大模型的尺度扩展定律告诉我们:『LLM的性能会随着模型的参数量、模型的训练量、模型的训练数据量的增加而增加』。训练存在尺度扩展定律,测试也存在尺度扩展定律,实践告诉我们在推理时候增大计算量,往往可以获得模型性能收益。那么在给定了计算预算的前提下,如何安排预算才能达到最好的模型效果呢?
前言
大模型的尺度扩展定律告诉我们:『LLM的性能会随着模型的参数量、模型的训练量、模型的训练数据量的增加而增加』。训练存在尺度扩展定律,测试也存在尺度扩展定律,实践告诉我们在推理时候增大计算量,往往可以获得模型性能收益。那么在给定了计算预算的前提下,如何安排预算才能达到最好的模型效果呢?本篇文章就在讨论这一点。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键字:尺度扩展定律、推理时计算扩展
- 发表单位:Google DeepMind
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

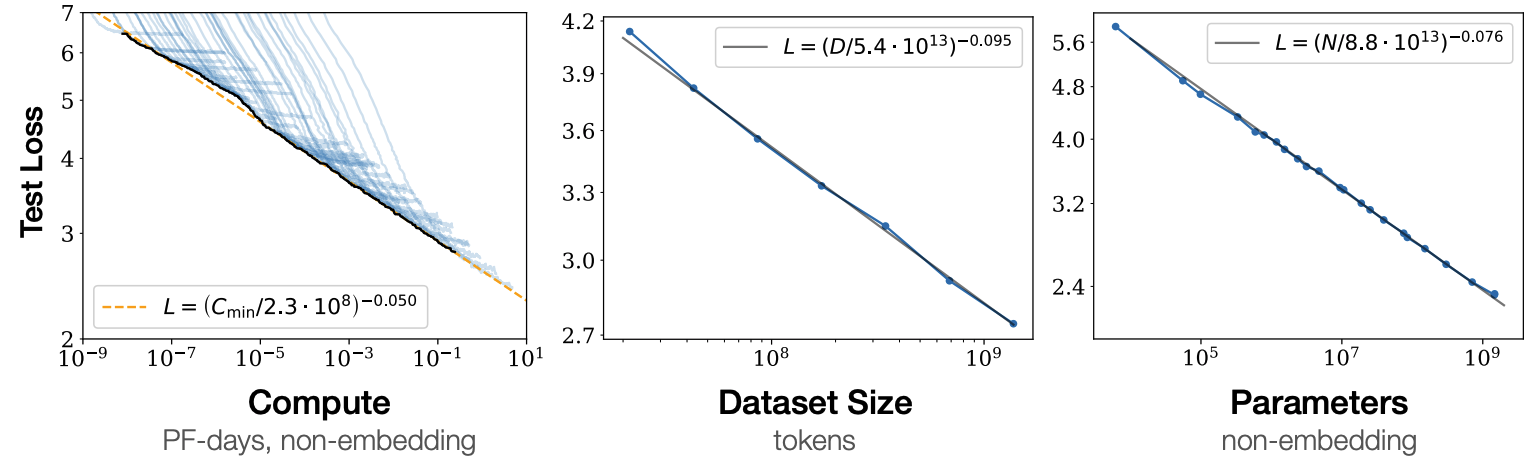
在大语言模型(Large Language Model, LLM)中,存在所谓的尺度扩展规律(Scaling Laws) [2],如Fig 1所示,即是:
LLM的性能会随着模型的参数量、模型的训练量、模型的训练数据量的增加而增加
然而,也有一系列工作告诉我们,在保持LLM不变的情况下,在推理时增加计算量,如以下方法,可以有效地提高模型效果
- 增加并行搜索计算量 :模型采样多个答案(有多种采样方法,Best-of-N、Beam Search、Lookahead Search等),通过奖励模型从中挑选一个最佳答案。
- 增加串行修改计算量 :模型给出一个初始答案,然后基于这个初始答案进行修正,以此类推直到得到一个最佳答案未知。
第一种方法也可以称之为是通过并行搜索(Search)的方法,第二种则是串行修正模型的输出Token概率分布的方法,文章中提到这两种不同方法,适用于不同的问题类型。那么对于一个特定的问题,在给定了有限计算预算的前提下,应该如何分配预训练计算量、推理时计算量呢?这两种计算量是否可以相互兑换呢(Exchange)?这正是本文想要讨论的,如何分配计算预算,特别是聚焦在如何分配推理时的计算预算。
如公式(1)所示,用
整个实验是在数据数据集MATH [3] 基准上进行的,其中包含了不同难度的高中级别数学问题,所有的实验中都采用分割出的12k个数据进行训练,500个数据进行测试。本文采用的Verifier(用于给答案打分,判断答案的好坏程度)是PRM(Process Reward Model),其能够对结构化答案中每一个步骤进行打分,如Fig 2所示,比起ORM(Output Reward Model)只对整个答案粒度进行打分,是一种更为细粒度的建模方式,具体可见 [4]。本文采用的PRM的具体训练方法请参考原论文 [1],本博文不做详细介绍。

基于并行搜索的方法
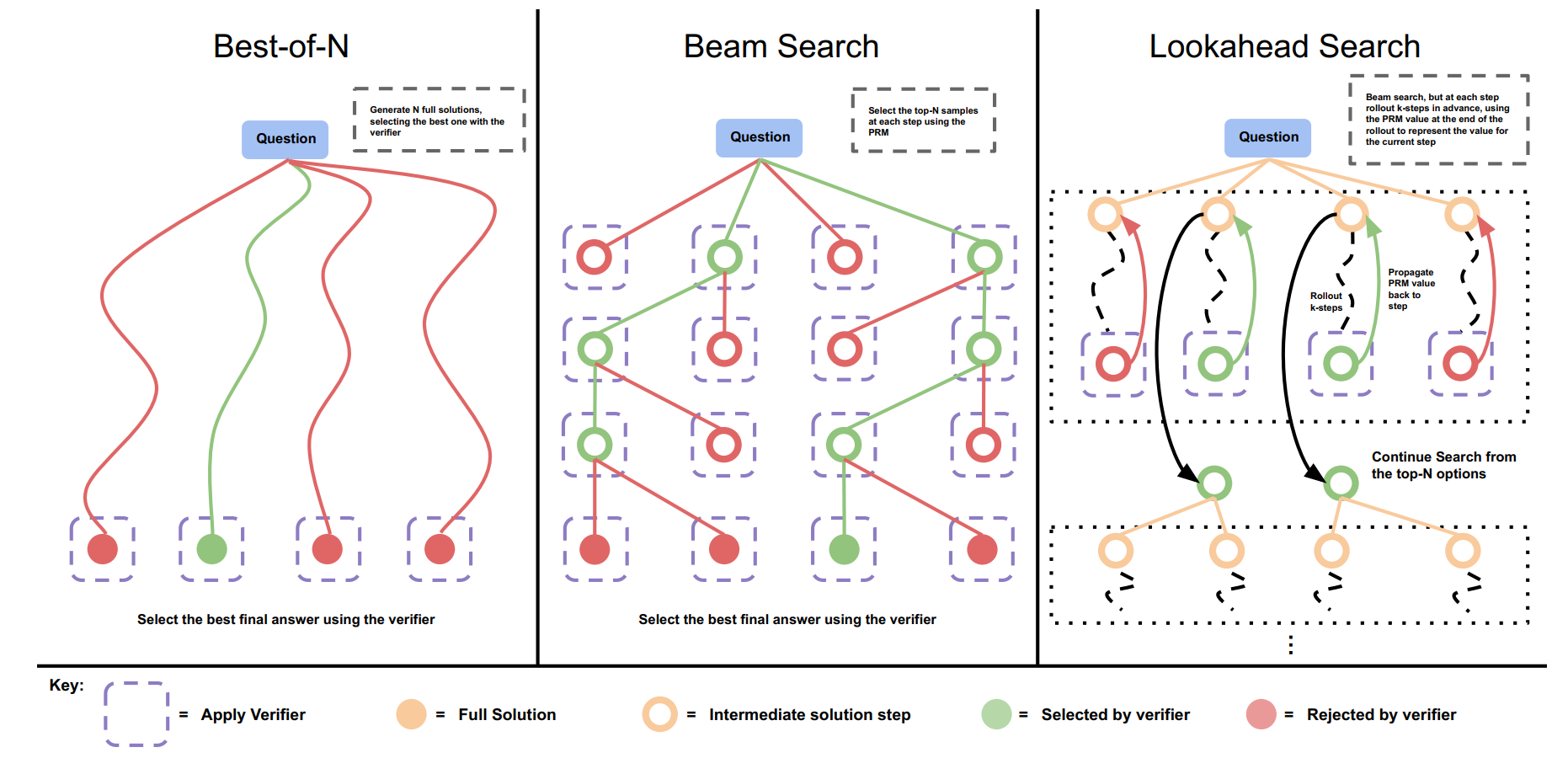
我们先来看到基于并行搜索的方法,本文探索了如Fig 3所示的几种搜索方法:
最佳N选1(Best-of-N):对问题进行多次采样,得到
个完整的回答,然后对所有采样得到的答案过一遍PRM判断答案的质量,然后将PRM打分最高的答案保留作为最终答案。考虑到我们的测试数据集是数学问题,可以认为是有明确的数字答案的,因此本文采用的是加权最佳N选1(Best-of-N Weighted)策略。不难看出,最佳N选1的计算预算即是 。 束搜索(Beam Search):一个问题的回答可以分为多个步骤(Step),在给定了固定数量的束数(The number of beams)
和束宽(beam width) 后,如Fig 3的中图所示: - 第一步:
时刻,首先采样 个答案步骤作为初始化。 - 第二步:对于这
个步骤进行PRM打分,保留其打分排序前 的步骤。 - 第三步:
时刻,对于这 个步骤,每一个继续采样 个步骤,这样我们 时刻就有了 个答案步骤,和初始化时候的数量一样。 - 第四步:
时刻,重复第二步到第四步。
不难发现,束搜索的每一步采样我们都固定采用
个答案步骤,因此最终计算预算和最佳N选1是类似的,都是 。 - 第一步:
前瞻搜索(Lookahead Search):是束搜索的『升级版』,每一轮采样都采样
步前瞻(在束搜索中 ),然后在通过RPM判断保留哪些采样轨迹,不难看出前瞻搜索的计算量通常都比较大,通常记作 。
让我们来看到试验结果,束搜索和前瞻搜索都有推理超参数需要选择:
- 束搜索:其束宽
需要设定,本文采用了两种设定 和固定的 。 - 前瞻搜索:其前瞻
和束宽 需要设定,本文采用了三种设定:
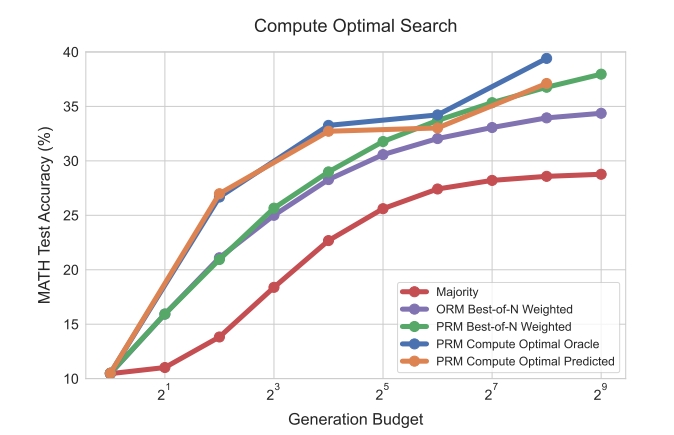
整个试验结果如Fig 4所示,从左图可以发现,在计算预算短缺的情况下,束搜索明显表现最佳,然而当预算增长到
然而在困难问题上(问题难度3以上),我们发现几乎在所有预算下,都是束搜索策略的表现明显最好,在最难的问题(难度5)上,甚至只有束搜索还能产生有意义的结果。这个结论是很符合直观印象的,对于简单问题,模型一次性产生正确答案的几率比较高,因此通过最优N选1或者多数投票的策略都能获得很不错的效果,但是遇到困难问题的时候,一个复杂问题通常会有着多个复杂的步骤,祈求模型一次性产生正确答案的几率就很低了,束搜索能够以每一步中最正确的步骤作为种子继续搜索,因此解决复杂问题的能力就更强,当然这也需要更多的算力预算了。

从上面的实验中,我们发现不同难度的问题需要不同的搜索策略,并且对计算预算的需求也不同,那么从以上试验得到的“计算最优测试时计算分配设置”(Compute-optimal test-time compute strategy)对比基线效果究竟有多大的优势呢?从Fig 5中我们发现,几乎在所有预算下,都是计算最优策略的效果显著最佳,并且对比
总的来说,我们有以下结论,直接拿走不谢。
我们发现,任何给定验证器搜索方法的有效性在很大程度上取决于计算预算和具体问题。具体而言,束搜索在处理较难问题以及在较低计算预算下更为有效,而最佳 N 选一方法在处理较易问题以及在较高预算下则更为有效。此外,通过针对特定问题难度和测试时计算预算选择最佳搜索设置,我们几乎可以使用少至 4 倍的测试时计算量来超越最佳 N 选一方法。
基于串行修正的方法
以上是基于并行搜索的测试时提升方法,还有一系列的工作是基于串行修正的,做法也非常直观,让LLM去修改自己之前生成的答案,期望能将之前答案的错误部分修正,然后进行多次迭代直到获得最终的正确答案,这个过程如Fig 6左图的"Sequential Revisions"所示。基于现有的LLM,通过简单的prompt去修正自己的错误答案在推理型任务中被认为是低效的,因此需要微调出一个修正模型(Revision model),这个过程在本文就不介绍了,有兴趣的读者请自行翻阅原论文。
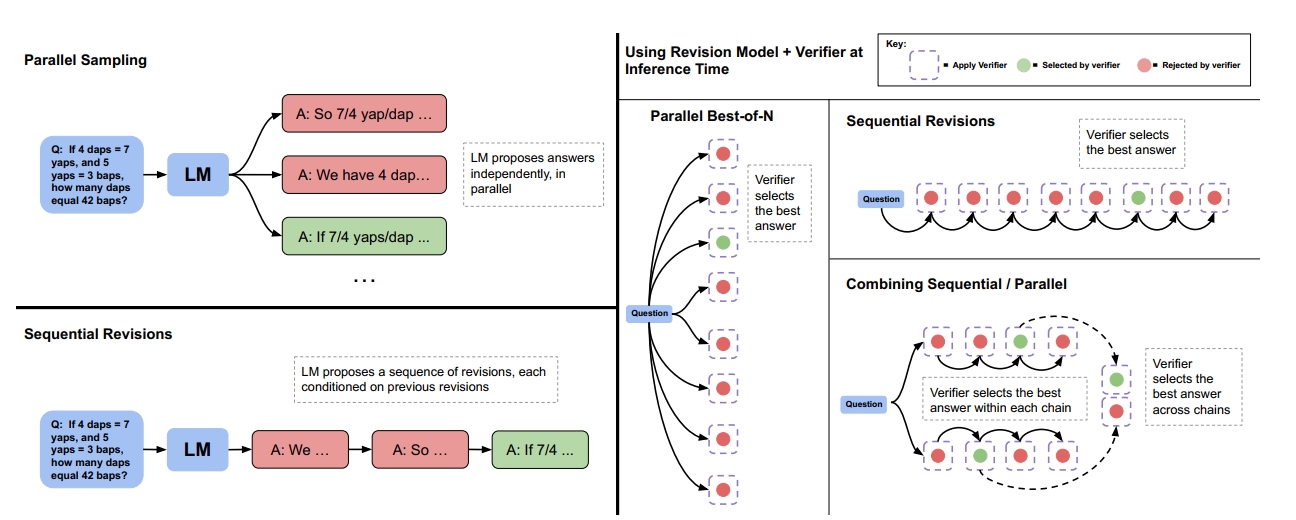
虽然这个能够修正自己错误的LLM是至多基于前4个答案进行修正训练的,在测试时候却可以生成长度更长的修改链(很简单,只需要保留最近的4次修正答案作为模型的上文就行了,之前的修正答案可以截断掉),如Fig 7左图所示,尝试更多次的修正能够获得更好的pass@1指标。在给定了
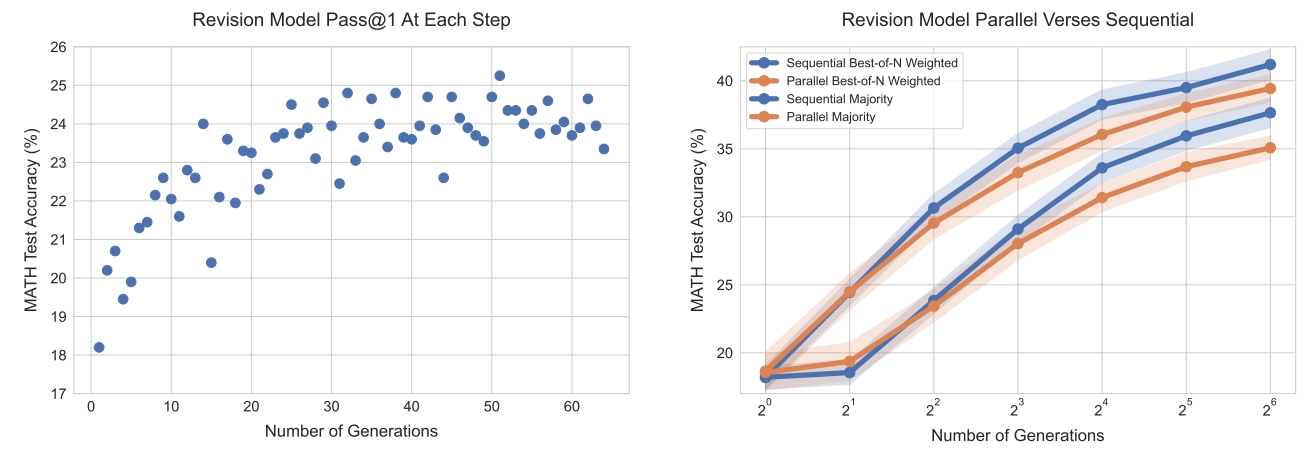
我们现在有串行修正和并行搜索两大类方法可以使用计算预算
我们再看到不同难度问题下,预算分配的规律。如Fig 8右图所示,在简单问题下,提高串行修正计算预算比例总是能带来性能增长,然而在较难问题上,则需要一个合适的比例,意味着需要引入一定量的并行搜索才能得到更好的性能。这个现象也能解释我们之前的结论,简单问题就算LLM不能一次性给出完整的正确答案,但是能给出基本正确的答案,只需要少量的串行修正就能得到完全正确答案。但是较复杂的问题LLM很难一次性就给出基本正确的答案,而是需要多次搜索后才能找到基本正确的答案,因此需要引入串行搜索的计算。
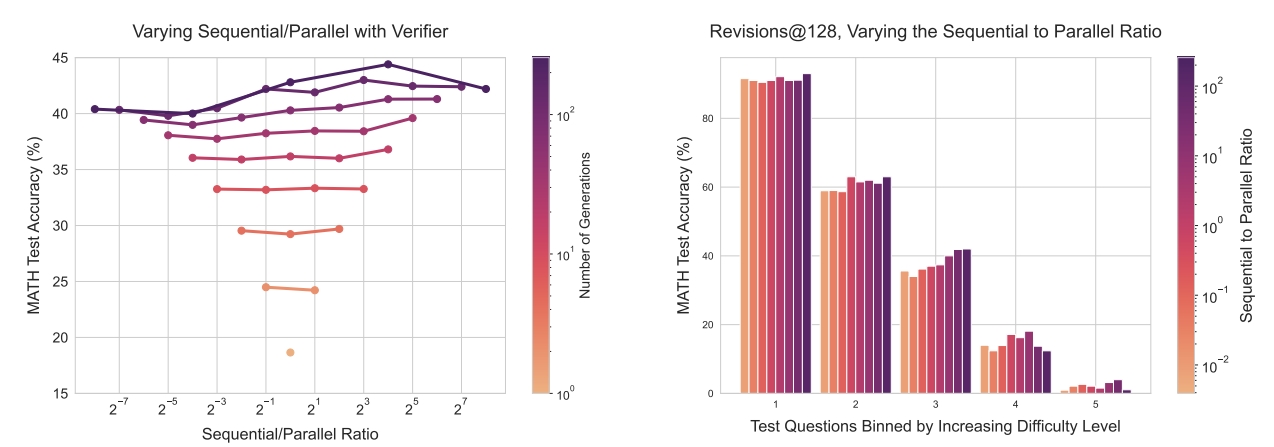
作者验证了在考虑了串行和并行的最优计算预算分配下,对于单独并行计算的优势,结果是能够以纯并行计算25%的预算达到相同的模型效果,具体结果就不展开了。总结以上的试验,我们有结论如下,拿走不谢。
我们发现,在串行(例如修订)和并行(例如标准的最佳 N 选一)测试时计算之间存在一种权衡,并且串行与并行测试时计算的理想比例在很大程度上取决于计算预算和具体问题。具体而言,较简单的问题从纯串行的测试时计算中受益,而较难的问题通常在串行与并行计算达到某个理想比例时表现最佳。此外,通过针对给定问题难度和测试时计算预算最优地选择最佳设置,我们能够使用少至 4 倍的测试时计算量来超越并行的最佳 N 选一基线。
以上的试验让我们看到了,在测试阶段进行复杂推理策略带来的模型性能提升,我们不可避免有一个疑问:增加测试阶段的计算预算,是否能替代预训练阶段的计算预算呢?也就是是否能通过复杂的测试策略,从而在减少模型预训练的情况下,提升模型性能。作者最后在本文也进行了试验,不过我们就不继续详细讨论了,作者的结论是:
测试时计算与预训练计算并非一对一“可互换”。对于模型能力范围内的简单和中等难度问题,或者在推理(实时性)要求较低的情况下,测试时计算可以轻松弥补额外的预训练。然而,对于超出基础模型能力范围的具有挑战性的问题,或者在推理(实时性)要求较高的情况下,预训练可能更有效于提升性能。
笔者读后感:
无论是学术界还是工业界,测试时尺度扩展都是当前的研究热点,这篇论文的信息量很大,作者做了很多有价值的试验,去验证扩展不同测试策略的计算量带来的性能提升,笔者将其理解为LLM测试时的scaling law,同时也探索了预训练阶段和测试阶段的scaling law,并且说明了预训练在困难问题下是具有不可替代性的。不过本文的试验都是在数学类的问题上进行试验的,结论是否可以泛化到其他问题(比如问答类问题、代码型问题等等),是一个值得继续探索的开放研究问题。同时,作者本文的试验没有考虑交织训练和测试,也就是复杂推理策略输出的答案,可以回馈LLM进行进一步的训练从而提升模型效果。这些都是可以进一步探索的工作。
Reference
[1]. Snell, Charlie, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. "Scaling llm test-time compute optimally can be more effective than scaling model parameters." arXiv preprint arXiv:2408.03314 (2024).
[2]. Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
[3]. Hendrycks, Dan, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. "Measuring mathematical problem solving with the math dataset." arXiv preprint arXiv:2103.03874 (2021). aka MATH
[4]. Lightman, Hunter, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. "Let's verify step by step." arXiv preprint arXiv:2305.20050 (2023).