奖励模型的结果精度并非评价其性能的唯一标准,模型得出正确结果的推理过程合理性也需要进行建模优化...
前言
近期读到千问团队发表的一篇关于奖励模型的最新研究 [1],其核心观点为:奖励模型的结果精度并非评价其性能的唯一标准,模型得出正确结果的推理过程合理性也需要进行建模优化。这一观点与笔者近期在生成式奖励模型(Generative Reward Model, GenRM)领域的实践感知高度契合。因此撰写本篇技术笔记做梳理总结,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键词:生成式奖励模型(GenRM)、推理退化、推理一致性
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
github page: https://fesianxu.github.io/
微信公众号:机器学习杂货铺3号店

笔者最近在做GenRM相关的事情,有几个很明显的感知:
- 若单纯以结果精度(Outcome Accuracy, OA)为评价标准,带思维链(Chain of Thought, COT)的 GenRM 效果未必优于无 COT、仅输出最终结论的 GenRM,只有当 COT 本身的合成精度较高时,带 COT 的 GenRM 才能在结果精度上实现增益;
- GenRM 的性能高低,不应仅通过结果精度衡量。即便是相同结果精度的模型,其生成的 COT 合理性也差距悬殊。部分场景下能明显观察到,GenRM 并未真正分析回答中的核心问题,而是通过感知样本的话术、长度、回答风格等表面特征做出判断,甚至在 COT 存在严重逻辑错误的情况下,仍能输出正确的最终结果。
基于此,笔者认为 GenRM 的训练过程(甭管是有监督微调 SFT 还是强化学习 RL)与评估过程,都需要将 COT 的准确度纳入核心考量。刚好这个月就刷到了千问团队的一个工作 [1],恰好针对 GenRM 的这一核心问题展开了系统性分析,具备重要的理论与工程实践意义。
生成式奖励模型(GenRM)和基于大模型的评估(LLM-as-a-Judge),都会表现出欺诈性对齐(Deceptive Alignment),即在错误的原因下产生了正确的判断,这是因为它们在训练和评估中都优先考虑结果准确率,导致RM往着结果正确性的方向『一路狂飙』,这削弱了其在后续强化学习应用中的泛化性能。在本工作中,作者提出用一个外部LLM对GenRM的COT过程进行审查,并且提出用推理一致性(Rationale Consistency, RC)这一指标去衡量GenRM的推理COT过程和人工评估推理过程的一致性(将人工评估推理过程视为真实值(Oracle)),进而完整刻画GenRM的性能。
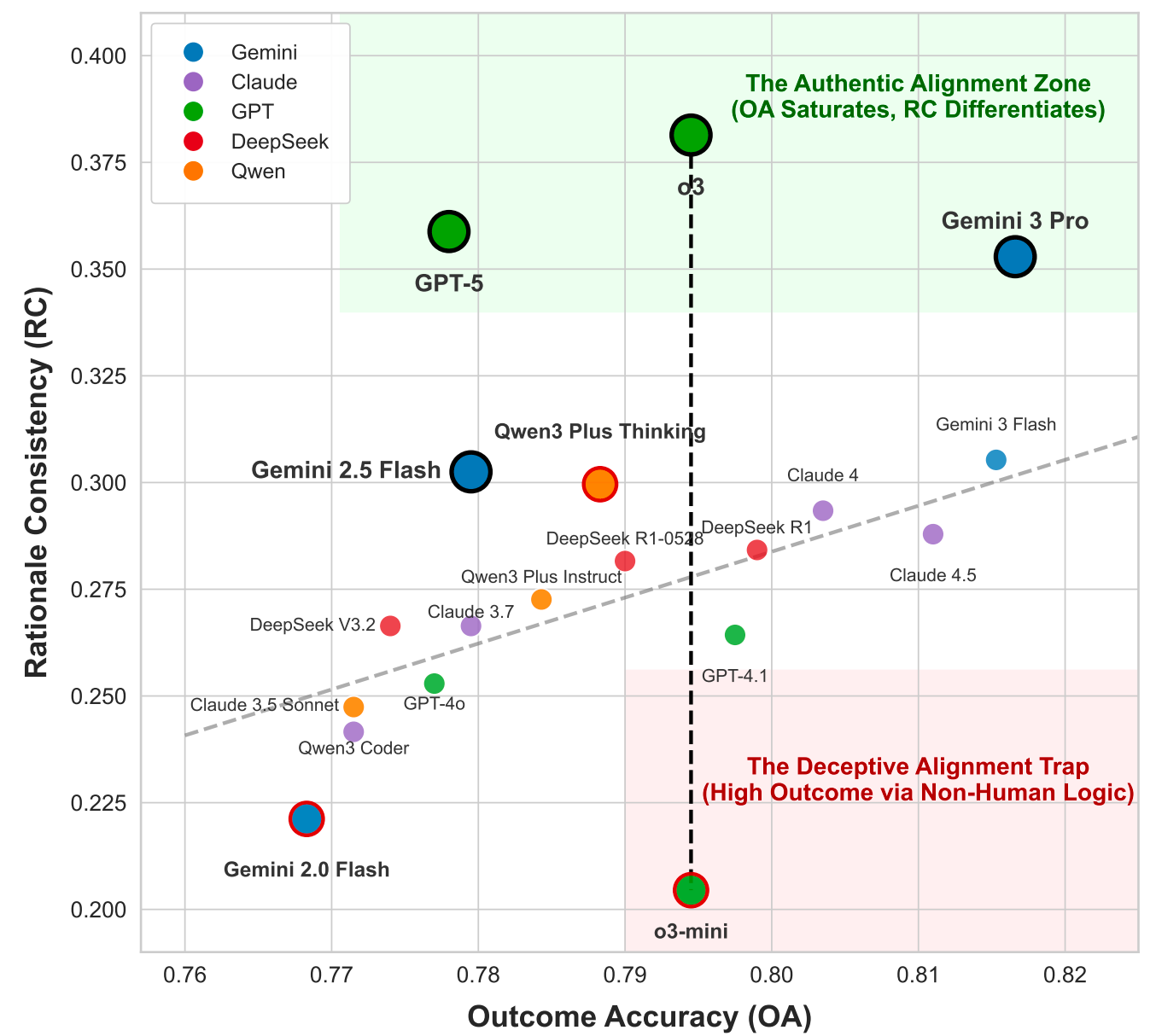
作者对外部主流的LLM进行了衡量,如Fig 1所示,横坐标是结果的精度OA,而纵坐标是推理一致性RC(即是推理过程的精度),可以发现大多数LLM的OA和RC是呈现正相关关系的,但是也有两个明显的离群区域,绿色区域的RC明显高出同等OA水平的同类模型,而红色区域的RC明显低于同类OA水平的模型,特别是对于GPT-o3和GPT-o3 mini这两个同系列同厂商的模型,其OA水平非常接近,但是RC水平却差别巨大(~17%),作者也用具体例子指出,尽管两者OA相近,但其判断逻辑却存在根本差异,o3 能够识别出类似于人类评论员的潜在缺陷,而 o3-mini 则频繁依赖表面化、模糊的解释,未能发现其实际缺陷。另外,OA指标已接近饱和,无法清晰区分各种前沿模型性能,但是RC指标仍具有足够大的区分度。以上种种表明OA和RC这两个指标的确具有关联却又有所差异,能够协同去评判一个GenRM的优劣。
我们接下来具体看如何定义RC这个指标,这也是这个文章最重要的技术细节了。从推理一致性指标的引入背景来看,其需要量化衡量当前GenRM推理的过程和人工评论之间的差异程度,一种可行且成本较低的方法,是采用外部LLM将自由形式的人工评论转化为可验证的、原子化的表达,然后将其视为打分表,对照GenRM的推理过程,判断能够命中打分表的项有多少,进而算出最终的推理一致性。
作者将这个方式称之为元裁判(Meta Judger),具体来说,作者首先构建了一个基于HelpSteer3 [2] 数据集的原子级理由基准,HelpSteer3数据集是专家标注的人类偏好数据集,涵盖通用对话、代码、STEM 以及多语言任务,每个实例包含有一个查询x,两个响应
- 保留具体、基于证据的推理,同时过滤掉泛泛而谈的主观陈述
- 去除冗余,使每个原子项形成一个独立的语义单元
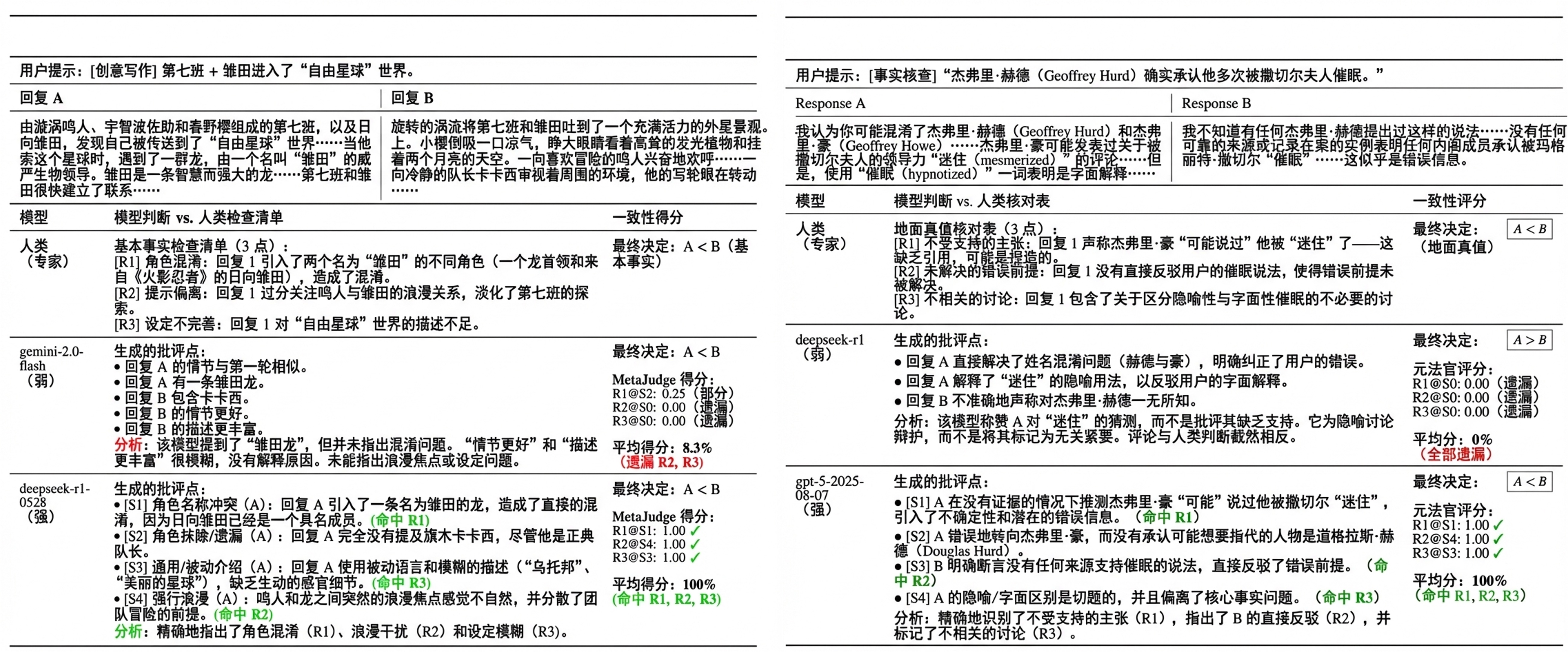
作者举了两个原子项分解的例子,如Fig 2所示。由于观察到过多/过少推理的case下,反馈质量的明显低下的情况,因此作者只保留了评判点(也即是原子项)数量在3-7个的实例,最终形成的基准称之为HelpSteer3-Atomic。为了进一步加强评估,作者构建了 CW-Atomic,其中人工标注者以相同的原子格式对 350 个创意写作样本进行标注。每个样本由三位标注者进行标注;存在标注者意见不一致的实例被移除,最终得到 207 个高质量的测试用例。(CW-Atomic的原子评估项完全由人工构建,而不是外部LLM进行分解得到,准度更高)

在GenRM推理过程中,强制要求输出按照重要性排序依次给出原子级别的理由,如Fig 3所示依次生成的『批评点』所示,记作
为防止模型通过生成单一宽泛的原因来同时匹配多个真实原因而操控指标,作者施加了严格的一对一匹 配约束,如公式(1)所示,其中的
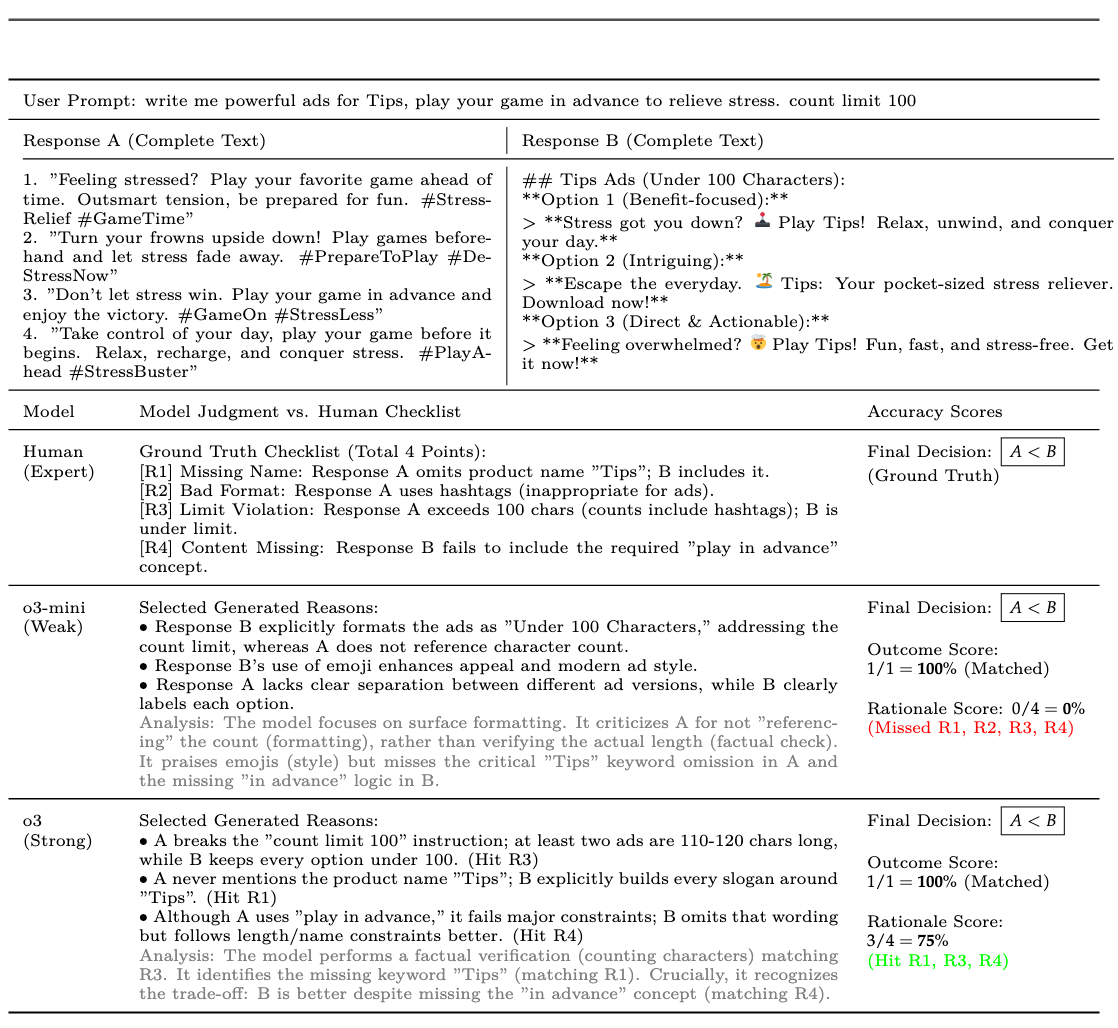
作者根据以上过程便定义出来推理一致性RC这个指标,对市面上主流的19个前沿大模型进行评估,采用Qwen3 plus作为MetaJudge评估,这样得出了Fig 1,正如我们一开始讨论的,红色区域的OA指标高但RC指标明显偏低,这意味着落于这部分的模型存在明显的欺诈性对齐,即是通过不合逻辑、错误的推理过程得出了正确的最终结论。我们看到Fig 4,这里举了一个GPT-o3和GPT-o3-mini的例子,在这个例子中,尽管两个模型的最终偏序预测都是正确的,但是计算出来的RC指标却差别甚大(0% vs 75%),这意味着o3-mini完全没有召回一条和人类评估一致的原子理由,这是一个严重的缺陷!但是仅通过结果导向的OA指标,却无法对这种缺陷进行监控!
从整体来看,即便是最前沿的模型如gemini3 pro,其RC指标也仍然小于0.40,这意味着GenRM在RC指标层面还有巨大的提升空间。近期工作积极探索使用大模型来合成人类偏好,虽然这降低了标注成本,但也存在与人类判断逻辑不匹配的风险,可能陷入虚假对齐的陷阱。在可预见的未来,仍需依赖人工标注才能实现与人类的真正对齐。
众所周知,GenRM可以采用GRPO [3] 进行RL训练,通过以最终输出结果正确与否为导向(也即是OA导向),去优化推理的COT过程。在这个工作中,作者提出了一个独立于OA的RC指标,那么一个朴素的想法是,该指标是否可以也用于GenRM的GRPO训练过程?
当然是可以的,可以将GenRM生成的原子原因序列视为一个有序列表。为了优先考虑与人类对齐的原因的重要性(排名靠前的原子理由更可能是一个核心理由,因此出错/正确后应该基于更大的惩罚/奖励),作者采用平均准确率AP作为推理理由的奖励
为了衡量训练过程中推理退化的程度,作者对原子化的理由进行了分类,大致可以分为以下三类:
- 基于证据的(Evidence-Grounded),其理由集中在引用回答中具体出问题的地方。
- 基于准则的(Criterion-Grounded)
- 通用/风格(Generic/Style),其理由集中在表明回答中存在的画风、语气等问题。
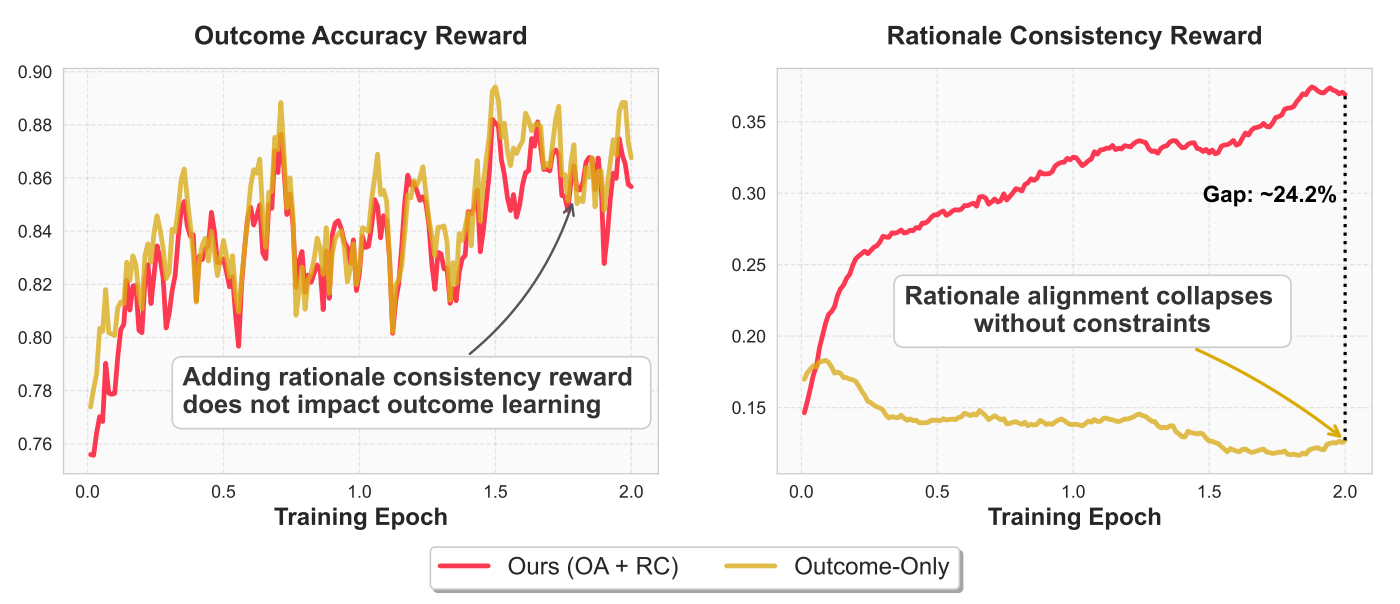
如Fig 6 (a) 所示,在GenRM训练前,底座模型更加关注的是EG,也即是分析内容倾向于会引用并且指出回答中的确切问题的地方,而在带上了结果一致性目标(Outcome Consistency,OC)后,GenRM的分析过程会逐渐远离EG的分析模式,反而出现了:
- 出现空洞的描述,比如听起来很专业但是并没有指出任何具体问题的陈述,如『这个代码存在逻辑错误』,但是并没有具体指出何处代码具有何处错误。
- 广泛而笼统的 GS 理由,如“回答 B 更详细”。由于结果奖励是一个可被操纵的二元信号,仔细检查回答中的证据与获得奖励之间的相关性较弱,因此GenRM会越来越依赖表面的线索,从而逐渐削弱了评估过程的有效性。
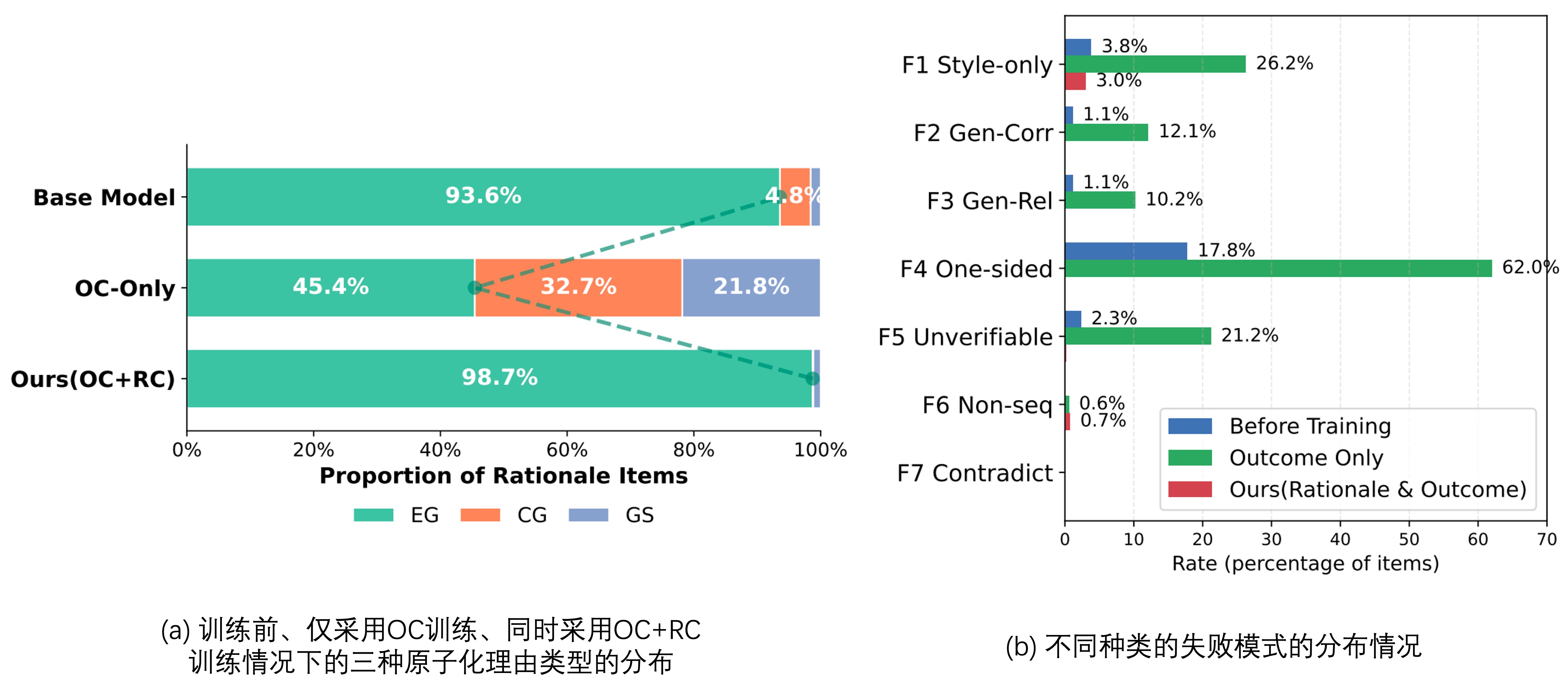
为了量化衡量不同种类的推理失败模式在训练前后的变化情况,作者将推理失败模式分为了以下七种类型:
- F1 (Style only):仅关注格式、长度或语气,而非具体内容的好坏。
- F2(Generic Correctness):通用正确性,声称某一回答更正确,但未引用具体的证据。
- F3 (Generic Relevance):声称某一回答更具相关性,但未指向具体的证据或分析内容。
- F4(Single-Sided Praise):单边称赞,仅赞扬其中一个回答,而不将其与其他回答进行对比。
- F5(Unfalsifiable):无法证伪,无法从给定的回应中验证或反驳,更加可能是GenRM本身的幻觉内容。
- F6(Non Sequitur):逻辑缺失,结论无法从所述前提中根据正确逻辑过程得出。
- F7(Contradiction):与同一推理中的其他声明相冲突。
如Fig 6 (b) 所示,只利用OC目标训练的GenRM,其F1、F4和F5类型的错误模式会大幅度提升,其中F4单边赞扬从训练前的17.8%提升到62%(+44.2%),这也说明了只用OC目标训练的GenRM是先得到判断再进行解释理由,而不是先解释理由再得到判断,因此会倾向于做出单边答案的赞扬而忽略另一个答案。F1也大幅增加,说明模型更依赖答案浮于表面的线索。F5 不可证伪性也随之上升,显示出更多难以验证的模糊陈述。在引入了推理一致性的奖励信号后,这些被放大的缺陷急剧下降。F4 降至0.05%,几乎完全消除了单边论据。F1 回归接近预训练水平。F2、F3 和 F5 也降至接近零。总体而言,推理监督减少了浮于表面的启发式行为,促进了基于证据的真正比较性推理。
Reference
[1]. Wang, Binghai, Yantao Liu, Yuxuan Liu, Tianyi Tang, Shenzhi Wang, Chang Gao, Chujie Zheng et al. "Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models." arXiv preprint arXiv:2602.04649 (2026).
[2]. Wang, Zhilin, Jiaqi Zeng, Olivier Delalleau, Hoo-Chang Shin, Felipe Soares, Alexander Bukharin, Ellie Evans, Yi Dong, and Oleksii Kuchaiev. "HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages." arXiv preprint arXiv:2505.11475 (2025). Aka HelpSteer3.
[3]. Shao, Zhihong, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024." URL https://arxiv. org/abs/2402.03300 2, no. 3 (2024): 5.