相较于 SFT,强化学习能生成更强且更为精确定位的视觉表示,从而显著提升视觉编码器在多模态语言模型中的表现...
前言
好久不见,最近没怎么写博文。前阵子看到一篇文章,在讨论RL方法(本文用的是DPO)在MLLM训练中对视觉表征的重塑作用,简单做个笔记,希望对大伙儿有所帮助吧。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
- 关键词:视觉表征重塑、在MLLM中的RL
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
github page: https://fesianxu.github.io/
微信公众号:机器学习杂货铺3号店

多模态大模型(Multimodal Large Language Model, MLLM)通常由三部分构成:
- 视觉编码器,可以是CLIP、SigLIP、DINO等,采用的结构可以是ViT(当前主流),也可以是传统的CNN。
- 视觉连接器(Projector),作为桥梁连接视觉和文本语义,通常是简单的MLP结构(也是最常被采用的),或者Q-Former [2]、Perceiver Resampler [3]、D-abstractor[4] 等复杂结构。
- 底座LLM,如LLama、Qwen等。
通常的训练方式是多阶段的,总结来说:
- 第一阶段无非是先用图文对数据,在固定住底座LLM和视觉编码器的参数前提下,先训练视觉连接器,提供基本的视觉-语义桥联能力;
- 第二阶段则采用高质量的对话数据/指令遵循数据等进行SFT,放开底座LLM的参数,同时优化视觉编码器(可选)、视觉连接器和底座LLM的参数。当然如果做细致的话,第二阶段还可以按照用的数据质量,类别等继续拆分更多的子阶段。
- 第三阶段,则会采用强化学习的方式进行训练(会更新所有模型参数),在本文想要介绍的文献 [1] 中的工作中,作者正是讨论在强化学习背景下,DPO对比SFT,在视觉特征上的优化特性。
让我们回忆下DPO,我们知道SFT是最大似然估计,在给定输入的情况下,尽可能地拟合优选响应。损失函数如公式(1)所示: 
其中的后训练数据集为
以往已经有一些研究表明采用DPO的方式能对MLLM的效果带来收益,本文也进行了SFT vs DPO效果的对比,如Fig 2所示,无论是在视觉编码器或是底座LLM上的模型尺寸缩放的情况下,DPO都能在强视觉相关的VQA任务上持续超越SFT的效果。
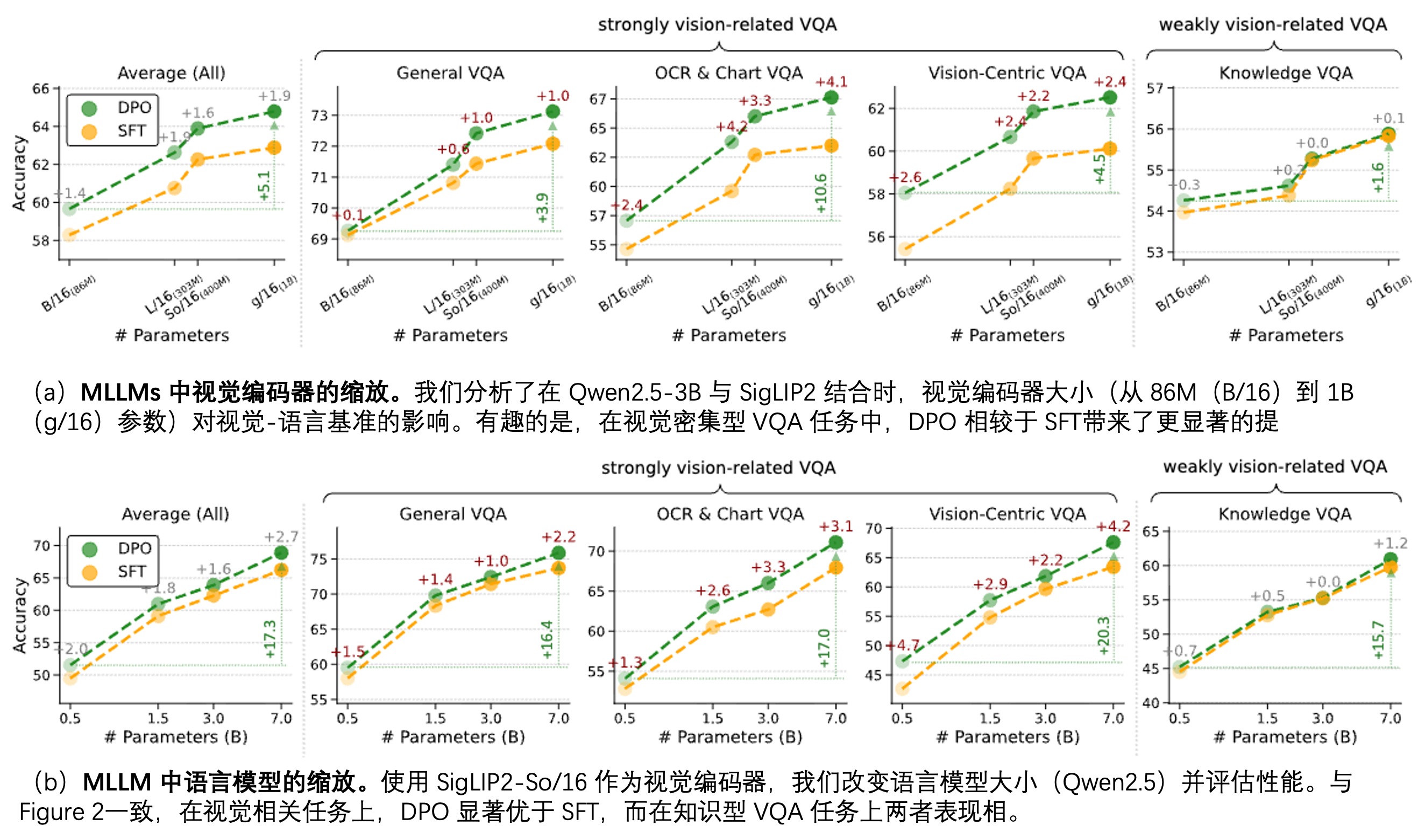
然而在视觉特征层面,究竟DPO在视觉特征优化上带来了何种收益,却仍然是一个空白。作者尝试用Grad-CAM的方法,对DPO和SFT情况下对图片的梯度情况进行可视化,从而探究图片中何种关键信息被检测出来。如Fig 3所示,作者发现采用了DPO方法训练得到的模型,其Grad-CAM图会更精确聚焦在语义相关的区域,对无关语义部分的『噪声』关注程度则明显减少了。因此作者猜测,采用DPO的方式训练的MLLM,其视觉表征会变得更为细粒度敏感,而说到细粒度的视觉任务,则可以考虑选择一个稠密的视觉任务,去考察采用了DPO训练后的MLLM的视觉特征的特性。

说到稠密视觉任务,不妨就用语义分割任务,理论上在精准定位的能力上会有所提升。作者用DPO训练后的MLLM视觉编码器,将其参数固定后,新增了两层MLP将其训练为一个patch级别的分类器,以进行分割任务,并且发现DPO微调给patch召回率提升了1.08%。从可视化图看,如Fig 4所示,也能发现出现了类似Fig 3的效果,经过 DPO 训练的视觉编码器生成的分割图更加准确,与真实值的一致性更高。

以上,作者指出采用DPO对MLLM进行全参数训练的情况下,训练出来的视觉编码器能够具有更高的性能,即便只用视觉编码器做线性探测(Linear Probe),在ImageNet分类任务上也能获得普遍的性能提升,在视觉定位上的能力也有所提升。这大概是由于DPO进行显式的正负样本对比,带来的精准定位能力提升。此外,以上提到的视觉编码器用的是SigLIP1和SigLIP2,但作者也在CLIP、MAE、DINO等视觉编码器上做了实验,也能发现相似的性能提升。作者将这种采用MLLM,通过DPO的方式后训练视觉编码器的方式,称之为偏好指引下的视觉特征最优化(Preference-Instructed Vision OpTimization, PIVOT)。
总的来说,作者有以下几个结论:
发现1: 增加MLLM中视觉编码器的模型尺寸,对于需要细粒度视觉理解的任务尤为重要,见Fig 2 (a) 。
发现2: DPO能使MLLM获得优于SFT的性能,尤其是在高度依赖视觉的任务上,见Fig 2。
发现3: MLLM的训练不仅能适配语言模型,还能重塑视觉表征,而这些表征决定了模型如何感知图像。
发现4: DPO能够引导视觉编码器对视觉信息进行更细粒度的分析,从而提升其视觉定位能力。
发现5: 视觉编码器能从更大规模的LLM中获益,因为在MLLM内部,更大的LLM能为视觉表征提供信息更丰富的梯度信号。
发现6: 现有的视觉模型在MLLM中仍具有巨大的提升潜力,而这种潜力可以通过 PIVOT 方法得以释放。
不过,作者虽然在标题中指出是『RL』,但其实文中采用的最主要的方式还停留在DPO上,这是一种更偏向于对比式学习的方式,和我们理解的PPO、GRPO等强化学习方法还有所差异,在arxiv上的最新更新内容上,虽然看到作者也有对GRPO的内容有所补充,但是整体分析还是较少,期待后续能在GRPO上进行更多特性的分析。
Reference
[1]. Song, Junha, Sangdoo Yun, Dongyoon Han, Jaegul Choo, and Byeongho Heo. "RL makes MLLMs see better than SFT." arXiv preprint arXiv:2510.16333 (2025). Aka PIVOT
[2]. Li, Junnan, Dongxu Li, Silvio Savarese, and Steven Hoi. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." In International conference on machine learning, pp. 19730-19742. PMLR, 2023. Aka BLIP-2
[3]. Alayrac, Jean-Baptiste, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc et al. "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems 35 (2022): 23716-23736. aka Flamingo
[4]. Cha, Junbum, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. "Honeybee: Locality-enhanced projector for multimodal llm." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13817-13827. 2024.