不同于传统的属性语义相似度,关系视觉相似尝试度量图片之间的关系逻辑上的相似度...
前言
最近看到Adobe发的一篇文章,提出了一种新的衡量视觉相似度的方法,作者称之为关系视觉相似度(Relational Visual Similarity, relsim) [1] ,与传统的属性视觉相似度不同,relsim用于度量图片之间的『关系逻辑上的相似程度』,笔者简单进行笔记之,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键词:关系视觉相似度、视觉间逻辑相似度、VLM
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
github page: https://fesianxu.github.io/
微信公众号:机器学习杂货铺3号店

问题背景
衡量两张图片之间的相似度,这个技术具有广泛的应用场景,对于一般终端用户而言,最常见的便是各类型的以图搜图应用。常用于衡量图片之间相似度的方法是语义相似度(Semantic Visual Similarity),特别是基于属性(比如颜色、形状等)、内容实体(比如物体类别)的图片相似度衡量,这点符合直观认识,我们通常认为图片中实体、属性相近的图片(比如都出现了带墨镜的猫)是相似的。这一点可以见笔者在博文 《视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望》[2] 中对各类型视觉语义匹配模型的介绍,我们会发现这些模型在训练/验证数据构建之初,就是以实体、属性为中心构建的,比如ImageNet 1k中的 1000 个类别就是根据 WordNet层次结构组织的,涵盖了广泛的物体,包括各种动物、日常物品、交通工具、食物乐器植物等等,再看到CLIP的训练数据构建过程,直接引用我在博文 [2] 中的描述:
(CLIP的)作者在英语维基百科上采集了50万个基础词,这些词都是出现过起码100次的高频词汇,同时在互联网尽可能地采集了大量的图文对数据,通过判断文本中的词汇是否在这50万基础词中进行数据的筛选,同时进行了数据的平衡,使得每个基础词上大概有2万个图文对。最终收集得到了4亿个图文对。我们不难发现这个过程由于对基础词的频次进行了筛选,因此都是一些高频的视觉概念才得以收集。
不难发现,CLIP训练数据的视觉概念也是高频的实体、属性概念,同时也可能伴随有部分视觉关系,如Fig 1.所示。

因此,以属性、实体、视觉表层关系为代表的视觉概念为中心构建出来的训练数据,训出来的模型必然也会以这些视觉概念作为相似度度量目标。但有一类更为抽象的相似关系,以图像中元素的逻辑关联去衡量图片之间的相似关系,目前这些相似度度量无法很好的建模,如Fig 2.所示,通常我们认为组B图片和参考图片是相似的,因为图片中的主要实体是一致的,而组A图片则第一眼很难发现其和参考图片之间的相似关系。其实从更抽象的角度看,组A图片可以认为是参考图片的『类比』版本,虽然图中实体不同,但是在构图逻辑中这些不同实体之间,以相似的逻辑连接在一起。这种视觉的构图逻辑相似性,目前还没法很好描述。

关系视觉相似度
本博文讨论的工作 relsim [1] 就是考虑建模组A图片和参考图片的这种构图逻辑关系相似度。显然,根据以上的讨论,现存的公开训练数据无法直接拿来用,建模第一步还得从构建具有构图逻辑相似的<图片, 描述>数据对入手。首先,并不是所有图片构图都具有有意义的逻辑关系,如Fig 3.所示,从LAION数据集中随机采样的图片(比如自拍、风景画、写真等)都无特别的逻辑关系,而更可能具有美学的含义,而一些『有趣』的抽象图片,则更可能存在有趣的内在逻辑关系,比如隐喻、内涵、讽刺等。注意到这种内在逻辑关系,很多时候是实体无关的,也就是图中的实体之间做出某种有特殊含义的互动,并不一定和这种特定实体强绑定,换一个新的实体可能也是同样成立的。作者将这种对图中实体无关,着重于图中构图逻辑的描述,称之为『匿名描述(anonymous caption)』。

我们先看作者是怎么筛选出这些『有趣』图片的,首先需要构建一个种子集合,作者从LAION-2B数据中,手动标注了两类样本,标注者的判断标准是:“该图像中是否存在可用于创作或关联其他图像的关系模式、逻辑或结构?”:
- 正样本(1.3k 张):人工判定为 “具有关系结构 / 逻辑” 的图像,如讽刺、暗喻、类比等创作,标注标签为 “Yes”;
- 负样本(11k 张):无深层逻辑关系的普通图像,如风景画、写真、自拍等,标注标签为 “No”。
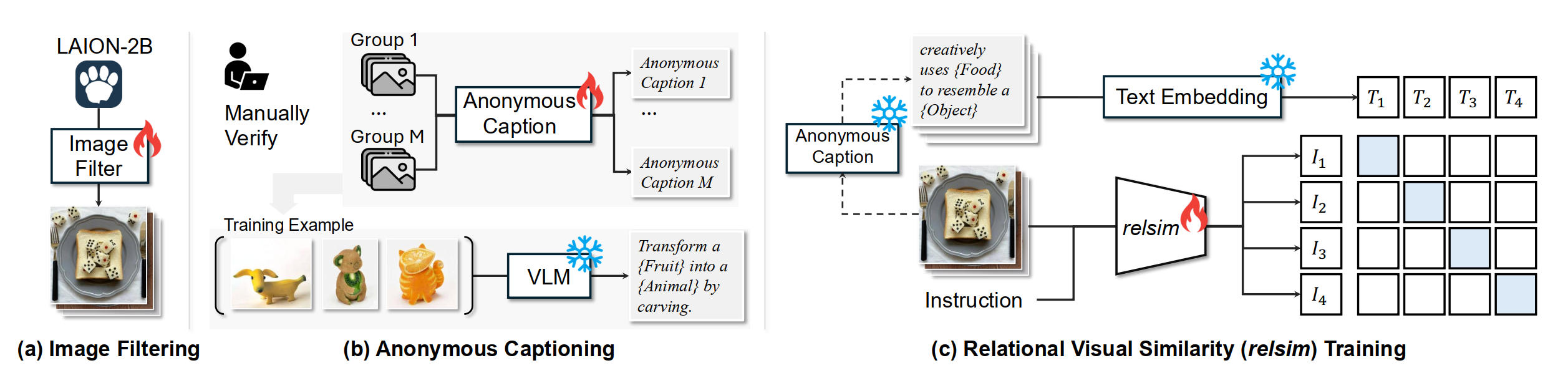
随后采用Qwen2.5-VL-7B作为基础模型,通过 LoRA微调一个二元分类器,微调后的模型与人类判断的一致性达到 93%,确保筛选标准的准确性。将训练好的筛选模型应用于海量的 LAION-2B 数据集,批量识别 “interesting images”,最终从 LAION-2B 中筛选出 114k 张图像,如Fig 4. (a)所示。这些筛选后的图像将用于后续 “匿名描述生成” 和 “关系相似度模型(relsim)” 的训练。
有了以上对匿名描述的介绍,作者认为两张图片的关系视觉相似度
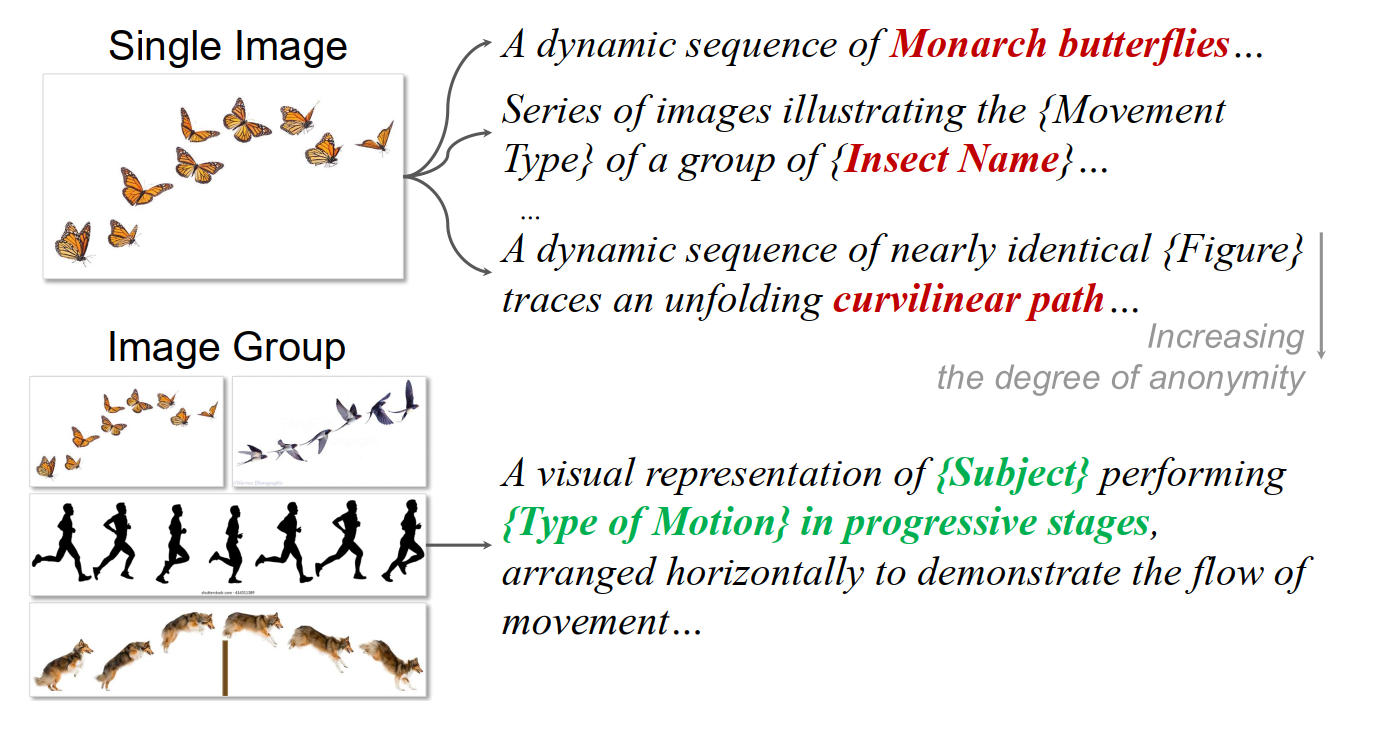
为何是以图片组(Image group)的形式标注,而不是单张图片(Single Image)去标注呢?作者举了一个例子,注意到Fig 5,单一图像难以明确区分 “表面细节” 和 “底层关系逻辑”(例如仅看蝴蝶飞行序列图,无法确定逻辑关系的核心是 “运动模式” 还是 “昆虫类型”)。而将具有相同关系逻辑的图像归为一组后,共享的关系结构会更突出,便于生成通用、可迁移的匿名描述,从而避免绑定具体物体属性。因此在标注时候,作者手动筛选并筛选得到了532 个图像组,记为M=532,每个组满足以下条件:
- 组内所有图像有相同的底层关系逻辑(例如 “用食物模拟物体”,“时间维度的渐变过程”,“通过排版实现视觉双关”)。
- 每组图像数量为 2-10 张(确保组内逻辑一致性,同时覆盖足够多样的视觉实例),如Fig 5中所示的图片组为单位,标注匿名描述。
- 这些组作为 “种子数据”,基于Qwen2.5-VL-7B训练匿名描述生成模型,将匿名描述的能力泛化到其他未曾标注的『有趣』图片中,扩大数据规模。最终作者采集了114881条<图片组,匿名描述>数据对。
有了大量的<图片组,匿名描述>数据对后,固定住匿名描述的表达embedding,就可以采用对比学习的方法训练视觉编码器了,如Fig 4 (c) 所示,考虑到关系视觉相关性这个任务的高度抽象性(视觉编码器不光需要具有基础语义能力,还需要有一定程度的世界知识能力,才能学习出图片的更为高度的抽象表达)。作者采用了Qwen2.5-VL-7B作为基础骨干,在图像输入的末尾附加上一个可学习的查询令牌(learnable query token,可以参考prompt tuning [3]),作为 “关系特征提取的引导令牌”,将图像特征与该查询令牌将一同输入 Qwen2.5-VL-7B 的LLM部分,并且将LLM的最后一层中查询令牌的特征视为图像的关系视觉特征(relational visual feature),并且以此和文本特征做对比学习。作者也通过消融实验,验证了纯视觉编码器如CLIP、DINO等,即便采用相同的匿名描述数据集微调,其关系相似度捕捉能力仍远低于 VLM 骨干,正是由于纯视觉模型缺乏关系推理所需的世界知识,而这正是VLM的优势所在。
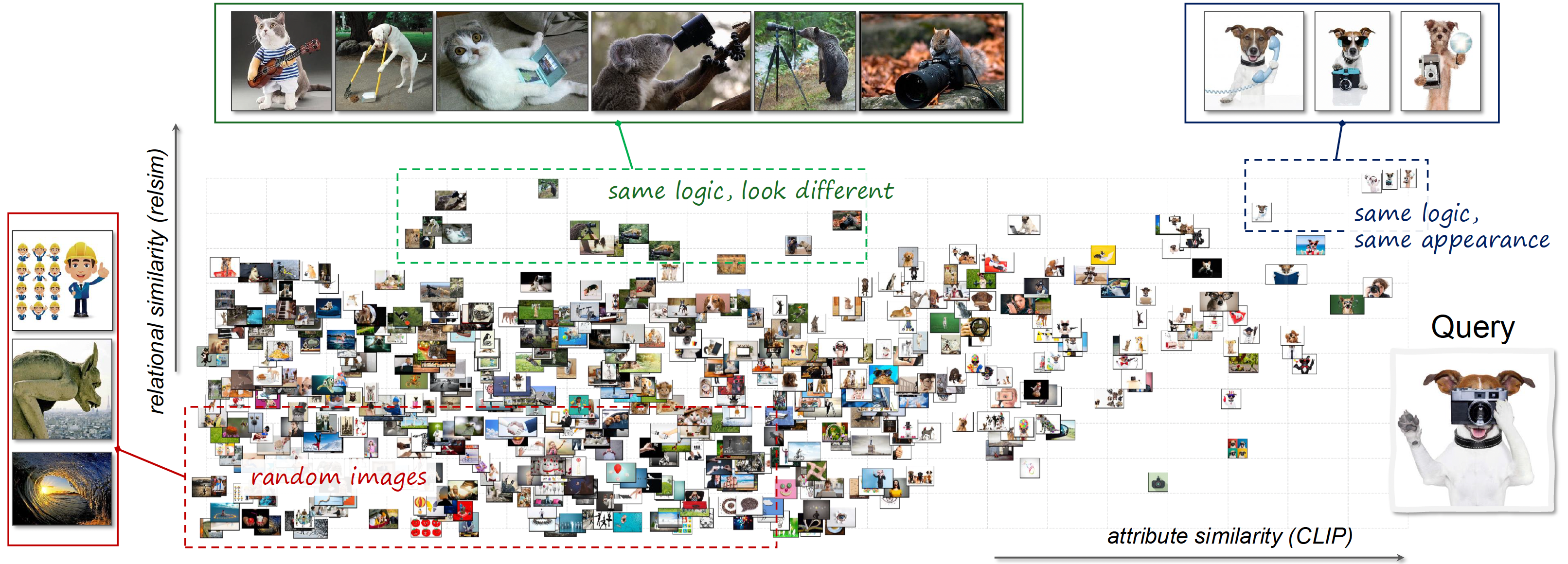
在效果验证方面,作者采用GPT+Prompt工程自动打分,人工双盲评估两种方式,均验证了在关系视觉相似度建模上,本文提出的方法对比传统视觉编码器(如CLIP、DINO、LPIPS、Qwen-T等)的优势,这里博文就不进行展示了。我们着重看下作者在论文中贴的一张图Fig 6, 对于一张query图像(狗子手持相机作为摄影师拍照),分别用关系相似度(relsim)和属性相似度(CLIP)检索出来的大量图片可以如图这样贴在坐标上,越往横轴坐标右侧靠就是和query图片外观越相近,但是构图逻辑上相关性较弱的图片(比如是简单的狗子和照相机的叠加,但是实体之间的逻辑关系和query图片不一致),越往纵轴坐标上侧靠,则是构图逻辑越接近query图片,而构图实体和query图片相差较大,比如熊拿着望远镜。右上角则是构图逻辑和构图实体都接近的图片。
作者同时也列举了关系视觉相似度可能的一些落地场景,包括直接相关的视觉关系以图搜图(搜索构图逻辑相似,而不是实体相似的图片),也包括类比图片生成(Analogical image generation),如Fig 7和Fig 8所示。


正如笔者曾在博文 [2] 提到过:「简单对图片的视觉元素进行感知是无法真正理解讽刺漫画的,这种高度抽象的延伸语义需要大量的历史、文化、生活背景知识支撑。」。对于一些具有复杂抽象内涵的图片,比如讽刺、暗喻、类比等,模型无法通过仅对图片的视觉元素进行感知,就能够实现理解,而需要结合世界知识(比如历史、文化、生活背景等,包括一些『梗』知识)。对于这类型的图片,传统视觉模型仅通过表层视觉元素感知难以实现深度理解,而 relsim 通过融合 VLM 的世界知识与关系推理能力,为这类图像的相似度度量提供了新的解决方案,比如relsim能够在一定程度上将一些『梗』的原图和延伸作品关联起来。笔者下载了作者公开的模型 [4],尝试了一些互联网梗图以及其延伸作品,如Fig 9所示,发现确实传统视觉编码器(笔者尝试的是clip-vit-large-patch14)效果要好不少,能够将梗的原图和Fig 9的延伸图关联起来。能够设想,既然梗图能和延伸图通过这种方式关联起来,对于讽刺、暗喻等笔者之前觉得的高度复杂抽象的图片,其完全理解的希望有更进一步了。同时,互联网上的这些讽刺、暗喻图片也可能会随着这个技术的成熟,变得更容易『挂掉』了 ,从某种意义上说是一种坏处了 ಥ_ಥ

Reference
[1]. Nguyen, Thao, Sicheng Mo, Krishna Kumar Singh, Yilin Wang, Jing Shi, Nicholas Kolkin, Eli Shechtman, Yong Jae Lee, and Yuheng Li. "Relational Visual Similarity." arXiv preprint arXiv:2512.07833 (2025). aka relsim
[2]. https://fesianxu.github.io/2023/03/04/story-of-multimodal-models-20230304/, 《视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望》
[3]. https://fesianxu.github.io/2023/09/28/prompt-tuning-20230928/, 《Prompt Tuning——一种高效的LLM模型下游任务适配方式》
[4]. https://huggingface.co/thaoshibe/relsim-qwenvl25-lora