奖励模型(Reward Model)中的尺度扩展规律(Scaling Laws),也即是通过扩展奖励模型的模型大小、数据量等去提升奖励模型的能力...
前言
最近在考古一些LLM的经典老论文,其中有一篇是OpenAI于ICML 2023年发表的文章,讨论了在奖励模型(Reward Model)中的尺度扩展规律(Scaling Laws),也即是通过扩展奖励模型的模型大小、数据量等去提升奖励模型的能力,本文进行论文的读后笔记。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键字:奖励模型、尺度扩展规律、奖励模型过优化、奖励劫持
- 发表信息:ICML 2023
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

奖励劫持问题
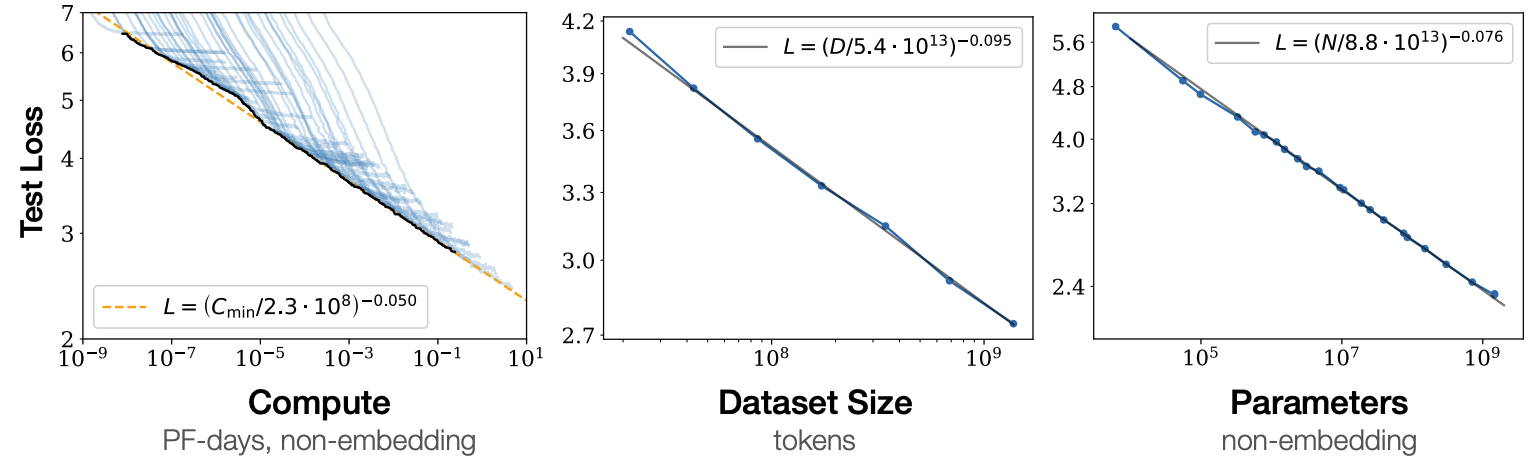
在大语言模型(Large Language Model, LLM)中,存在所谓的尺度扩展规律(Scaling Laws) [2],如Fig 1所示,即是:
LLM的性能会随着模型的参数量、模型的训练量、模型的训练数据量的增加而增加
众所周知,奖励模型(Reward Model,RM)是LLM的训练管道 1 中一个重要部件,其可对LLM的输出进行偏好打分(Preference Score),也可以视为是对LLM的输出进行质量打分。然而奖励模型会遇到所谓奖励劫持(Reward Hacking)的问题,即是奖励模型被样本的其他无关/弱相关特征所劫持,其打分不能再正确建模LLM的输出质量,最常见的就是奖励模型容易认为LLM输出越长质量就越高(被称之为长度偏置,通常来自于奖励模型的训练数据中,逻辑性越好、解释越完整的样本,其长度倾向于越长;但是反之不成立,长度越长的样本不一定是质量越好的)。奖励劫持将会使得奖励模型无法持续从LLM的输出采样中挑选更好的样本,从而影响LLM的进一步优化。
从结果上看,导致奖励劫持的原因是对奖励模型的过度优化(Overoptimization),即优化奖励模型的值过高时,反而会阻碍真实目标的性能提升。此处有一个术语描述这个现象,称之为古德哈特现象(Goodhart's Law),他是一个在经济学、社会学、管理学以及人工智能等领域广泛讨论的现象,它描述了当一个指标被用作目标进行优化时,该指标的有效性可能会因为过度优化而降低,甚至导致与原始目标背离的情况。(原文:When a measure becomes a target, it ceases to be a good measure.)
对其的改进方向是多样的,比如训练数据的多样性、奖励模型的参数量、奖励模型的训练量等,在这篇论文中,作者正是去研究奖励模型的尺度扩展规律,以及不同实验设置下对缓解奖励模型过度优化的帮助。
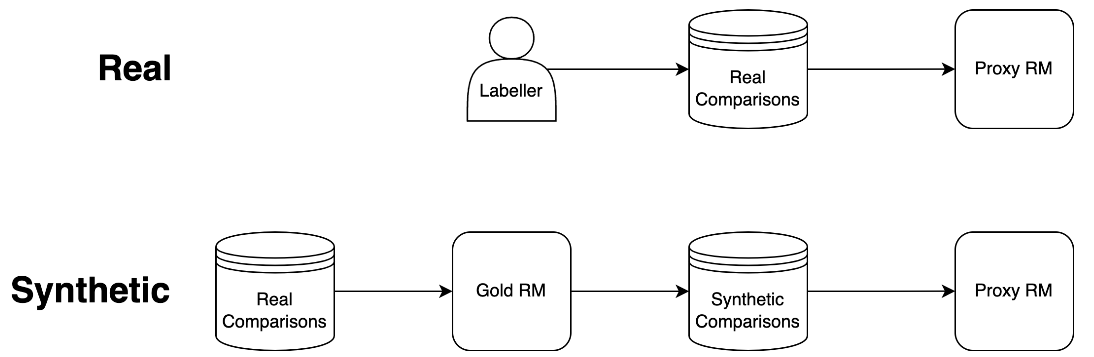
尺度扩展包含了训练数据量、模型参数量、模型训练量三个维度,后两者可以自然扩展,但是奖励模型的训练数据来自于人类标注,扩展训练数据将会带来巨大的标注代价,因此本文作者采用生成数据作为代理奖励模型的训练数据。整个流程如Fig 2.所示,常规的代理奖励模型(Proxy Reward Model) 2 是由人类标注员标注的偏好数据进行训练的,而本文采用的方法则是:
- 首先采用人类标注数据,训练一个6B大小的奖励模型,这个模型被称之为『标准奖励模型(Gold Reward Model)』,后面的所有实验中,都会认为标准奖励模型的打分是真实值 3,文章中称之为『标准奖励打分(gold reward model score)』,这用来评估不同实验设置下的代理奖励模型的效果。
- 将标准奖励模型对一批无标注的数据进行打标,然后用打标后的数据进行代理奖励模型的训练,代理奖励模型的参数量从3M到3B。在本工作中,作者生成了100K个样本,保留了10%作为验证集合用于计算RM的验证损失。
用
奖励模型参数量维度的尺度扩展
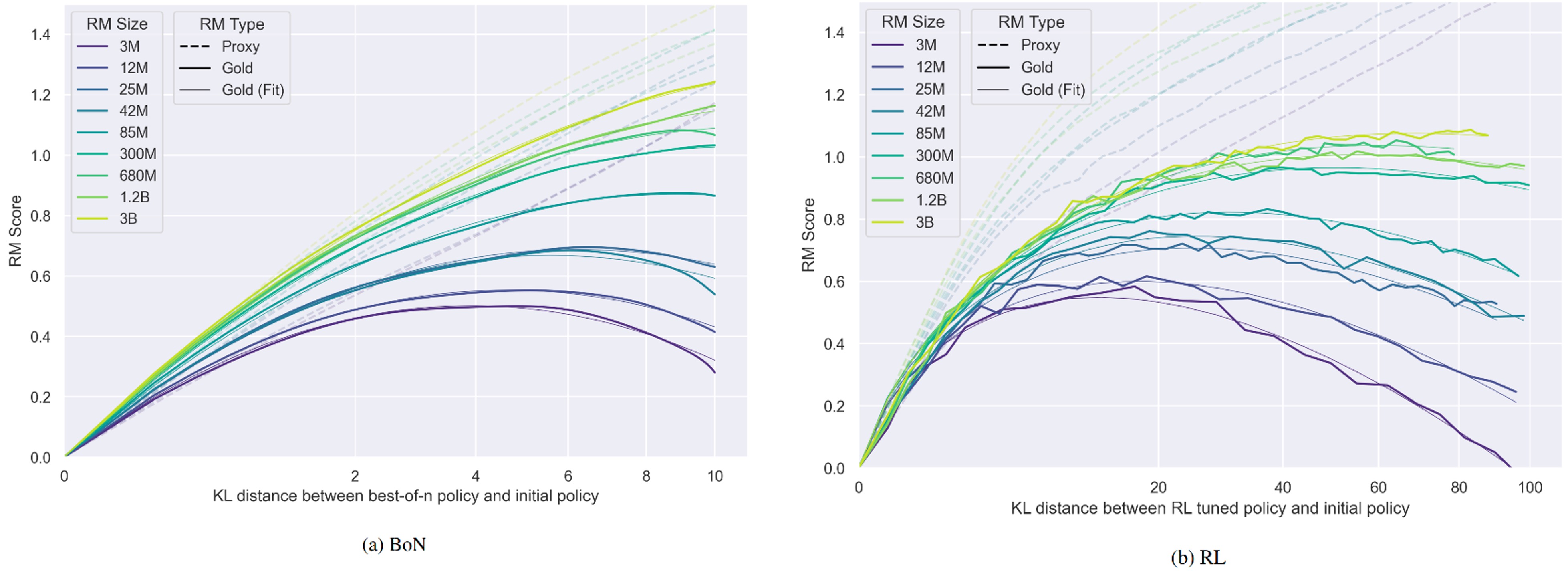
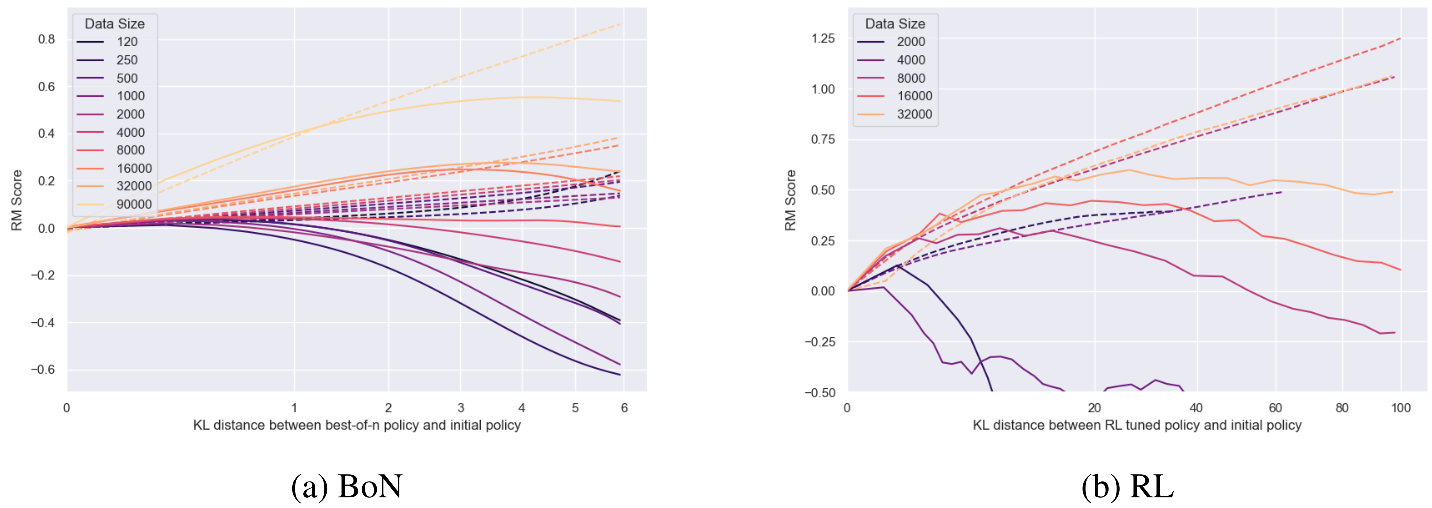
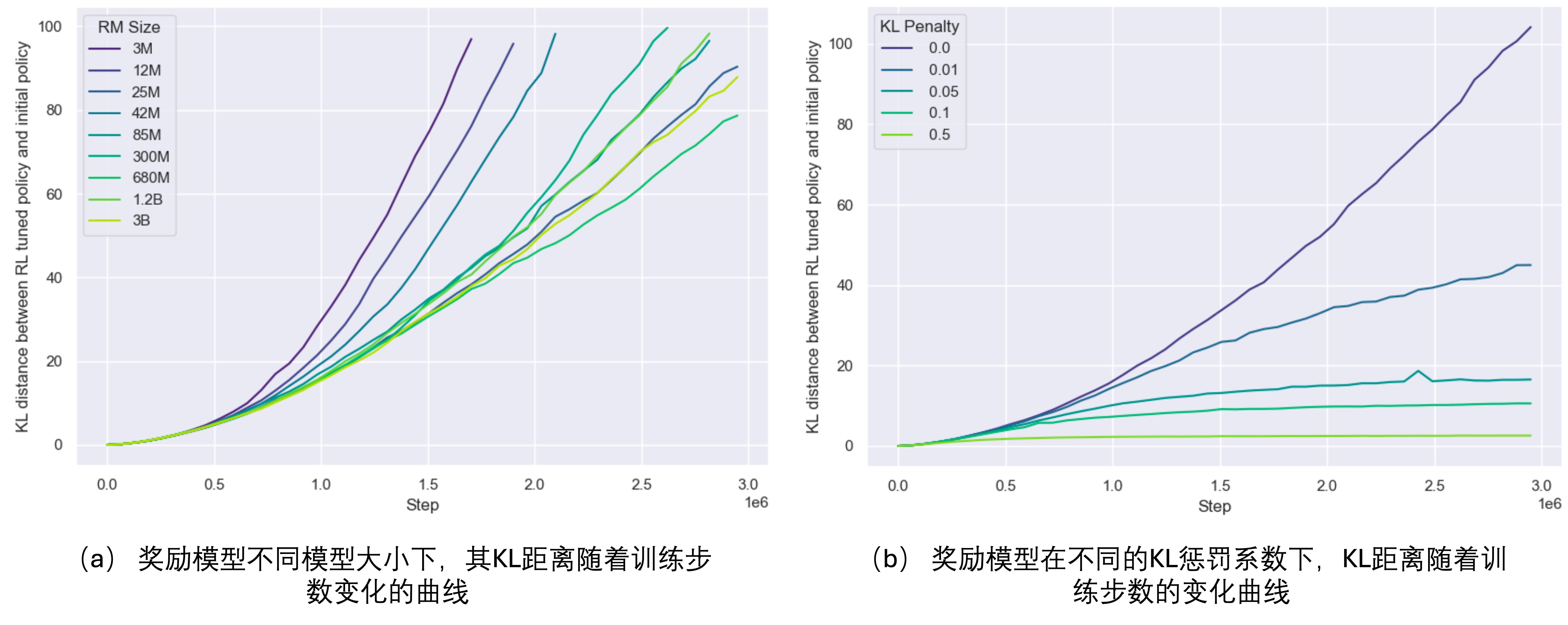
我们看到实际的试验曲线情况,如Fig 3.所示,这些是在90K合成训练数据下训练代理奖励模型(策略模型参数量固定在1.2B)的结果,分别采用了BoN训练方案和RL训练方案,横坐标是优化策略模型和初始策略模型的KL距离(表示优化程度),纵坐标是RM打分。关注到:
- 深色实线表示标准奖励模型的打分,这也是公式(1-2)所建模的,而对应颜色的浅色实线就是根据公式(1-2)的拟合曲线,能发现能很好地拟合实际实验的结果。
- 标准奖励模型能到达的顶峰值随着代理奖励模型的参数量提升而提升,存在参数量的尺度扩展效应。
- 如虚线所示,代理奖励打分是线性增加(BoN)或者对数增加的(RL),这表面对于代理奖励模型而言,是随着优化的进行,其模型效果是变得更好的。但是我们知道标准奖励打分是到一定程度后会下降的,这个差值可以认为是代理奖励模型过度优化而带来的奖励劫持程度。不难发现,奖励劫持的程度是随着优化程度逐渐变大的。
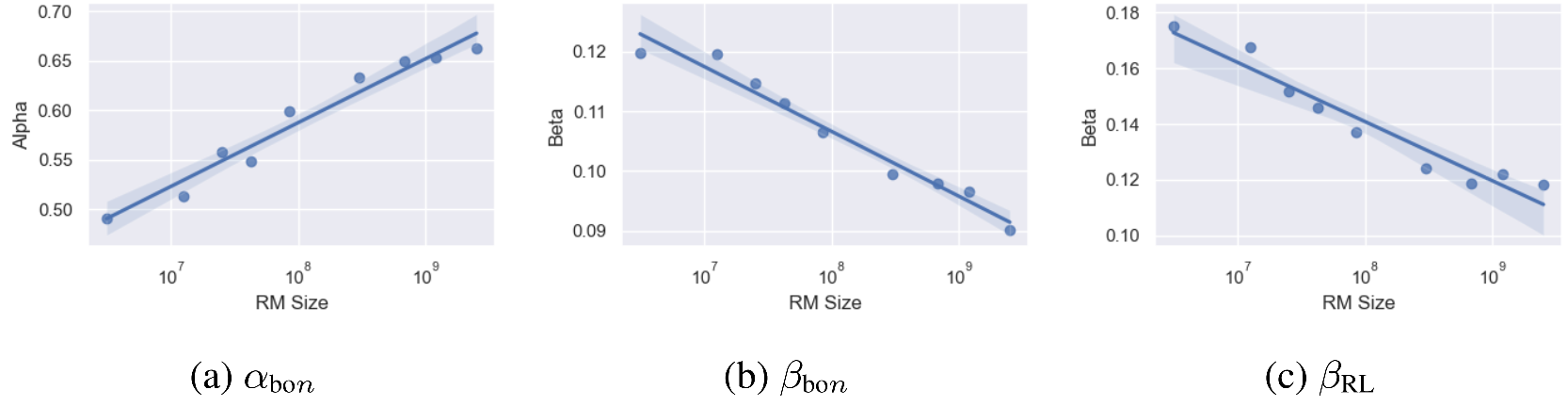
在不同代理奖励模型参数量下,从公式(1-2)中解算出的
奖励模型训练数据量的尺度扩展
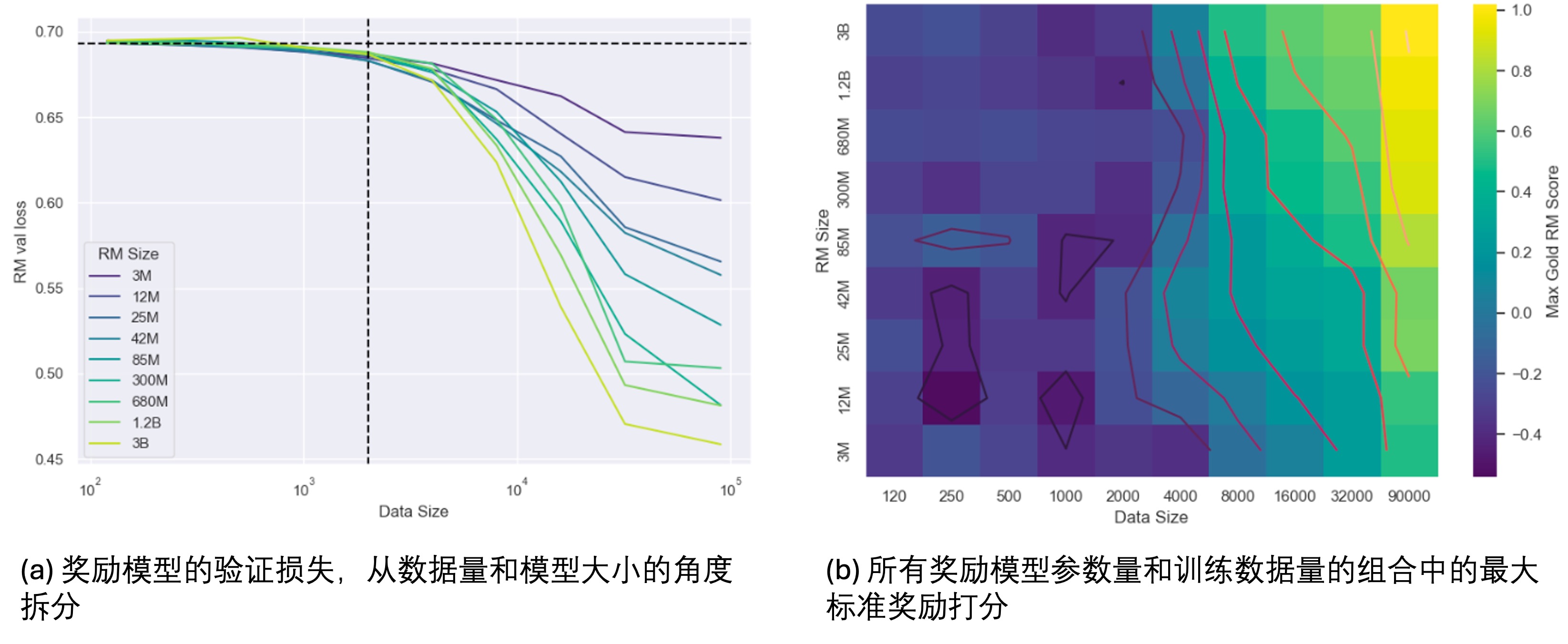
在固定代理奖励模型参数量为12M后,作者实验了不同训练数据量下的效果,如Fig 5.所示,能发现:更多的数据会带来更高的标准奖励打分和更少的古德哈特效应(可以理解为奖励劫持的现象减少了) 。不过在数据量的扩展中,未曾观察到如Fig 4一般,在
从Fig 5中能隐约发现,当训练数据量比较少的时候(比如120、250...),随着KL的增大,标准奖励打分是递减的趋势,这意味着参与训练的数据量可能有一个最低的下限。我们再看到Fig 6,从图(a)中,我们能看出:
- 在不同的模型大小下,随着数据量的提升,其模型效果在提升(RM验证损失持续下降,标准奖励打分持续提高),这证实了奖励模型也有数据量上的尺度扩展效应。
- 注意到当数据量小于2000时候,所有大小的奖励模型的性能都接近随机,这意味着对于奖励模型而言存在一个最小的训练数据量,只有大于这个数据量才能正常训练奖励模型。
策略模型的尺度扩展
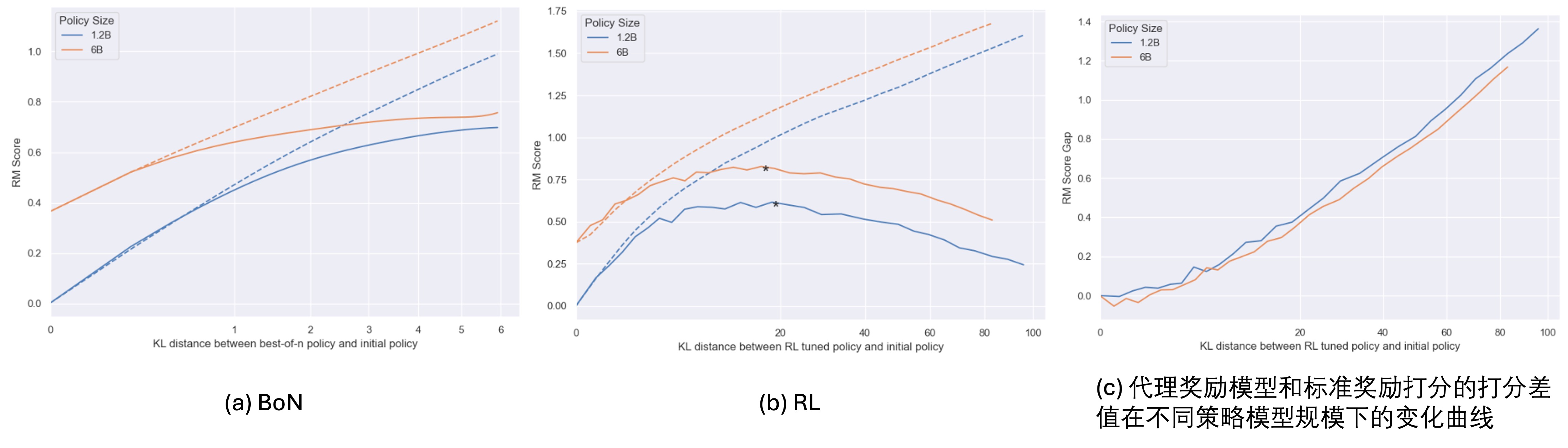
前面的研究都是固定了策略模型4大小的(1.2B参数量),作者在文章中研究了增大策略模型尺寸(1.2B
从直观上看,更大的策略模型由于会更容易生成奖励模型偏好的输出,因此会更容易过度拟合,不过从Fig 7.看并非如此,我们看到(b),两种尺寸的模型都在接近的训练程度上达到了峰值(意味着更大尺寸的策略模型并没有让过度优化变得更快),从(c)的代理奖励模型和标准奖励打分的差值来看,也能发现两种尺寸模型的奖励劫持程度基本上接近(6B模型的奖励劫持程度甚至还整体更低些)。因此,较大的策略模型在针对奖励模型进行优化时获得的提升较小,不过也不会出现更多的过优化现象。
RL和BoN方式训练模型的对比
直观上看,一个预训练好后的LLM的效果上限是其Best-of-N结果,后训练(包括行为克隆和偏好对齐等)的目的就是将Best-of-N结果蒸馏到LLM中,这个蒸馏的方式有两种:
- BoN方式:采用奖励模型对N个LLM采样结果(也称为N个轨迹)
进行打分 ,然后选取其中的最好结果集合 ,然后通过SFT将最好结果集合蒸馏到LLM中,这个过程可以迭代反复进行。如同Fig 8. 所示,在每一轮的BoN过程中,如公式(1-1)所示,其增加的KL距离是固定的。注意到,BoN的方式只会保留N个轨迹中被奖励模型选出的唯一一个轨迹蒸馏到目标LLM中,这意味着对采样轨迹的利用率较低。 - 通过PPO的方式(RL方式):采用PPO的方式,此时奖励模型同样对采样的N个轨迹进行打分,不过PPO的方式可以充分利用N个轨迹,并且策略模型在每一个训练步中,都会存在KL距离的增加,根据Fig 9 (a) 所示,其KL距离增加随着步数增加呈现二次方的关系,因此RL过程如Fig 8.的粉色虚线所示,是以逐渐增加的较大KL步长搜索到最终策略(也即是图中的
策略 #4)。当然,从图中也不难发现,RL方式的KL步长如果没控制好,就容易错过最佳策略,这也暗示了RL方式的不稳定性。
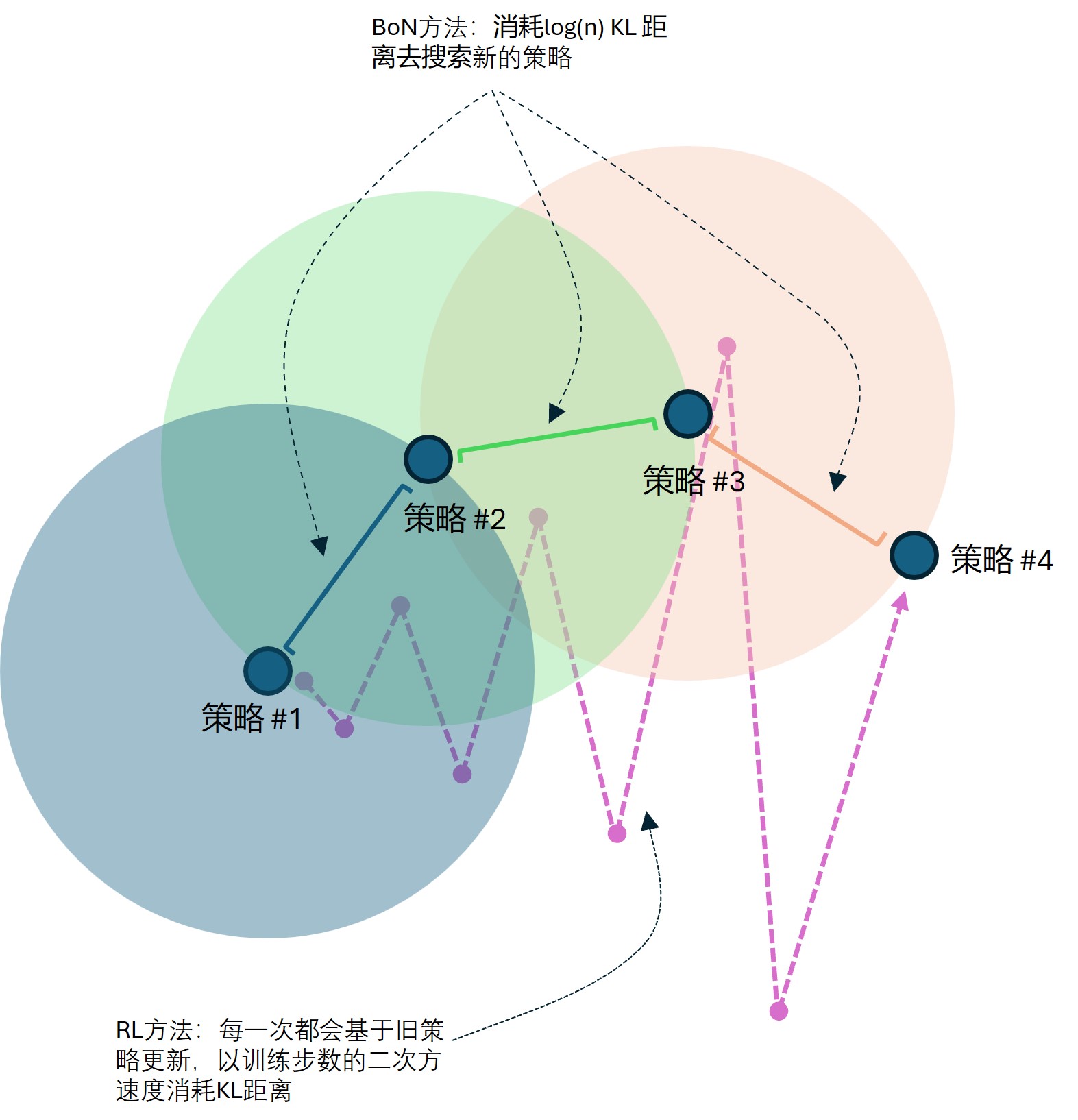
从以上讨论看,基于BoN的方法和基于RL的方法(通过PPO)去后训练LLM,其方式差别很大,预期其两者的奖励模型的过度优化情况会有所不同,因此作者在本文对此也进行了研究。作者在本文中,把KL距离视为是一种可以被『消耗』的资源,在模型训练过程中,通过消耗KL距离去找到新的策略(通过奖励模型去判断新策略是否比旧策略好),如Fig 8所示。
如公式(1-1)所示,BoN的优化方式,KL距离的增加都是稳定的,大约是
不过这也从另一种角度说明,不同的训练方式下,消耗KL距离的方式也不同,采用KL距离去量化衡量优化过程是不充足的,因此也就无法使用KL距离作为横坐标,将BoN和RL两种方式下的标准奖励打分绘制曲线进行对比。存在一些对策略的扰动,这些扰动与奖励信号正交(也即是导致奖励劫持的原因,奖励模型建模中没有建模出这些正交的扰动信号),会导致KL距离增加,但并不会提升标准奖励或代理奖励,相反,一些极其微小但精准的目标化扰动,可以在很小的KL预算内显著改变策略的行为。
作者指出,可以考虑采用代理奖励打分作为一种量化的指标,如Fig 10所示此时可以通过对比

KL惩罚项的作用类似于『早停』
在RL优化过程中,可以增加KL惩罚项(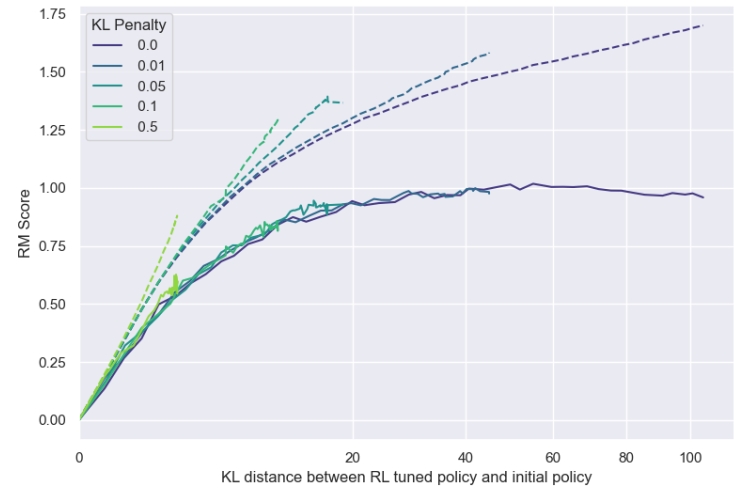
在原文中,作者还指出古德哈特现象分为以下四种,然后分析了奖励劫持现象在这四个现象中的分类,受限于篇幅本文就不展开了,有兴趣的读者可以翻阅原论文 [1]。
- 回归型古德哈特现象
- 外部型古德哈特现象
- 因果型古德哈特现象
- 对抗型古德哈特现象
笔者读下来,这篇文章的信息密度很大,是一篇常读常新的极品文章,其主要论点有:
- 奖励模型可以尺度扩展以缓解奖励劫持问题(模型尺寸、训练数据大小),但是训练数据大小会有一个最低的数量要求。
- 奖励模型的过度优化现象在不同尺寸的模型和不同大小的训练数据下都会出现。
- 策略模型的尺度扩展,对奖励模型缓解奖励劫持无太大帮助。
- KL距离是一种资源,BoN和RL的优化模式是不同的,他们消耗KL距离的方式也不同。
- KL惩罚项会加速模型收敛,但是不会提高模型的性能峰值,是一种类似『早停』的正则项。
当然,本文也留下了一些重要的待探索的问题,比如:
- 探索多轮迭代式地优化RLHF
- 继续深入探索对策略模型的尺度扩展
- 探索除了BoN和RL之外的其他训练方式
- 当前的标准模型是采用的合成标签训练的,合成标签和真实的世界标签会有差距。
如果觉得该博文对您有所帮助,笔者强烈建议您翻阅原论文,以获得第一手的信息。
Reference
[1]. Gao, Leo, John Schulman, and Jacob Hilton. "Scaling laws for reward model overoptimization." In International Conference on Machine Learning, pp. 10835-10866. PMLR, 2023.
[2]. Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
[3]. Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. Computing Research Repository, 2020. version 3 一个典型的LLM训练管道包含有:预训练(Pretrain)、行为克隆(SFT)、人类偏好对齐(Preference Alignment)等几个过程,其中的人类偏好对齐部分,通常会采用奖励模型进行偏好打分,从LLM的输出采样中选取最符合人类偏好的样本。↩︎ 之所以称之为代理奖励模型(Proxy Reward Model),是因为标注的训练数据总是有限的,因此训练出来的奖励模型其实是真实的奖励模型的一个『代理』。↩︎ 通常这类型模型在一些工作中也会被称之为『Oracle』,也就是『先知』↩︎ 策略模型(Policy Model):策略模型负责生成行为或输出,例如在语言生成任务中生成文本。奖励模型(Reward Model):奖励模型用于评估策略模型生成的行为或输出的质量,并提供反馈信号,用于优化策略模型。↩︎