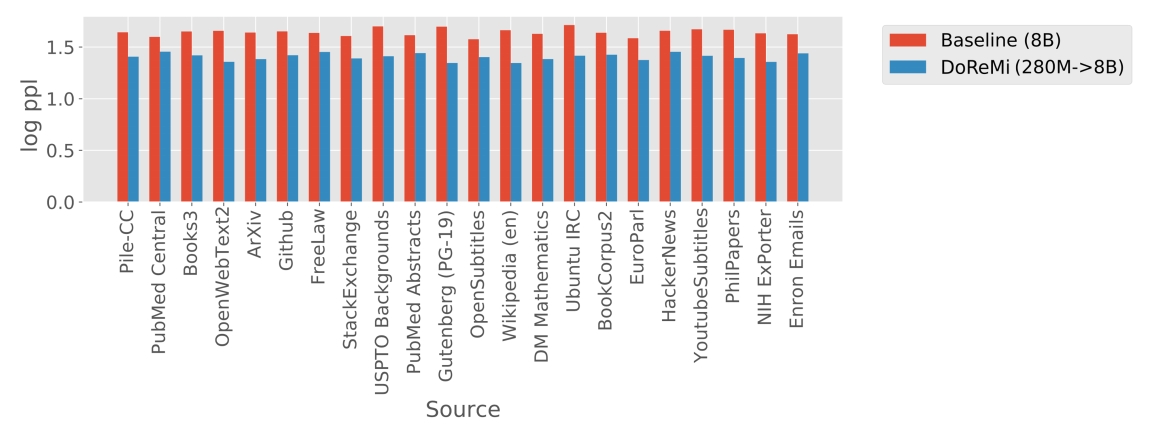
介绍完了整个DoReMi的操作过程,我们看下实验结果。作者是在The Pile和GLaM [6] 这两个预训练数据集上进行预训练的,The Pile的情况前文介绍了,GLaM是一个具有8个域的文本数据集,由于这个数据集的域权重根据下游任务的效果而调节得到,因此GLaM的域权重可以视为是真实标签,由此检验DoReMi的域权重调整结果。从Fig 1.中可以看出,经过DoReMi后,在Pile数据集上不同领域的权重已经有了很大的变化,有些域的权重存在大幅度的下降,然而如果我们看到DoReMi (280M -> 8B) 在Pile数据集上保留验证集上所有域的困惑度,如Fig 3.所示,则会发现DoReMi在所有域上的困惑度都是明显下降。这并不是很符合直觉,因为某些域(如Arxiv、PubMed central)的权重下降了很多,意味着LLM预训练过程中采样到这些域数据的几率下降了,为什么还能得到困惑度的下降呢?
一种可能性是,正如在前文讨论的,超额损失低的那部分样本都是难样本(接近均匀分布)或者简单样本,简单样本容易学习,不需要那么多样本支持学习,而难样本则由于难度太高,即便提高了样本量也无法学习出来,因此降低采样也没带来效果损失。并且很幸运的,提高了其他中度难度样本的采样比例后,让模型泛化能力得到了进步,因此在各个域数据上的表现都没折损,都有提升。
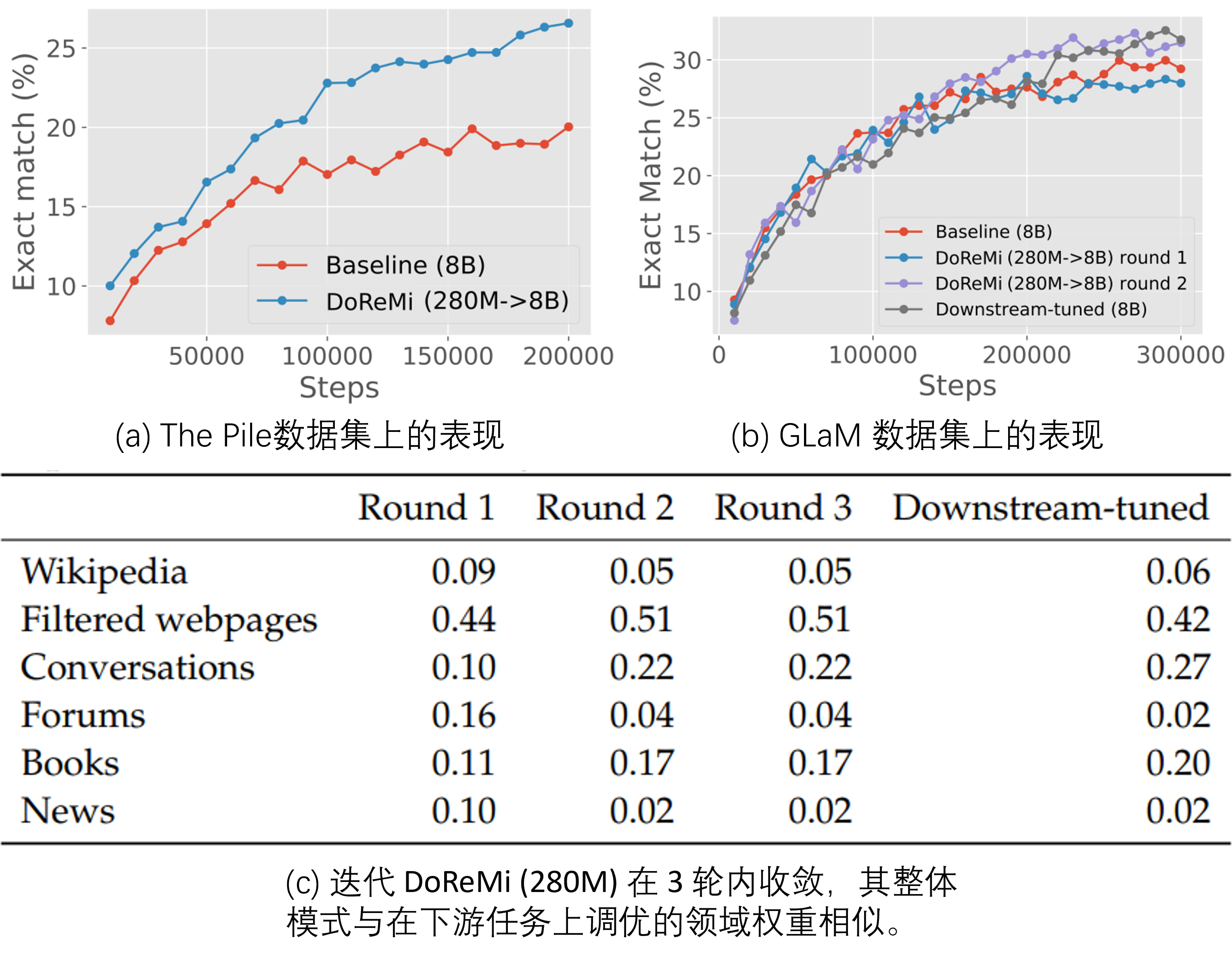
让我们看看DoReMi在下游任务上的表现,从Fig 4. (a) 中能发现,在利用The Pile预训练集的情况下,采用了DoReMi后,在所有的训练步中,性能(下游任务指标,用的是精准匹配的比例,笔者觉得可能类似ROUGE的指标)都能得到持续的提升。从Fig 4. (b) 是采用GLaM数据集作为预训练的结果,有以下结论:
- 采用多轮迭代的DoReMi(round 1 vs round 2),采用多轮迭代的效果会持续比单轮的好。
- 采用了单轮的DoReMi效果没有基线好,可能是由于GLaM数据集本身的域只有8个,DoReMi的发挥空间不如The Pile数据集。而采用了多轮DoReMi的效果能超越基线,可能说明对于域比较少的数据集,需要多轮迭代才能得到较好效果。
- 采用多轮迭代的DoReMi,其效果接近最佳权重(通过下游任务调优得到)的效果。
再看到Fig 4. (c), 这是在GLaM数据集中多轮迭代DoReMi的权重和最佳权重的对比,可以发现采用了DoReMi后,的确权重都趋向于了最佳权重了,这也证实了DoReMi的合理性和有效性。
作者同样做了消融试验,去回答DoReMi中几个关键问题:
Q1:是否挑选最难的样本或者最简单的样本,而不是超额损失最大的样本效果会更好?
A1:当前的挑选标准是超额损失,即是
,如果挑选标准变成最难样本,即是 ,或者挑选最简单样本,即是 ,试验效果会如何呢?见Fig 5. 右侧所示,我们发现采用了最简单样本或者最难样本的试验,效果都不如DoReMi,并且采用了最简单样本的方案,对比基线都远远落后。这说明了,学习最简单样本明显不是一个好主意,这使得大模型的底座能力缺失严重,单纯学习最难的样本也能提升LLM的能力,但是光是关注最难的样本,而忽略了中等难度的样本,则也不是最优的方案。这个也和前面分析困惑度的试验结论遥相呼应了。
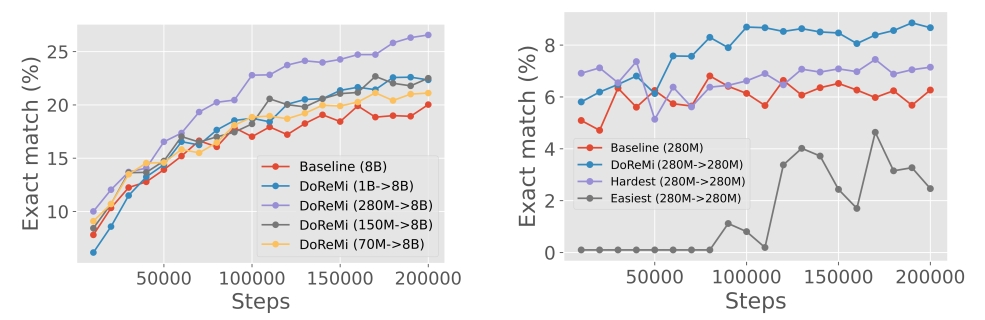
Q2:提高代理模型的参数尺寸,是否能获得最后效果的提升?
A2:考虑采用不同的代理模型尺寸,如70M、150M、280M、1B参数量,而最终模型的尺寸仍然是8B,是否会观察到scaling law呢?如Fig 5. 左侧图片所示,适当提升代理模型尺寸(
70M -> 150M -> 280M)可以提高最终模型的效果,但是当代理模型尺寸达到一定大小(如1B)后,反而出现了性能下降。因此对于代理模型而言,也并不是尺寸越大越好。Q3:如果代理模型达到和最终模型同样的尺寸,代理模型和最终模型的效果对比如何?
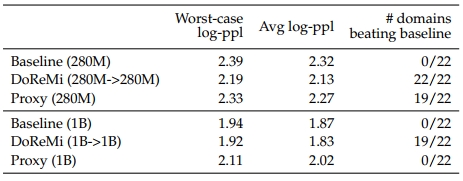
A3:这个问题其实也很符合直觉,代理模型和最终模型采用的采样策略是不同的(损失重参数化 vs 重采样)。作者尝试将代理模型和最终模型的参数量都设置为相同(为了试验对比公平),然后对比基线、DoReMi (x -> x)和代理模型的表现,如Fig 6所示,我们发现采用了代理模型的表现都低于最终的主模型,并且随着模型尺寸增大,性能差别则越大。并且在1B规模的代理模型中,甚至性能还不如基线(但是其DoReMi结果还是比基线好),这意味即便代理模型没有训练得很好,在整个DoReMi体系下仍然能提升最终模型的效果。
Reference
[1]. Xie, Sang Michael, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S. Liang, Quoc V. Le, Tengyu Ma, and Adams Wei Yu. "Doremi: Optimizing data mixtures speeds up language model pretraining." Advances in Neural Information Processing Systems 36 (2024). aka DoReMi
[2]. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. arXiv, 2020. aka The Pile
[3]. Arkadi Nemirovski, Anatoli Juditsky, Guanghui Lan, and Alexander Shapiro. Robust stochastic approximation approach to stochastic programming. SIAM Journal on optimization, 19(4):1574–1609, 2009.
[4]. Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In International Conference on Learning Representations (ICLR), 2020.
[5]. Yonatan Oren, Shiori Sagawa, Tatsunori Hashimoto, and Percy Liang. Distributionally robust language modeling. In Empirical Methods in Natural Language Processing (EMNLP), 2019. aka DRO-LM
[6]. Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, M. Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, K. Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V. Le, Yonghui Wu, Zhifeng Chen, and Claire Cui. GLaM: Efficient scaling of language models with mixture-of-experts. arXiv, 2021. aka GLaM Group DRO 的关键在于通过最小化最坏情况下的损失来优化领域权重,从而使得模型在所有领域上都能达到较好的性能。↩︎ 在自然语言处理(NLP)中,困惑度(Perplexity)是评估语言模型性能的一个重要指标。它衡量模型对测试数据的预测能力,具体计算方法如下:对于一个给定的词序列 此处计算的方法是,给定一个样本