BoNBoN结合了行为模仿和偏好对齐,在模型的Best-of-N结果基础上进行对齐...
前言
这次笔者想要介绍的论文,其结合了行为模仿和偏好对齐,在模型的Best-of-N结果基础上进行对齐,具有一定的启发性。论文中有不少公式推导,笔者将会考虑行文整体流畅情况下,酌情引用。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键词:行为模仿、偏好对齐、Best-of-N
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店

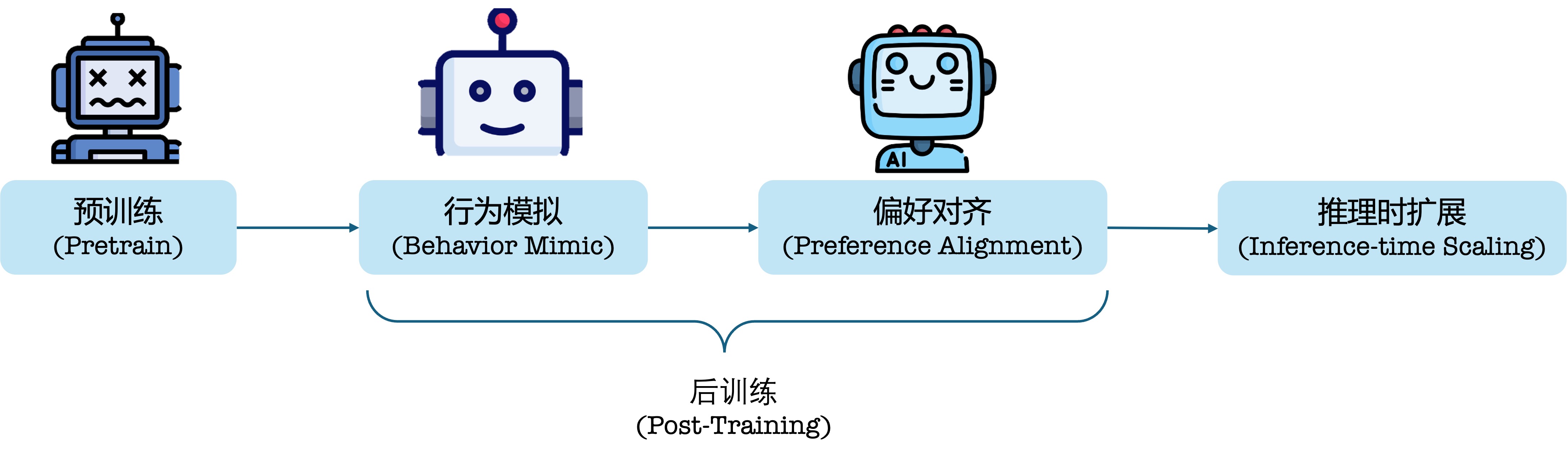
典型的大模型管道可以分为如Fig 1所示的几部分,其中的行为模拟(Behavior Mimic)通常是通过指令微调(Supervised Fintune, SFT)的方式,使得模型可以从预训练后的续写模型,变为一个可以遵循用户指令进行回答的模型,通过偏好对齐(Preference Alignment)能够使得回答更具有人类偏好。存在不少工作认为行为模拟只是对模型回答的格式进行规范,是一种偏向于『记忆(Memorize)』的过程 [2,3],而偏好对齐才是能进一步提高模型泛化能力的关键 [3]。至于说到推理时扩展(Inference-time Scaling),则是考虑在推理阶段采用复杂的答案采样/答案改写方式,提升模型的最终性能,可参考笔者在博文 [4] 中的介绍。
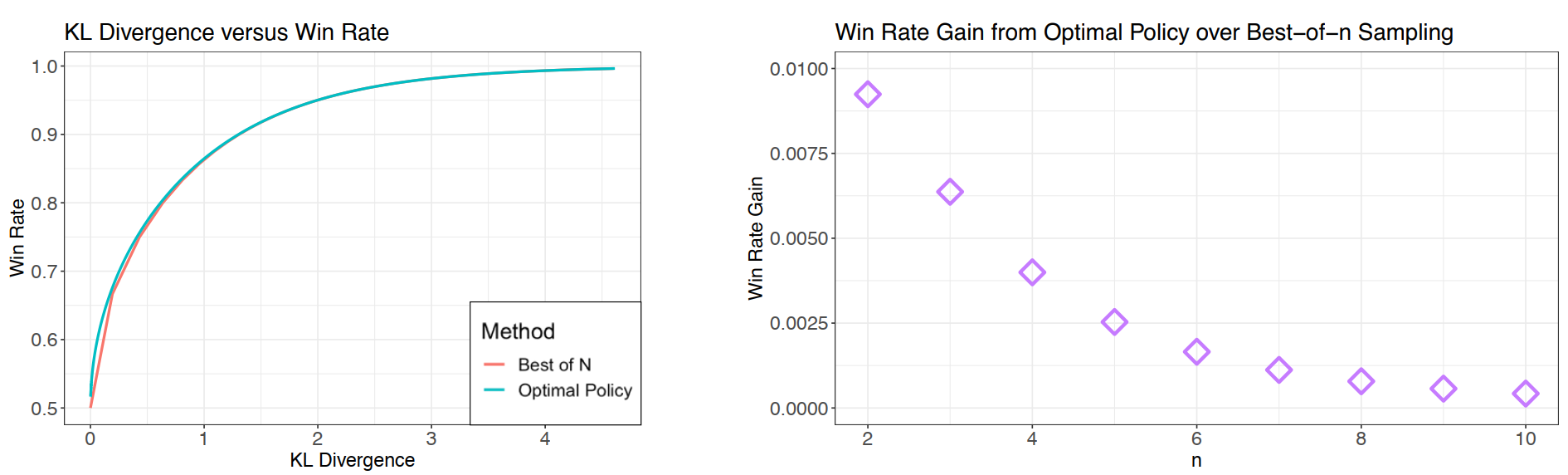
Best-of-N (下文简称BoN)采样是推理时扩展的一种经典做法,指的是给定一个提示词
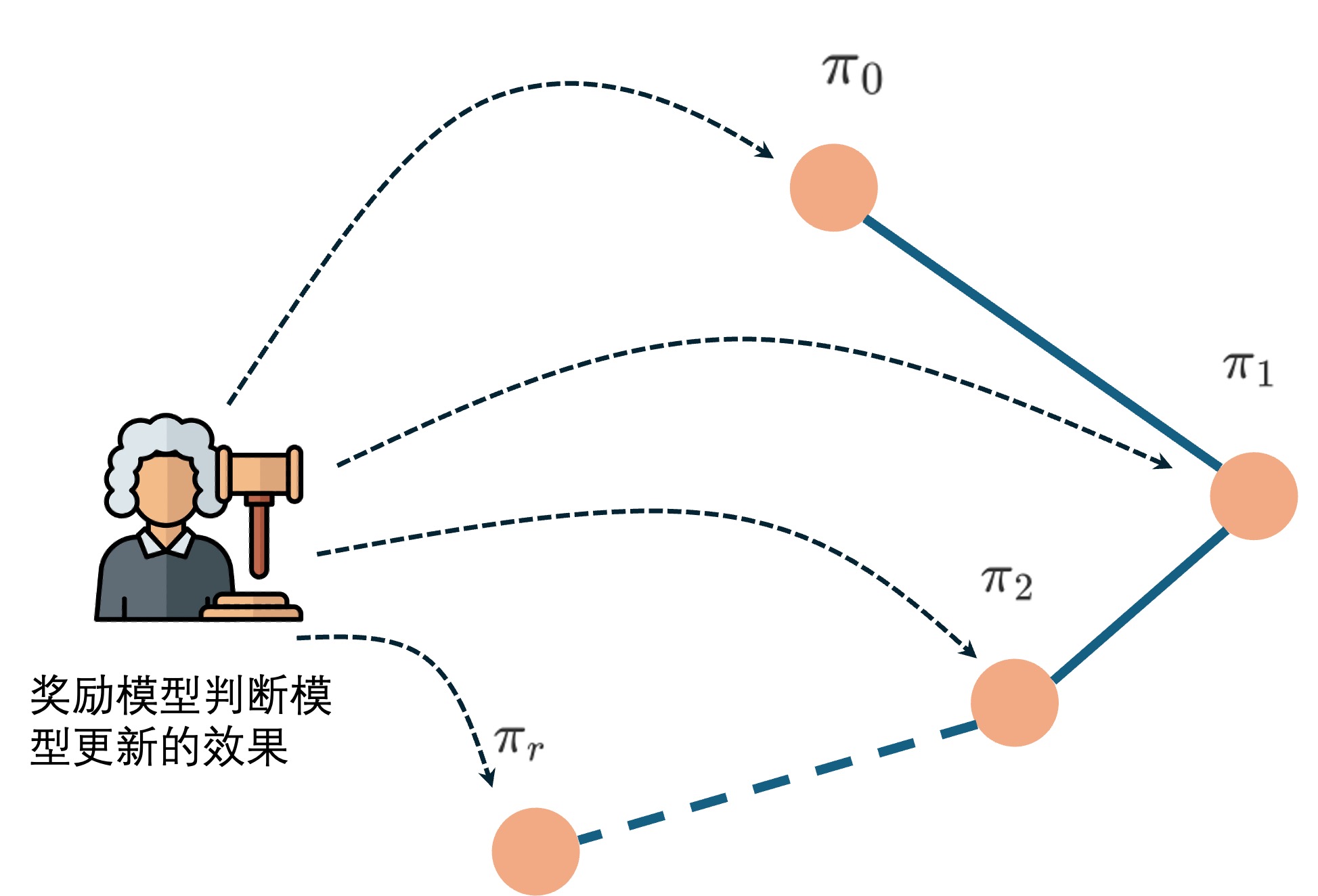
首先我们看到偏好对齐,偏好对齐的目标是对于一个SFT后的模型,称之为
- 如果不在训练过程中对此进行约束,新策略可能会容易出现大幅度偏离初始策略,导致整个训练过程不稳定且难以控制。
- 奖励模型通常是在初始策略模型的基础上,采样后进行人工标注样本训练得到的,也就是说如果新策略模型太过于远离初始策略模型,那么很可能会出现奖励模型无法很好地衡量新策略模型效果的情况,从而导致过拟合。
偏好对齐的方法整体有两种,第一个通过人工反馈的强化学习方法(RLHF),如公式(4)所述;
那么问题来了,如何将模型的BoN的结果蒸馏到模型自身上呢?本文提出了BoNBoN方式,损失函数如公式(13)所示
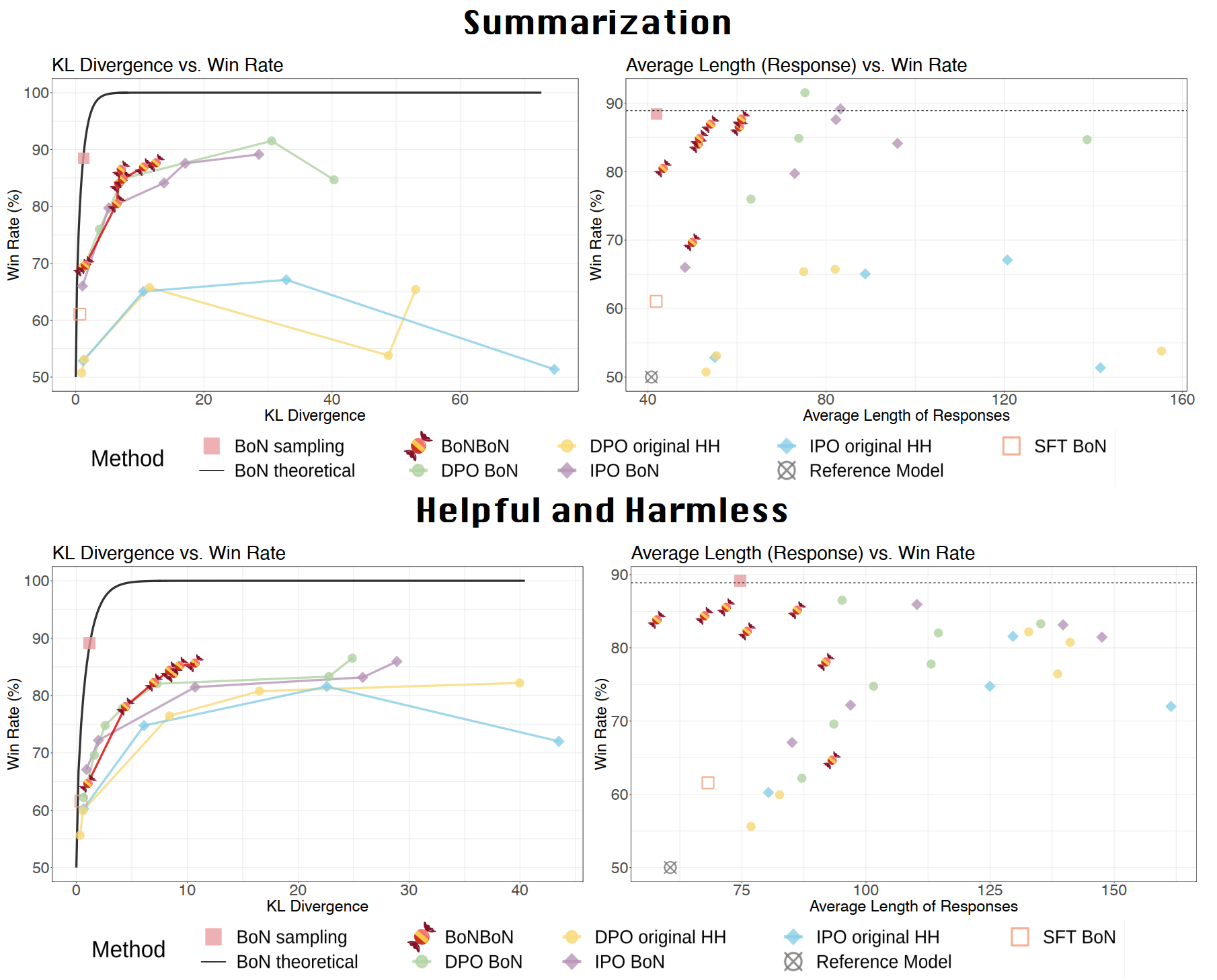
- 胜率越高,说明相比初始策略模型效果更好
- 越接近Reference Model(无论是KL散度还是平均响应长度),说明消耗的KL距离越少,则是更占优势(笔者认为是胜率计算更加准确)
从这个分析角度看,我们发现BoNBoN方法在消耗更少KL距离(或者和初始策略模型更加接近长度的平均响应长度)的情况下,能取得更高的胜率。此外,我们看到DPO BoN 效果持续远远优于DPO original HH,后者是采用HH数据(也就是所谓的off-policy的数据),而前者则来自于模型自身的BoN结果组建偏序数据,也就是所谓的on-policy数据。从这个结果,我们得到一个结论是,应当尽可能采用on-policy数据进行模型偏好对齐,即便这些结果可能相对来说比较弱(对比其他更好的模型采样或者标注)。
读后感
笔者看完这篇文章后,第一感觉就是公式好多... 其实整个蒸馏BoN结果的思路很直接,就是在SFT的基础上添加了一个DPO类的损失(或者反过来说,在DPO偏好对齐的基础上加了一个SFT行为模仿),其实整篇文章很多篇幅在证明BoN是KL约束下的渐进最优策略,然后想办法去接近BoN。因此我总结从这篇文章得到的收获的话:
- BoN是LLM的KL约束限制下的渐进最优策略
- 新策略模型可以表示为初始策略模型的分布加权
- on-policy vs off-policy 数据作为偏好对齐,应当尽可能采用前者
- SFT+DPO类损失能够更加充分利用数据
Reference
[1]. Gui, Lin, Cristina Gârbacea, and Victor Veitch. "Bonbon alignment for large language models and the sweetness of best-of-n sampling." arXiv preprint arXiv:2406.00832 (2024). aka BoNBoN
[2]. Zhou, Chunting, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma et al. "Lima: Less is more for alignment." Advances in Neural Information Processing Systems 36 (2023): 55006-55021. aka LIMA
[3]. Chu, Tianzhe, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, and Yi Ma. "Sft memorizes, rl generalizes: A comparative study of foundation model post-training." arXiv preprint arXiv:2501.17161 (2025).
[4]. 《大模型推理时的尺度扩展定律》, https://fesianxu.github.io/2025/03/02/test-time-scaling-laws-20250302/
[5]. Yang, Joy Qiping, Salman Salamatian, Ziteng Sun, Ananda Theertha Suresh, and Ahmad Beirami. "Asymptotics of language model alignment." In 2024 IEEE International Symposium on Information Theory (ISIT), pp. 2027-2032. IEEE, 2024.
[6]. 《奖励模型中的尺度扩展定律和奖励劫持》, https://fesianxu.github.io/2025/02/09/scaling-law-in-reward-model-20250209/